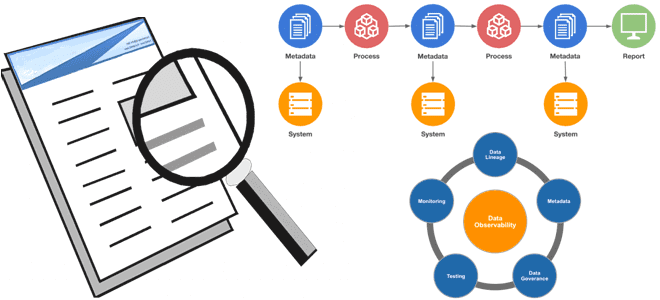
Сегодня рассмотрим, почему наблюдаемость данных так важная для проектов Big Data, какие компоненты обеспечивают ценную информацию о качестве и надежности данных, чем это похоже на DataOps, а также как эти идеи реализовать на практике с использованием популярных инструментов современной дата-инженерии. Почему важна наблюдаемость данных Цифровизация предполагает управление на основе качественных...
Специально для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink, рассмотрим наиболее важные системные показатели, а также инструменты мониторинга этих метрик. Мониторинг Flink-приложений: особенности и метрики В общем случае мониторинг приложений гарантирует, что ПО обрабатывает данные и выполняет запрошенные действия ожидаемым образом. Непрерывное отслеживание...

Для обучения дата-инженеров и аналитиков данных, сегодня рассмотрим приемы оптимизации SQL-запросов в Apache Hive, выполняемых движком Tez. Каким образом Tez рассчитывает оптимальное количество редукторов, зачем включать индексацию фильтров, как статистика таблицы помогает улучшить план выполнения запросов и что за конфигурации нужно менять. 3 движка выполнения запросов в Apache Hive Напомним,...

10 июня 2022 года вышел свежий релиз популярной MPP-СУБД. Разбираемся с улучшениями функциональных возможностей и решенными проблемами в Greenplum версии 6.21.0. Самое важное для администратора кластера и дата-инженера. 4 новых модуля свежего релиза В Greenplum 6.21.0 теперь поддерживается команда SET TRANSACTION SNAPSHOT, которая устанавливает характеристики текущей транзакции, не влияя на...
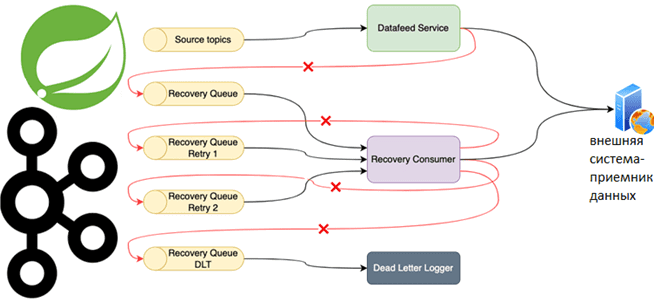
Специально для обучения разработчиков распределенных приложений и дата-инженеров, рассмотрим практический пример использования возможностей фреймворка Spring для управления повторными попытками отправки сообщений потребителям из топика Apache Kafka. Повторные попытки отправки сообщений и Spring для Apache Kafka Довольно часто Kafka-приложения требуют высокой надежности обработки сообщений. Например, в финтех- или медтех-проектах, а также...

15 июня 2022 года вышел новый выпуск Apache NiFi. Разбираем, что нового и полезного в релизе 1.16.3: исправленные ошибки, а также улучшения, важные для дата-инженера и администратора кластера Apache NiFi. 7 исправленных ошибок в релизе 1.16.3 Apache NiFi – один из самых популярных и востребованных инструментов современного дата-инженера. Эта платформа...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое связность в графе, зачем вычислять компоненты связности и как это сделать для ориентированных графов. Продемонстрируем все вычисления с помощью методов Python-библиотеки Networkx в Google Colab. Основы теории графов и применения Networkx в Google...
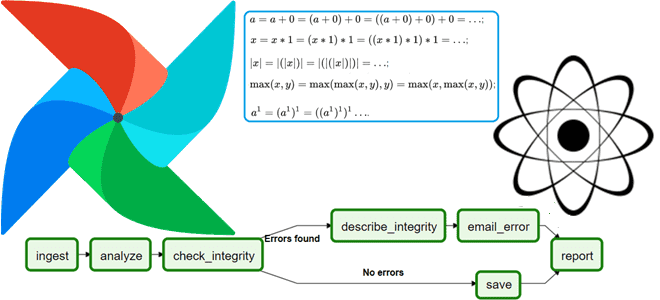
В этой статье для обучения дата-инженеров рассмотрим практическое применение 2-х важных принципов обработки данных: атомарность и идемпотентность задач в Apache Airflow. Читайте далее, как применить их к своим ETL-конвейерам, чтобы получить корректные и согласованные результаты. Все или ничего: атомарность задач Будучи популярным инструментом дата-инженерии, Apache Airflow снижает порог входа в...

Что такое SparkListener, какие встроенные слушатели бывают в Apache Spark, как написать собственный перехватчик событий и зачем это нужно разработчику распределенного приложения. Также рассмотрим, как реализовать свой слушатель для приложения на PySpark и зачем включать уровень логирования INFO для SparkContext. Что такое слушатель Spark Apache Spark позволяет быстро обрабатывать большие...
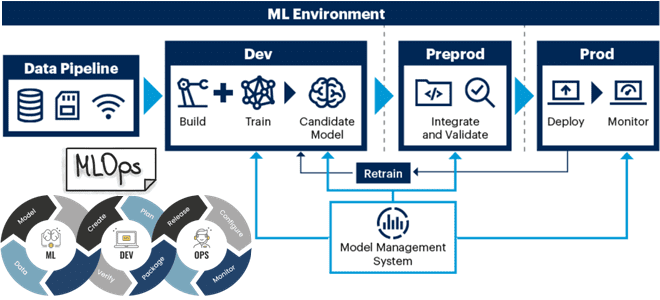
Что и насколько часто меняется в системах машинного обучения, почему необходимо отслеживать эти изменения и как MLOps помогает справиться с управлением ML-моделями, данными, кодом и инфраструктурой развертывания. Почему стек технологий MLOps такой разношерстный и какие инструменты выбирать для практического использования. MLOps для решения дрейфа данных и других проблем ML-систем Машинное...