
Сегодня в рамках продвижения нашего курса по графовой аналитике больших данных в бизнес-приложениях, рассмотрим новый инструмент популярной графовой СУБД Neo4j для загрузки данных – Data Importer. Что это такое, как работает, чем полезно специалисту по Data Science и зачем обновлять его до последней версии.
Что такое Neo4j Data Importer
Графовая СУБД Neo4j имеет множество вариантов загрузки данных, начиная от универсальной Cypher-команды LOAD CSV до онлайн-импорта с neo4j-admin для быстрой загрузки полной базы данных. Но все эти инструменты требуют определенных знаний и навыков, которые могут отсутствовать у начинающих пользователей. Чтобы снизить порог входа в технологию, разработчики этой графововй СУБД выпустили Neo4j Data Importer – легковесный пользовательский веб-интерфейс, который позволяет без написания кода загрузить в Neo4j данные плоских файлов (CSV, TSV) объемом около 1 миллиона общих строк. Data Importer дает возможность набросать графовую модель и сопоставить входные данные с ее структурой и свойствами. Загружаемые данные хранятся только в веб-браузере пользователя, без копирования на стороне сервера.
При том, что Data Importer не заменяет специализированные ETL-инструменты и средства обработки производственных нагрузок, он позволяет быстро преобразовать данные плоских файлов в граф. Средство по умолчанию доступно в облачной среде AuraDB, а для самостоятельных установок его можно использовать по адресу http://data-importer.graphapp.io для экземпляров Neo4j, не защищенных сертификатом.
Работа по импорту данных в Neo4j с Data Importer сводится к следующим шагам:
- загрузить данные из CSV- или TSV-файла;
- задать модель графа, определив узлы и отношения;
- сопоставить данные CSV- или TSV-файла с графовой моделью;
- импортировать эти данные в Neo4j.
После этого можно обращаться к созданному графу в Neo4j и визуализировать результаты анализа в Bloom.
Пока Neo4j Data Importer находится в состоянии бета-релиза: впервые он был выпущен в феврале 2022,а уже пару месяцев спустя вышла его новая версия, главные фичи которой мы рассмотрим далее.
Главные улучшения свежего выпуска
В апрельском релизе 0.1.2-beta Neo4j Data Importer улучшена обработка пустого идентификатора. Ранее при наличии в загружаемом CSV/TSV-файле пустой строки она считалась уникальным идентификатором и для нее создавался узел графа. Если в пользовательских данных было много отсутствующих идентификаторов, это могло привести к тому, что на графе появится суперузел с одиноким пустым идентификатором. Поскольку плоские файлы не имеют концепции null-значений, была реализован обработчик пустых строк. Теперь пустые строки рассматриваются как null-значения, когда речь идет об идентификаторах узлов. Если пустая строка является идентификатором для импорта узла, такие строки отфильтровываются, т.е. для них больше не создается узел в графе.
Также добавлен параметр для конфигурации загрузки, который позволяет пользователю указать другие строковые значения, которые следует рассматривать как пустые. Это пригодится, когда есть фактические строковые значения, такие как null или undefined в столбцах идентификаторов. Этот параметр относится к пользовательской модели/сопоставлению и будет экспортирован вместе с конфигурацией при ее расшаривании.
Загрузки, которые ранее завершались сбоем из-за ошибок преобразования типа в поле идентификатора, например, преобразование строки в целое число, теперь обрабатываются аналогично свойствам с пустой строкой. Узлы, где тип свойство, используемого как идентификатор, не удается правильно преобразовать, не создаются. Эти случаи отражаются в сводном отчете о загрузке данных.
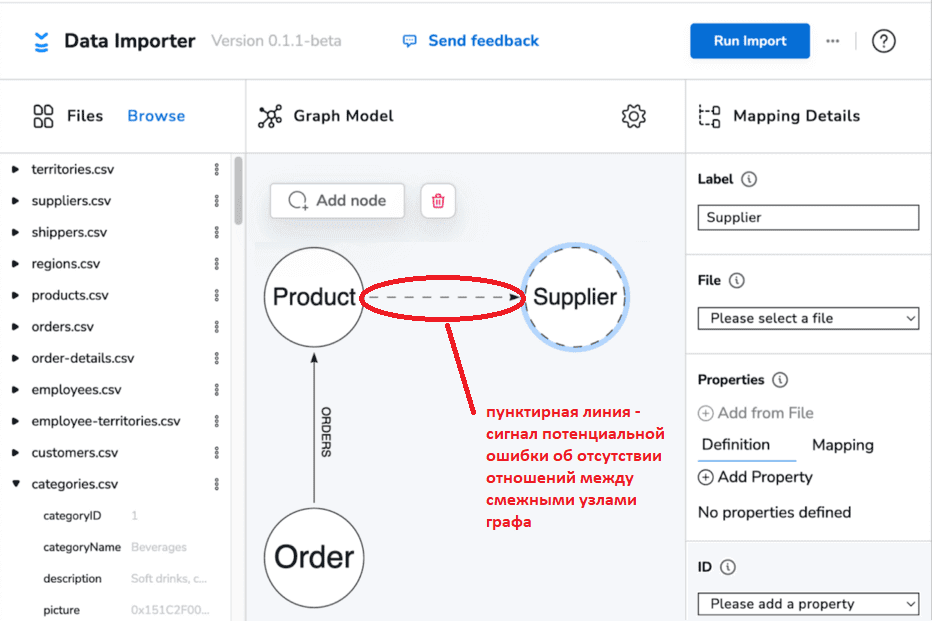
Также улучшено представление частичных сопоставлений и ошибок. Ключевой частью использования Data Importer является правильное определение модели и сопоставления. Это означает, что пользователю следует убедиться в корректном заполнении всех полей сопоставления. Хотя предыдущая версия Data Importer проверяла это, из графовой модели не всегда было ясно, что сопоставлено частично, а не полностью, и возникали ошибки на графовой модели.
В новой версии Data Importer узлы и отношения, которые еще не полностью сопоставлены, показываются пунктирной линией. При попытке запуска импорта с незавершенными сопоставлениями, инструмент напомнит пользователю, какие части модели или сопоставления следует доделать.
Также внесены несколько косметических улучшений в способ отображения хода загрузки, который теперь представлен в виде индикатора выполнения, добавлены небольшие изменения в элементы UI (кнопки и меню). Читайте в нашей новой статье про еще один полезный инструмент Neo4j – библиотеку APOC.
Больше практических примеров использования Neo4j и других инструментов графовой аналитики больших данных для реальных бизнес-задач вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

