Сегодня рассмотрим, что такое WebHCat в Apache Hive и как этот REST API позволяет взаимодействовать с HCatalog, используя стандартные HTTP-методы. Еще разберем, какие DDL-команды Hive и HiveQL не поддерживает HCatalog, а также что полезного может быть в лог-файлах Templeton.
Принципы работы компонента WebHCat как REST-сервиса Apache Hive
Будучи NoSQL-хранилищем класса SQL-on-Hadoop, которое обеспечивает доступ к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы, Apache Hive имеет для этого целый набор компонентов. Одним из них является HCatalog – уровень управления таблицами и хранилищами для Hadoop, который пользователям читать и записывать данные с помощью различных инструментов, например, заданий MapReduce. HCatalog работает как ключевой компонент Hive и позволяет пользователям хранить свои данные в любом формате и любой структуре.
Чтобы упростить взаимодействие с HCatalog, который входит в состав Apache Hive с 2013 года, в версии 0.11.0 была представлена REST API веб-служба WebHCat (ранее Templeton), которая позволяет работать с HCatalog через отправку типовых HTTP-запросов к конечным точкам. WebHCat использовать для запуска заданий Hadoop MapReduce, YARN, Pig, Hive или выполнения операций с метаданными Hive с использованием REST-интерфейса через HTTP-методы. WebHCat работает как REST-интерфейс для удаленного выполнения заданий Hive, Pig, Sqoop и MapReduce. Сервис переводит запросы на отправку заданий в приложения YARN и возвращает полученный статус.
Разработчики вызывают из приложений HTTP-запросы для доступа к Hadoop MapReduce или YARN, Pig, Hive и HCatalog через DDL-команды. Данные и код, используемые этим API, хранятся в распределенной файловой системе Apache Hadoop (HDFS). DDL-команды HCatalog выполняются непосредственно по запросу. Задания MapReduce, Pig и Hive помещаются в очередь серверами WebHCat, и их ход выполнения можно отслеживать или при необходимости останавливать. Разработчик указывает место в HDFS, куда следует поместить результаты выполнения заданий Pig, Hive и MapReduce.
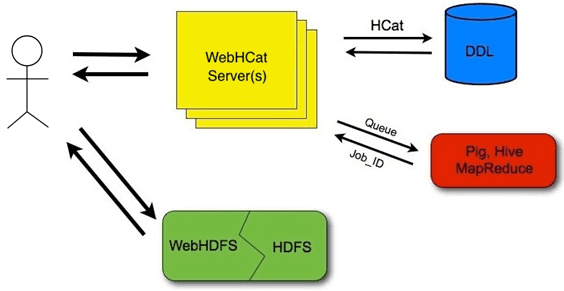
Данные и код, которые используются ресурсами REST HCatalog, должны быть сначала размещены в Hadoop. Когда требуется размещение файлов в HDFS, можно использовать любой наиболее удобный способ, например, WebHDFS . Этот REST API поддерживает полный интерфейс файловой системы FileSystem для HDFS, позволяя перемещать файлы в HDFS и считывать их оттуда через обратно с помощью типовых HTTP-методов (GET, PUT, POST, DELETE).
Конечная точка, предоставляющая доступ к REST-ресурсам HCatalog, выглядит как URL следующего формата:
http://yourserver/templeton/v1/resource
где «yourserver» заменяется именем сервера, а «resource» заменяется именем ресурса HCatalog.
Например, чтобы проверить, работает ли сервер, надо отправить GET-запрос к следующему URL-адресу:
http://www.myserver.com/templeton/v1/status
В ответ сервер WebHCat возвращает следующие коды HTTP:
- 200 ОК показывает успешное выполнение запроса;
- 400 Bad Request — запрос недействителен, возникла проблема на стороне клиента;
- 401 Unauthorized — учетные данные клиента отсутствуют или некорректны;
- 404 Not Found — запрошенный URI недействителен или не существует;
- 500 Internal Server Error – ошибка на стороне сервера, неожиданный результат;
- 503 Service Unavailable — сервер временно занят обработкой других запросов.
Данные от сервера WebHCat возвращаются в формате JSON, при этом размер ответов ограничен 1 МБ. Ответы сверх этого предела должны быть сохранены в HDFS с использованием предоставленных параметров, а не возвращены напрямую. Если DDL-команда HCatalog может возвращать результаты размером более 1 МБ, вместо этого предлагается выполнить соответствующий запрос Hive.
Напомним, HCatalog поддерживает все команды языка определения данных Hive, за исключением тех операций, которые требуют запуска задания MapReduce. Для поддерживаемых команд любые отклонения указаны ниже. HCatalog не поддерживает следующие DDL-команды Hive и HiveQL:
- ALTER INDEX … REBUILD
- CREATE TABLE … AS SELECT
- ALTER TABLE … CONCATENATE
- ALTER TABLE ARCHIVE/UNARCHIVE PARTITION
- ANALYZE TABLE … COMPUTE STATISTICS
- IMPORT FROM …
- EXPORT TABLE
Во время работы сервер WebHCat создает три файла журнала:
- Templeton.log — журнал библиотеки логирования log4j, основной лог, куда приложение записывает данные о событиях;
- Templeton-console.log — то, что Java записывает в стандартный вывод при запуске сервера WebHCat.. Это небольшой объем данных, аналогичный «hcat.out».
- Templeton-console-error.log — сведения об ошибках, которые Java записывает в stderr, аналогично «hcat.err».
В файле tempelton-log4j.properties можно указать расположение этих журналов с помощью переменной Templeton.log.dir. Этот файл log4j.properties задается в сценарии запуска сервера WebHCat.
В большинстве случаев, когда WebHCat возвращает HTTP-ответ с кодом 500, сообщение об ошибке содержит подробные сведения о ней. Если этого не достаточно, можно заглянуть в файл webhcat.log, просмотрев сообщения типа WARN и ERROR. Также просмотр лог-файлов полезен, когда взаимодействие с WebHCat проходит успешно, но фактически задания не выполняются. WebHCat собирает выходные данные консоли заданий как stderr в каталоге состояния, включая идентификатор приложения YARN фактического запроса. Эти данные пригодятся при тестировании и отладке приложений.
Узнайте все подробности про администрирование и эксплуатацию Apache Hive и других компонентов экосистемы Hadoop для хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

