 1352
1352 
В этой статье для обучения дата-инженеров рассмотрим практическое применение 2-х важных принципов обработки данных: атомарность и идемпотентность задач в Apache Airflow. Читайте далее, как применить их к своим ETL-конвейерам, чтобы получить корректные и согласованные результаты.
Все или ничего: атомарность задач
Будучи популярным инструментом дата-инженерии, Apache Airflow снижает порог входа в профессию, автоматизируя выполнение рутинных операций в пакетных конвейерах обработки данных. Однако, наличие готовых операторов Apache Airflow не избавляет пользователя писать код на Python в соответствии с лучшими практиками разработки ПО, чтобы получить правильные и согласованные результаты. В частности, к таким универсальным концепциям обработки данных относятся понятия атомарности и идемпотентности.
Понятие атомарности чаще всего применяется в контексте разработки требований к ПО и СУБД. В первом случае речь идет о том, что каждое требование должно быть самостоятельным и неделимым, описывая одну и только одну вещь. В случае СУБД атомарность относится к обработке транзакций, является свойством ACID и считается неделимой, несокращаемой серией операций, которые выполняются все разом и полностью или не выполняются вообще.
С точки зрения дата-инженерии атомарность в Apache Airflow означает, что задача должна быть определена таким образом, чтобы обеспечить успешный корректный результат или выдать полный отказ, не влияя на общее состояние системы.
Чтобы проиллюстрировать, как это работает, рассмотрим практический пример простого ETL-конвейера. Предположим, необходимо извлечь данные из CSV-файла, применить к ним некоторые преобразования и записать результат в базу данных. Это можно реализовать двумя способами:
- неатомарно – в рамках одной задачи извлекаем данные построчно, сразу применяем преобразование и загружаем результат в базу;
- атомарно – создадим 3 задачи на извлечение, преобразование и загрузку данных соответственно.
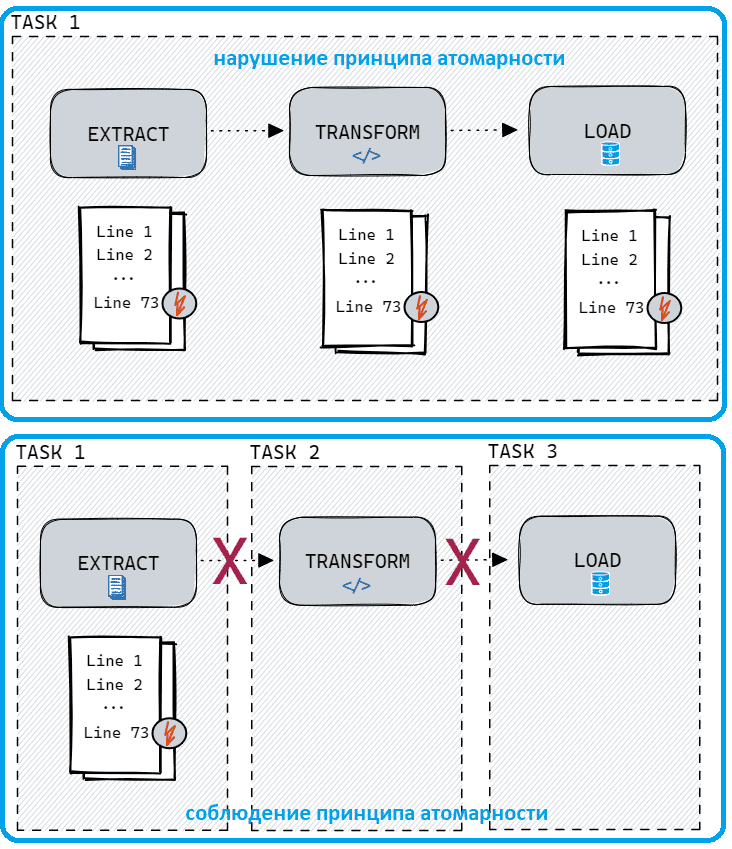
Сравним возможности и риски обоих подходов. В первом случае, если некоторые строки повреждены, выполнение единой задачи прекратится на полпути. В результате получится только фрагмент обработанных данных, где часть строк будет уже вставлена в итоговое место назначения, а некоторые строки будут просто отсутствовать. Отладка и повторный запуск этой задачи станет непростым делом, если необходимо избежать дублирования.
Предотвратить это позволит второй подход, с разделением задач по операциям согласно принципу единой ответственности, который широко известен и активно используется в объектно-ориентированном программировании и проектировании микросервисов. Однако, как и любое правило, этот простой и эффективный принцип имеет определенные исключения и особенности применения. В частности, в дата-инженерии некоторые операции настолько тесно связаны, что лучше всего объединить их в единую задачу. Например, аутентификация в API перед выполнением запроса.
В прочем, в общем случае создание атомарных задач Airflow позволяет конвейеру восстанавливаться после сбоя и повторно запускать только неудачные и последующие задачи. Атомарность обеспечивает более простые в сопровождении и прозрачные рабочие процессы без скрытых зависимостей и побочных эффектов. На практике большинство готовых операторов Airflow спроектированы атомарно и могут использоваться «из коробки». Но с гибкими типами операторов типа Bash или Python, дата-инженеру следует быть более осторожным и внимательным.
