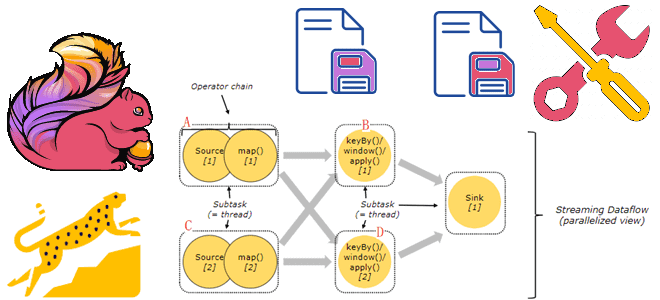
Почему хранить состояния Flink-приложений лучше на локальных SSD-диски, а не на твердотельных накопителях с удаленной файловой системой NFS или HDFS, зачем отключать блочный кэш RocksDB и как настроить параллелизм заданий. Проблемы сохранения состояния в RocksDB и способы их решения Как мы уже упоминали здесь, key-value хранилище RocksDB является самым популярным...
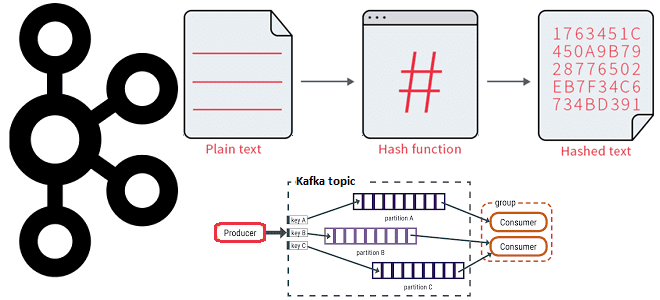
Как работает распределение сообщений по разделам топика Kafka с явно заданным ключом партиционирования и на что влияет язык разработки приложения-продюсера при использовании этой стратегии. 3 стратегии распределения сообщений по разделам в Apache Kafka В Apache Kafka единицей параллелизма выступает раздел топика. Используя несколько разделов, можно распределять нагрузку на брокеров в...

Ранее мы писали про проблемы повышения производительности Apache AirFlow и каковы их причины. В продолжение этой темы сегодня рассмотрим, как настроить этот ETL-оркестратор, чтобы избежать подобных ситуаций и масштабировать кластер в соответствии с нагрузкой. Настройка AirFlow на уровне среды Как мы уже отмечали, Apache AirFlow отлично масштабируется, обеспечивая высокую производительность...
Почему безопасность ML-систем становится все более важным вопросом и как ее обеспечить: MLOps-подходы, практики и технологии защиты данных, моделей машинного обучения, а также вычислительных и инфраструктурных конвейеров. Защита данных для машинного обучения В связи с активным внедрением система машинного обучения в производственное использование, вопрос безопасности становится все более актуальным. ML-системы...
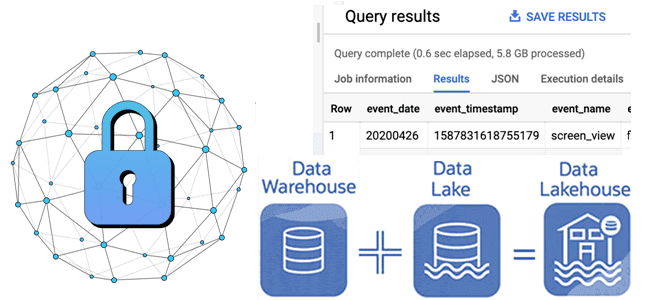
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...

Как управлять средой PySpark-приложения в распределенной вычислительной среде: проблемы зависимостей Python в кластере и способы их решения с помощью сеансов Spark Connect в версии 3.5.0. Управление зависимостями в Python и PySpark Каждый Python-разработчик хотя бы раз сталкивался с проблемой несовместимости пакетов. Эта ситуация называется ад зависимостей (dependency hell), когда вновь...

24 октября 2023 года вышел очередной релиз Apache Flink. Знакомимся с главными новинками популярного Big Data фреймворка для разработки потоковых stateful-приложений: JDBC-драйвер для SQL-шлюза, хранимые процедуры для коннекторов, расширенная поддержка SQL, динамическое масштабирование с REST API и RocksDB, улучшение пакетных операций, а также другие полезные фичи Apache Flink 1.18. Улучшения...
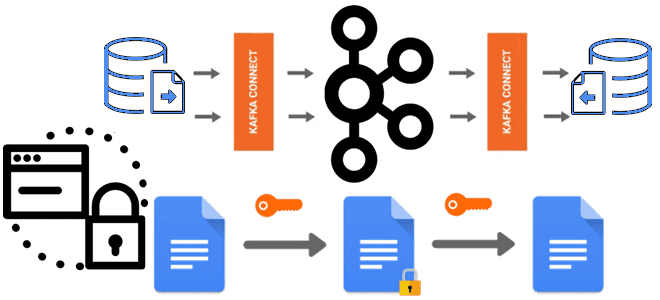
О важности шифрования чувствительных данных, публикуемых в Apache Kafka, мы недавно писали здесь и здесь. В продолжение этой темы сегодня познакомимся с Kryptonite – open-source библиотекой для сквозного шифрования на уровне полей для Apache Kafka Connect. Шифрование данных вне брокеров Apache Kafka: зачем это нужно Apache Kafka поддерживает несколько функций...

Зачем управлять трансферным обучением больших языковых моделей и что входит в это управление: знакомимся с расширением MLOps для LLM под названием LLMOps. Что такое LLMOps Большие языковые модели, воплощенные в генеративных нейросетях (ChatGPT и прочие аналоги), стали главной технологией уходящего года, которая уже активно используется на практике как частными лицами,...
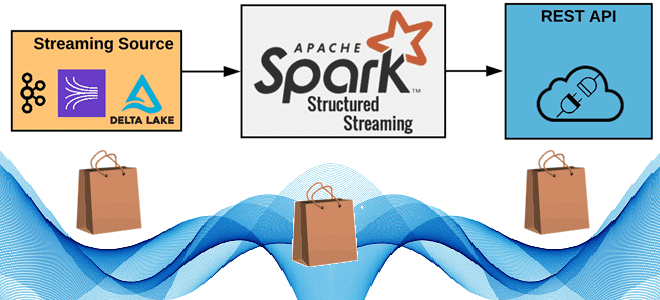
Как реализовать потоковую публикацию данных из приложения Apache Spark Structured Streaming во внешний REST API, используя метод foreachBatch(), зачем перераспределять датафрейм перед его упаковкой в полезную нагрузку HTTP-запроса, от чего зависит число вызовов, и какие приемы помогут избежать сбоев из-за ошибок. 6 шагов потоковой публикации данных в REST API с...