Интеграция Apache Airflow с инструментами CI/CD является одной из лучших практик современной дата-инженерии, о чем мы недавно писали. Читайте далее, зачем нужно управлять кодом DAG с помощью популярных систем управления версиями и как это сделать на примере GitLab CI/CD. Сложности управления DAG в разных средах AirFlow Apache Airflow считается наиболее...
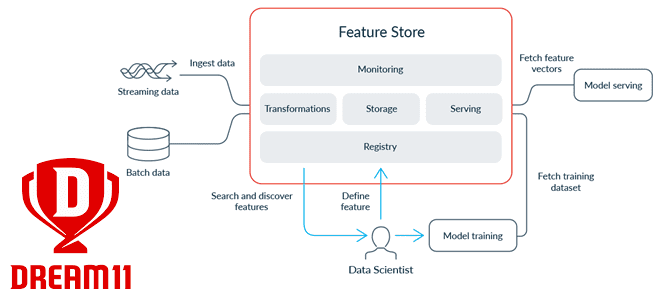
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka. Что такое хранилище фичей и зачем это Dream11...
Зачем нужен мониторинг ML-систем в production, чем он отличается от простого отслеживания метрик ПО и при чем здесь MLOps. Как настроить телеметрию ML-приложений в New Relic: 5 простых шагов для специалистов по Machine Learning и дата-инженеров. Зачем нужен мониторинг ML-систем и при чем здесь MLOps В реальных системах машинного обучения...

В рамках практического обучения аналитиков данных и специалистов по Data Science реальным задачам современных бизнес-приложений, сегодня разберем актуальную и острую для многих стран тему по промышленному использованию природных ресурсов в современных непростых условиях. Строим граф европейской газотранспортной системы в Neo4j. Создание графа европейской газотранспортной системы в Neo4j Российский природный газ...

Школа Больших Данных продолжает серию митапов по Apache Spark. Третий митап состоится 24 мая в 17:00 МСК по теме «Spark или pandas? Spark и pandas!». Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов...
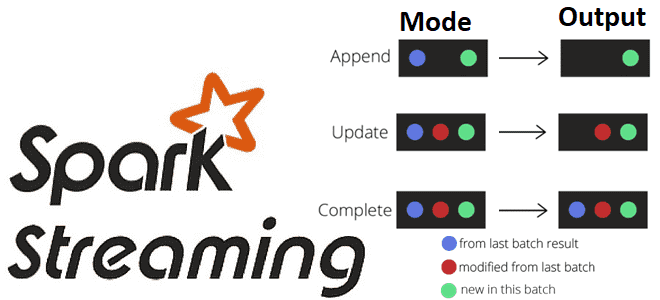
Какие бывают режимы вывода в структурированной потоковой передаче Spark, чем они отличаются и как их использовать на практике: разбираемся на практическом примере. Краткий ликбез по output modes в Apache Spark Structured Streaming для обучения дата-инженеров и разработчиков распределенных приложений. Что такое режимы вывода в Apache Spark Structured Streaming Apache Spark...
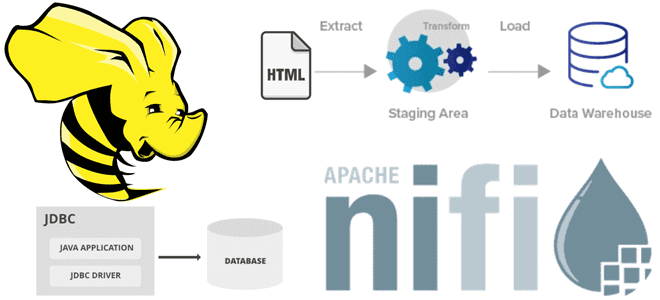
В этой статье для дата-инженеров рассмотрим пример интеграции Apache NiFi c Hive в рамках ETL-конвейера потокового веб-скрейпинга, который будет получать данные с веб-страницы практически без кода, обрабатывать их и загружать в таблицу NoSQL-СУБД в реальном времени. Постановка задачи: ETL-процесс веб-скрейпинга В реальной жизни задача считать данные с веб-сайта для последующей...
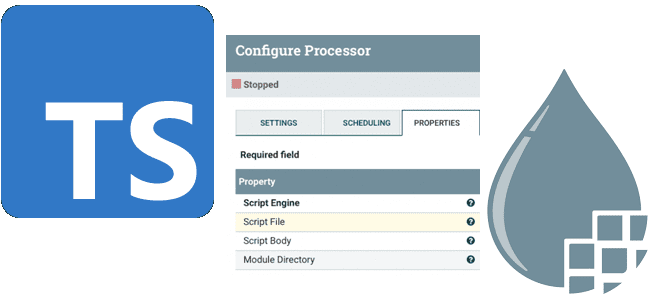
Сегодня рассмотрим, что такое процессор ExecuteScript в Apache NiFi, как с его помощью реализовать собственную бизнес-логику обработки потоков данных на мульти-парадигмальном языке программирования TypeScript и чем это будет лучше кода на JavaScript. Краткий ликбез для дата-инженеров. Процессор ExecuteScript в Apache NiFi Напомним, за обработку потоков данных в Apache NiFi отвечают...
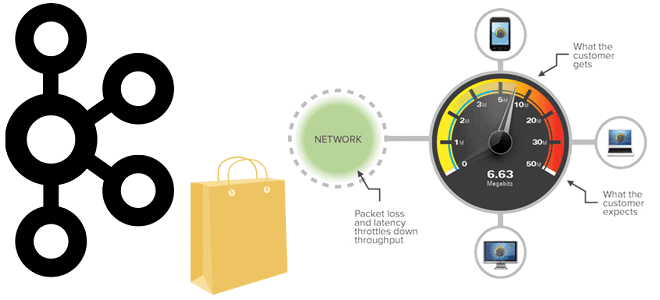
Пропускная способность информационной системы на базе Apache Kafka говорит о том, сколько данных могут быть обработаны за определенный период времени. Несмотря на потоковую передачу событий, здесь работает классический закон обратной зависимости скорости обработки данных от их объема. Разбираемся, как найти баланс между производительностью и задержкой. Еще раз о пропускной способности...

В продолжение недавней статьи для дата-инженеров по эффективной работе с Apache AirFlow, сегодня разберем еще несколько рекомендаций от компании Astronomer, которая продвигает и коммерциализирует этот ETL-оркестратор. Чем полезна микрооркестрация с несколькими средами AirFlow, как обеспечить повторное использование и воспроизводимость, зачем нужна интеграция с инструментами и процессами CI/CD. Микрооркестрация с множеством...