Идемпотентность задач в AirFlow
Концепция идемпотентности связана с идеей атомарности и описывает свойство определенных операций в математике и информатике возвращать один и тот же результат при повторных запусках. Идемпотентные операции можно применять несколько раз и каждый раз получать один и тот же выход. Например, в математике идемпотентными операциями являются сложение с нулём, умножение на единицу, взятие модуля числа, выбор максимального значения, вычисление наибольшего общего делителя, возведение в степень единицы. В информатике идемпотентными являются GET-запросы в протоколе HTTP: сервер возвращает идентичные ответы на одни и те же GET-запросы, если сам ресурс не изменился. Это позволяет корректно кэшировать ответы, снижая нагрузку на сеть.
Для Airflow цепочка задач DAG считается идемпотентной, если повторный запуск одного и того же DAG Run с одними и теми же входными данными дает тот же эффект, что и его однократный запуск. Этого можно достичь, спроектировав каждую отдельную задачу в вашей DAG так, чтобы она была идемпотентной. Другими словами, если повторный запуск задачи без изменения входных данных дает тот же результат, ее можно считать идемпотентной. Разработка идемпотентных DAG и задач сокращает время восстановления после сбоев и предотвращает потерю данных.
Чтобы понять, как это работает, снова рассмотрим практический пример из дата-инженерии. Предположим, нужно получить данные из базы за определенный день и записать результаты в CSV-файл. Повторное выполнение этой задачи в тот же день должно перезаписать существующий файл, выдавая один и тот же результат при каждом выполнении. Обычно задачи на запись должны проверять существующие данные, перезаписывать или использовать операции UPSERT для соответствия правилам идемпотентности.
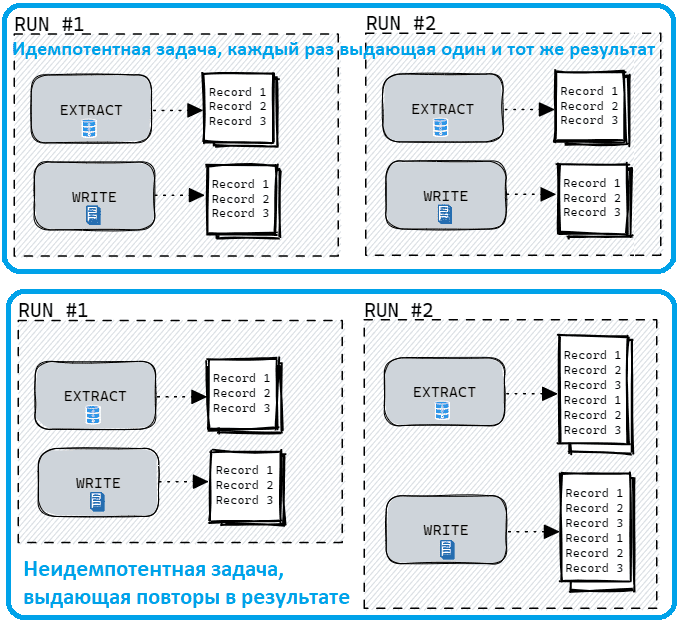
На практике реализовать принцип идемпотентности поможет использование шаблонных полей в Airflow, чтобы извлекать значения в DAG через переменные среды и шаблоны Jinja — текстового шаблонизатора для Python. По сравнению с использованием функций Python использование шаблонных полей помогает поддерживать идемпотентность пользовательских DAG и гарантирует, что функции не выполняются при каждом такте планировщика. А для некоторых сценариев, таких как инкрементная фильтрация записей идемпотентность DAG позволяет добиться корректных результатов. Например, в DAG, который выполняется каждый час, каждый запуск должен обрабатывать только записи за эти 60 минут, а не весь набор данных. Когда результаты каждого запуска DAG представляют лишь небольшую часть общего набора данных, сбой в одном подмножестве данных не помешает успешному завершению остальных запусков DAG. И если DAG являются идемпотентными, дата-инженер может повторно запустить конвейер обработки только для тех данных, где произошел сбой, а не для повторной обработки всего датасета.
Реализовать такую идемпотентность можно двумя способами:
- дата последнего изменения, когда каждая запись в исходной системе имеет столбец со временной отметкой последнего изменения записи. Запуск DAG ищет записи, которые были обновлены в течение определенных дат из этого столбца. В нашем примере с ежечасным запуском DAG он будет обрабатывать записи, которые попадают в период между началом и концом каждого часа. Если какой-либо из запусков завершится неудачно, это не повлияет на другие запуски.
- последовательные идентификаторы записей. Если дата последнего изменения недоступна, для добавочных загрузок можно использовать последовательность или инкрементный идентификатор. Эта отлично работает, когда исходные записи только добавляются и никогда не обновляются.
Читайте в нашей новой статье, как организовать условную логику в DAG с помощью операторов Apache AirFlow. А освоить все тонкости администрирования и эксплуатации Apache AirFlow для эффективной организации ETL/ELT-процессов в аналитике больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

