 1086
1086 
Содержание
В этой статье для дата-инженеров рассмотрим пример интеграции Apache NiFi c Hive в рамках ETL-конвейера потокового веб-скрейпинга, который будет получать данные с веб-страницы практически без кода, обрабатывать их и загружать в таблицу NoSQL-СУБД в реальном времени.
Постановка задачи: ETL-процесс веб-скрейпинга
В реальной жизни задача считать данные с веб-сайта для последующей обработки и анализа встречается очень часто. Она называется веб-скрейпинг (web scraping) и представляет собой автоматизированный процесс извлечения и сбора данных с сайтов, включая извлечение и обработку базового HTML-кода с использованием CSS-селекторов. Извлеченные и преобразованные данные обычно сохраняются в базе. В качестве такого хранилища может выступать Apache Hive – средство стека SQL-on-Hadoop, которое позволяет обращаться к данные, хранящимся в распределенной файловой системе Hadoop HDFS с помощью стандартного языка SQL-запросов.
Реализовать весь этот процесс можно с помощью Apache NiFi – популярного ETL-инструмента потоковой дата-инженерии, который предоставляет наглядный веб-интерфейс для проектирования конвейеров обработки потока данных в режиме реального времени. Он также поддерживает мощные и масштабируемые средства маршрутизации и преобразования данных, которые можно запускать на одном сервере или в кластерном режиме на нескольких узлах.
Рабочий процесс NiFi состоит из готовых или самостоятельно написанных дата-инженером обработчиков — процессоров, которые могут обрабатывать, проверять, фильтровать, объединять, разделять или корректировать данные. Процессоры обмениваются друг с другом потоковыми файлами (FlowFile) через очереди с именами соединений. Контроллеры FlowFile помогают управлять ресурсами между всеми этими компонентами.
Таким образом, процесс веб-скрейпинга в Apache NiFi сводится к следующему ETL-конвейеру из нескольких процессоров, каждый из которых выполняет свои задачи на разных этапах обработки данных:
- сбор данных с веб-страницы через обращение по API (InvokeHTTP);
- фильтрация (GetHTMLElement, ExtractEndPoints, RouteOnAttribute, QueryRecord);
- преобразование (ReplaceHeaders, ConvertJSONToSQL);
- загрузка (PutHiveQL);
- логирование (LogAttribute).
Каждый процессор подключается через различные соединения отношений и запускается в случае успеха до тех пор, пока данные не будут загружены в Hive-таблицу. Весь поток планируется запускать ежедневно. Чтобы понять, как это работает, далее рассмотрим каждый шаг более подробно.
Реализация конвейера в процессорах Apache NiFi
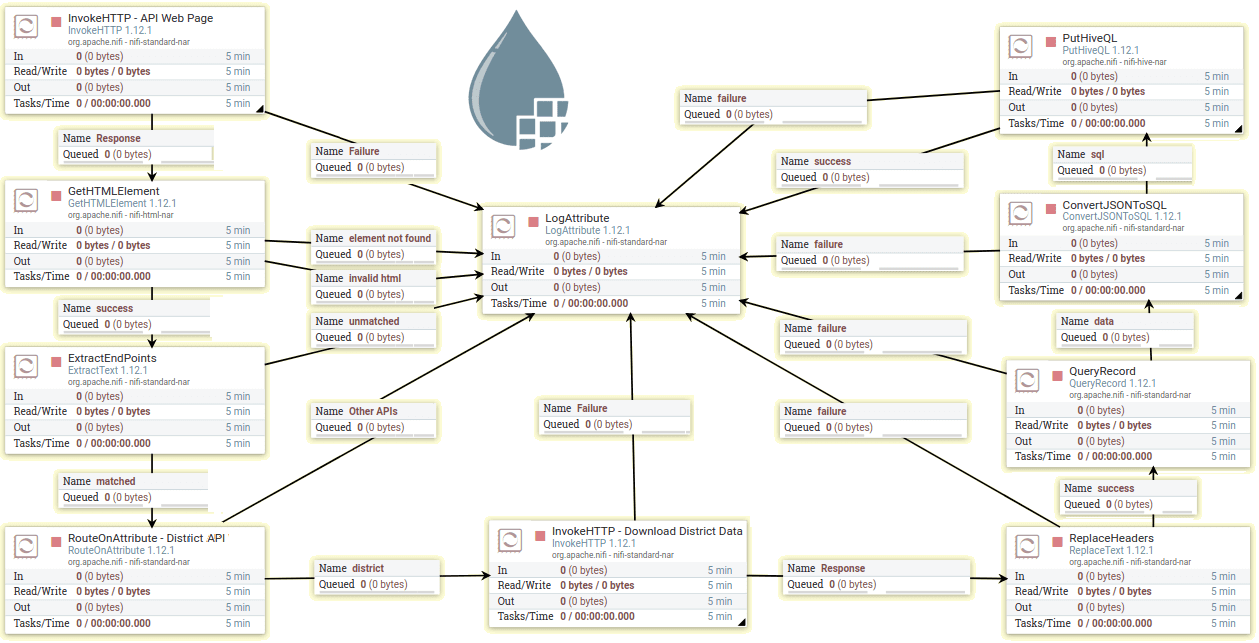
Сперва необходимо получить HTML-документ, используя удаленный URL-адрес. Поток начинается с процессора InvokeHTTP, который отправляет HTTP-запрос GET на URL-адрес нужного веб-сайта и возвращает HTML-страницу в очереди ответов для дальнейшей проверки. Полученные данные формируют потоковый файл. Процессор InvokeHTTP также можно использовать для вызова нескольких методов HTTP (GET, PUT, POST или PATCH).
