 1159
1159 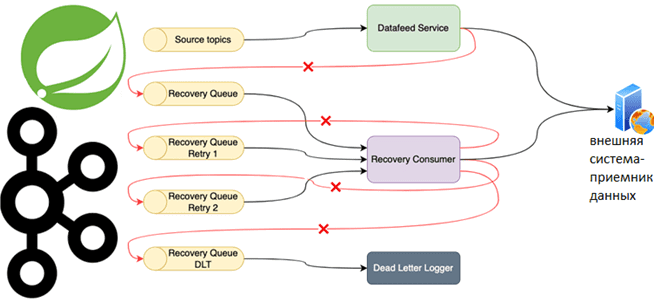
Содержание
Специально для обучения разработчиков распределенных приложений и дата-инженеров, рассмотрим практический пример использования возможностей фреймворка Spring для управления повторными попытками отправки сообщений потребителям из топика Apache Kafka.
Повторные попытки отправки сообщений и Spring для Apache Kafka
Довольно часто Kafka-приложения требуют высокой надежности обработки сообщений. Например, в финтех- или медтех-проектах, а также системах интернета вещей и платформах информационной безопасности. Например, данные о сетевом трафике клиентов, угрозах, приложениях и устройствах пользователей в режиме реального времени интегрируются в топики Apache Kafka, откуда потом извлекаются, обогащаются и отправляются на настроенные конечные точки систем-приемников. Доступность сторонних систем-приемников зависит от внешней инфраструктуры, а сеть передачи данных может быть ненадежной. При недоступности приемника или невозможности внешней системы обработать запрос потока данных, сообщения просто теряются.
В Apache Kafka потерянные сообщения попадают в соответствующую очередь или топик недоставленных сообщений (Dead letter queue/topic, DLT). Поэтому для повторной отправки сообщений получателю следует работать именно с этим топиком. Рассмотрим, как это сделать, используя популярный open-source фреймворк разработки Java-приложений Spring. Он позволяет реализовать наиболее популярные элементы типовых комплексных приложений: от управления транзакциями до работы с сообщениями. Проект Spring для Apache Kafka применяет основные концепции фреймворка Spring к разработке решений для обмена сообщениями, предоставляя соответствующие высокоуровневые абстракции и шаблоны.
Spring Kafka предоставляет функцию повторной попытки с помощью шаблона RetryTemplate с RetryingMessageListenerAdapter или, в последних версиях, путем настройки обработчика ошибок. Например, чтобы настроить топик повторных попыток и DLT для аннотированного метода @KafkaListener, разработчику нужно просто добавить к нему аннотацию @RetryableTopic, и Spring для Apache Kafka загрузит все необходимые топики и потребителей с конфигурациями по умолчанию:
@RetryableTopic(kafkaTemplate = "myRetryableTopicKafkaTemplate")
@KafkaListener(topics = "my-annotated-topic", groupId = "myGroupId")
public void processMessage(MyPojo message) {
// ... message processing
}
Для обработки сообщений DLT можно указать метод в том же классе, добавив к нему аннотацию @DltHandler. Если метод DltHandler не указан, создается потребитель по умолчанию, который регистрирует только потребление.
@DltHandler
public void processMessage(MyPojo message) {
// ... message processing, persistence, etc
}
Важно помнить, что без указания имени шаблона Kafka (kafkaTemplate), будет найден bean-компонент с именем retryTopicDefaultKafkaTemplate. Если bean-компонент не найден, генерируется исключение. В Spring бины (bean) − это классы, созданием экземпляров которых и установкой в них зависимостей управляет контейнер фреймворка. Бины предназначены для реализации бизнес-логики приложения. Bean воплощает паттерн проектирования «одиночка» (singleton), т.е. в некотором блоке приложения существует только один экземпляр данного класса. Поэтому, если бин содержит изменяемые данные в полях, т.е. имеет состояние, то обращение к таким данным необходимо синхронизировать. Возвращаясь к повторным попыткам отправки сообщений в Kafka с помощью Spring, отметим, что можно настроить поддержку неблокирующих повторных попыток, создав bean-компоненты RetryTopicConfiguration в аннотированном классе @Configuration.