Далее процессор GETHTMLElement выбирает из FlowFile строки HTML-таблицы, где все конечные точки перечислены внутри тегов привязки, используя CSS-селекторы, идентифицирующие такие элементы как строки, столбцы и ссылки: tr > td > a. После успешного выполнения предыдущего шага процессор ExtractText оценивает регулярные выражения по содержимому FlowFile для извлечения URL-адресов, которые затем назначаются атрибуту FlowFile с именем data_url.
Далее обработчик RouteOnAttribute отфильтровывает API для получения нужной информации и игнорирует другие API, используя внутренний язык выражений Apache NiFi. Затем процессор InvokeHTTP загружает данные, используя извлеченную конечную точку API, назначенную атрибуту data_url, заключенному в фигурные скобки. Данные ответа будут в формате CSV.
На этапе преобразования и фильтрации CSV-набора данных заголовок ответа изменяется на нижний регистр с помощью процессора ReplaceText со стратегией замены Literal, а имя первого поля изменяется с date на recorded_date, чтобы избежать использования зарезервированных ключевых слов базы данных.
Если данные обновляются ежедневно, следует извлекать их только за предыдущий день с помощью процессора QueryRecord, который также преобразует данные потокового файла из CSV в JSON с помощью служб контроллера CSVReader и JsonRecordSetWriter. Также QueryRecord выполняет следующий запрос, чтобы получить данные за предыдущий день из FlowFile и передать их следующему процессору:
select * from FlowFile where recorded_date='${now():toNumber():minus(86400000):format('yyyy-MM-dd')}'
Далее следует установить пул соединений JDBC для Hive и создать таблицу, куда будут записаны данные FlowFile. Для этого следует настроить JDBC-драйвер Hive для потока NiFi с помощью HiveConnectionPool, который предоставляет службу пула подключений к базе данных для Apache Hive. Соединения могут быть запрошены из пула и возвращены после использования. В настройках HiveConnectionPool следует задать все необходимые значения настроечных параметров: URL-адрес подключения к базе данных и учетные данные. Свойство Ресурсы конфигурации Hive предполагает путь к файлу конфигурации hive-site.xml.
Теперь нужна пустая таблица для загрузки данных из потока NiFi. Создать такую таблицу поможет следующий DDL-запрос SQL:
CREATE TABLE IF NOT EXISTS demo.districts (recorded_date string, state string, district string, confirmed string, recovered string, deceased string, other string, tested string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
В эту созданную Hive-таблицу можно загрузить данные потокового файла. На этом шаге FlowFile в формате JSON преобразуется в оператор SQL с помощью процессора ConvertJSONToSQL, чтобы предоставить SQL-запрос в качестве выходного потокового файла. Можно настроить HiveConnectinPool для свойства JDBC Connection Pool вместе с именем таблицы и типом инструкции перед запуском процессора. В этом случае оператор будет типа вставки, поскольку нужно загрузить данные в таблицу. При подготовке команды SQL свойство префикса атрибута параметра должно иметь значение hiveql, чтобы следующий процессор смог его идентифицировать без ошибок.
Далее в случае успеха процессор PutHiveQL выполняет входную SQL-команду и загружает данные в Hive-таблицу. Успех этого процессора означает конец рассматриваемого ETL-процесса. Можно запланировать запуск всего потока в любое время, используя различные стратегии планирования NiFi, о чем мы поговорим в следующий раз. Например, настроить первый процессор InvokeHTTP, который является инициатором этого потока, на ежедневное выполнение в 2 часа ночи.
Чтобы учитывать успех или сбой работы каждого процессора, все они направлены на процессор LogAttribute с очередью неудач/успехов, которая записывает состояние и информацию обо всех используемых атрибутах в файл logs/nifi-app.log. Проверяя этот файл, дата-инженер может отладить и исправить проблему в случае сбоя. Дополнительно возможно еще больше расширить его, настроив поток для сбора и уведомления по электронной почте сведений из логов ошибок с помощью Apache Kafka.
Также можно поработать с несколькими наборами данных с различными комбинациями различных процессоров/контроллеров как часть потока. К примеру, в рамках веб-скрейпинга можно собрать данные со страницы со списком продуктов на нескольких ecommerce-сайтах, чтобы сравнить товары и цены, извлекать обзоры с отзывами, чтобы использовать их в качестве рекомендации для пользователей.
Еще пара средств интеграции с Hive
В заключение отметим, что интеграция Apache NiFi c Hive также может быть реализована с помощью коммерческого JDBC-драйвера CData. С этим средством NiFi может работать с данными Hive в реальном времени, позволяя подключиться и запросить данные Hive из Apache NiFi Flow. JDBC-драйвер CData со встроенной оптимизированной обработкой данных обеспечивает высокую производительность для взаимодействия с оперативными данными NoSQL-хранилища. При отправке сложных SQL-запросов к Hive, драйвер отправляет поддерживаемые SQL-операции, (фильтры, агрегации и пр.), непосредственно в SQL-on-Hadoop. При этом драйвер использует встроенный движок выполнения структурированных запросов для обработки неподдерживаемых операций на стороне клиента, типа оконных функций и соединений (JOIN). Его встроенный динамический запрос метаданных позволяет работать с данными Hive и анализировать их, используя собственные типы данных. Пример использования JDBC-драйвера с Hive смотрите здесь.
Также для связи NiFi c Hive можно использовать следующие процессоры потокового ETL-инструмента:
- процессор PutHiveStreaming, который отправляет данные потокового файла в Hive-таблицу. При этом файл входящего потока должен быть в формате AVRO, а сама таблица уже должна существовать в Hive. Значения раздела извлекаются из записи AVRO на основе имен столбцов раздела, указанных в процессоре. Если для этого процессора настроено несколько параллельных задач, только одна таблица может быть записана в любой момент одним потоком. Дополнительные задачи, предназначенные для записи в ту же таблицу, будут приостановлены, ожидая, пока текущая задача завершит запись в Hive-таблицу.
- процессор SelectHiveQL позволяет выполнить предоставленный SELECT-запрос HiveQL для подключения к базе данных Hive. Результат запроса будет преобразован в формат AVRO или CSV. Используется потоковая передача, поэтому поддерживаются произвольно большие наборы результатов. Этот процессор можно запланировать для запуска по таймеру или cron-выражению, используя стандартные методы планирования. Также процессор SelectHiveQL может быть запущен входящим FlowFile. Если он инициируется входящим потоковым файлом, его атрибуты будут доступны при оценке запроса на выборку. В частности, атрибут потокового файла selecthiveql.row.count указывает, сколько строк было выбрано.
Аналогичный кейс передачи данных из MySQL в Apache Hive мы разбираем здесь. А о том, как связать Hive с другой системой потоковой обработки данных, Apache Kafka, читайте в нашей новой статье.
Больше практических приемов по администрированию и эксплуатации Apache NiFi с Hive для построения эффективных ETL-конвейеров с целью аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://www.velotio.com/engineering-blog/building-an-etl-workflow-using-apache-nifi-and-hive
- https://www.cdata.com/kb/tech/hive-jdbc-apache-nifi.rst
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-hive-nar/1.5.0/org.apache.nifi.processors.hive.PutHiveStreaming/
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-hive-nar/1.5.0/org.apache.nifi.dbcp.hive.HiveConnectionPool/index/
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-hive-nar/1.5.0/org.apache.nifi.processors.hive.SelectHiveQL/