@Bean
public RetryTopicConfiguration myRetryTopic(KafkaTemplate<String, Object> template) {
return RetryTopicConfigurationBuilder
.newInstance()
.create(template);
}
Это создаст топики повторных попыток и DLT, а также соответствующих потребителей для всех топиков в методах, аннотированных с помощью @KafkaListener, с использованием конфигураций по умолчанию. Экземпляр KafkaTemplate необходим для пересылки сообщений. Для более детального контроля над обработкой неблокирующих повторных попыток для каждого топика, можно предоставить более одного bean-компонента RetryTopicConfiguration.
Потребители топика повторных попыток и DLT будут назначены группе потребителей с идентификатором группы, который представляет собой комбинацию того, что указано в параметре groupId аннотации @KafkaListener с суффиксом топика. Если ничего не задано, все они будут принадлежать к одной и той же группе, а перебалансировка в топике повторной попытки вызовет ненужную перебалансировку в основном топике.
Если потребитель настроен с помощью ErrorHandlingDeserializer, для обработки исключений десериализации важно настроить KafkaTemplate и его продюсера с сериализатором, который может обрабатывать обычные объекты, а также необработанные значения byte[], возникающие в результате исключений десериализации. Общий тип значения шаблона должен быть Object. Один из методов заключается в использовании DelegatingByTypeSerializer:
@Bean
public ProducerFactory<String, Object> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfiguration(), new StringSerializer(),
new DelegatingByTypeSerializer(Map.of(byte[].class, new ByteArraySerializer(),
MyNormalObject.class, new JsonSerializer<Object>())));
}
@Bean
public KafkaTemplate<String, Object> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
Для одного и того же топика можно использовать несколько аннотаций @KafkaListener с ручным назначением разделов или без него вместе с неблокирующими повторными попытками. Но конфигурация топика при этом не меняется. Поэтому лучше использовать один bean-компонент RetryTopicConfiguration для настройки таких топиков. Если для одного и того же топика используется несколько аннотаций @RetryableTopic, все они должны иметь одинаковые значения, иначе одна из них будет применена ко всем слушателям этого топика, а значения других аннотаций будут проигнорированы.
Хотя такой подход к повторным попыткам сохраняет гарантии порядка доставки сообщений, повторная попытка и ожидание задержки повтора выполняется в приложении-потребителе Kafka. Каждый сбой блокирует обработку назначенных разделов топика, вызывая отставание потребителя, что неприемлемо для топиков с высокой пропускной способностью. Кроме того, это не решает проблему, когда сообщение Kafka не может быть обработано в течение длительного периода времени. Обойти это ограничение поможет возможность, появившаяся в Spring Kafka 2.7, о чем мы поговорим далее.
Неблокирующие повторные попытки
В Spring Kafka 2.7 появилась новая функция неблокирующих повторных попыток, которая использует дополнительные топики Kafka с повторными попытками, куда отправляются необработанные сообщения для последующей повторной доставки. Количество топиков и повторных попыток является произвольным, и для каждого можно настроить различную задержку. Однако, поскольку повторные попытки не блокируются, гарантии порядка сообщений Kafka больше невозможны.
Когда топик настроен на повторную попытку, а слушатель, обрабатывающий сообщение, выдает исключение, настроенный механизм восстановления после ошибок выполняет следующие шаги:
- вычисляет время, когда сообщение должно быть обработано снова;
- создает повторное сообщение как копию исходного с дополнительными заголовками (время выполнения сообщения, сведения об исключении и пр.);
- вычисляет следующий топик повтора и публикует в нем это сообщение;
- если количество попыток исчерпано, сообщение удаляется или отправляется в топик DLT, чтобы обработать его позже при необходимости.
Spring Kafka автоматически создает контейнеры слушателя сообщений для топиков повторных попыток и DLT. Эти контейнеры по умолчанию используют тот же слушатель сообщений и конфигурацию, что и основной топик. Слушатели обёрнуты в специальные адаптеры, реализующие отложенную обработку сообщений следующим образом:
- проверяется время выполнения входящего сообщения в KafkaBackoffAwareMessageListenerAdapter — если оно уже прошло, сообщение передается слушателю;
- если положенное время еще не наступило, адаптер заставляет диспетчер отсрочки PartitionPausingBackoffManager выдавать исключение KafkaBackoffException с информацией о том, насколько должна быть отложена обработка;
- смещение раздела сбрасывается, и потребитель Kafka приостанавливается на требуемый период времени;
- как только потребитель активизируется, сообщение доставляется снова.
Таким образом, при сбое отправки сообщения в конкретный приемник отправитель создает сообщение для восстановления и публикует его в разделе очереди восстановления. Сообщение содержит полную полезную нагрузку для отправки и идентификации системы-приемника. DLT-слушатель Kafka получает сообщение о сбое, и немедленно пытается выполнить повторную доставку. Если это не удается, сообщение передается в следующую очередь восстановления с возрастающей задержкой до тех пор, пока оно не будет успешно отправлено или не исчерпается количество попыток.
Самый простой способ настроить топик с повторами — использовать аннотацию @RetryableTopic в методе слушателя сообщений вместе с аннотацией @KafkaListener. В аннотации можно настроить большинство свойств повторных попыток: количество, автоматическое создание топика и стратегию отсрочки для расчета задержек доставки.
Альтернативой аннотации является создание bean-компонентов RetryTopicConfiguration, которые обеспечивают более точную настройку:
@Bean
public RetryTopicConfiguration recoveryQueueConfiguration(
@Qualifier(RecoveryQueueConfig.TEMPLATE) KafkaTemplate<String, RecoveryMessage> template,
@Qualifier(RecoveryQueueConfig.CONTAINER_FACTORY)
ConcurrentKafkaListenerContainerFactory<String, RecoveryMessage> containerFactory,
MessageRecoveryConfig messageRecoveryConfig) { return RetryTopicConfigurationBuilder.newInstance()
.includeTopic(RecoveryQueueConfig.TOPIC)
.suffixTopicsWithIndexValues()
.doNotAutoCreateRetryTopics()
.maxAttempts(messageRecoveryConfig.getAttempts())
.customBackoff(new IntervalBackOffPolicy(messageRecoveryConfig.getIntervals()))
.notRetryOn(MethodArgumentResolutionException.class)
.notRetryOn(MethodArgumentNotValidException.class)
.notRetryOn(DeserializationException.class)
.dltHandlerMethod(RecoveryQueueConfig.MESSAGE_LISTENER, "deadLetter")
.doNotRetryOnDltFailure()
.listenerFactory(containerFactory)
.create(template);
}
При этом разработчику по-прежнему приходилось создавать обязательные связанные с Kafka bean-компоненты, такие как продюсеры и потребители, а также шаблон Kafka для отправки сообщений в DLT и слушатель, который заботится об их фактической повторной доставке.
Практическое использование этого подхода может привести к следующим неожиданным проблемам:
- сообщения в топиках повторных попыток становятся намного больше исходных из-за добавления к ним заголовков, связанных с исключениями (трассировка стека исключения, полное доменное имя и сообщение). Поскольку это не настраивается, обойти это можно на уровне клиента Kafka, удалив заголовки исключений в перехватчике пользовательского продюсера прямо перед отправкой сообщения.
- повторяются сообщения, которые не могут быть десериализованы или проверены, поэтому их приходится явно исключать из конфигурации топика повторных попыток. Впрочем, это частично решено в Spring Kafka 2.8.
- если сообщение попало в DLT из-за ошибок десериализации, оно несет исключение десериализации со всеми данными, которые не могут быть десериализованы. Когда такое DLT-сообщение доставляется обработчику недоставленных сообщений и его не удается десериализовать, создается новое DLT-сообщение еще большего размера. Это создает цикл, когда DLT заполняется постоянно растущими сообщениями, пока не будет превышен максимальный размер записи Kafka. Избежать этого поможет отключение отправки ошибочных недоставленных сообщений в DLT, что по умолчанию настроено в Spring Kafka 2.8.
- Без явной установки префикса идентификатора клиента в аннотации слушателя метрики потребителя Kafka могут работать некорректно. Исправить ситуацию поможет явная установка параметров конфигурации:
@KafkaListener(
id = RecoveryQueueConfig.ID,
idIsGroup = false,
topics = RecoveryQueueConfig.TOPIC,
clientIdPrefix = "${kafka.consumers.recovery-queue.clientId}",
containerFactory = RecoveryQueueConfig.CONTAINER_FACTORY,
groupId = RecoveryQueueConfig.GROUP_ID)
public void listen(@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(name = KafkaHeaders.RECEIVED_MESSAGE_KEY, required = false) String key,
@Nullable @Header(RetryTopicHeaders.DEFAULT_HEADER_ATTEMPTS) byte[] attempts,
@Valid @Payload RecoveryMessage recoveryMessage) {
...
}
Больше практических кейсов по администрированию и эксплуатации Apache Kafka для потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://medium.com/jamf-engineering/retryable-topics-with-spring-kafka-946360f2d644
- https://docs.spring.io/spring-kafka/reference/html/

