
В конце 2020 года вышел мажорный релиз Apache AirFlow, основные фишки которого мы рассмотрим в этой статье. Читайте далее про 10 главных обновлений Apache AirFlow 2.0, благодаря которым этот DataOps-инструмент для пакетных заданий обработки Big Data стал еще лучше. 10 главных обновлений Apache AirFlow 2.0 Напомним, разработанный в 2014 году...

Недавно мы уже рассматривали выполнение Join-операций в Apache Spark SQL. Сегодня поговорим про особенности потокового соединения в модуле Structured Streaming этого популярного фреймворка аналитики больших данных. Читайте далее, в чем специфика внешних и внутренних соединений потоков Big Data в Apache Spark Structured Streaming, а также как и зачем Inner/Outer Join...

Совместное использование Apache Kafka и Spark очень часто встречается в потоковой аналитике больших данных, например, в прогнозировании пользовательского поведения, о чем мы рассказывали вчера. Однако, временные метки (timestamp) в приложении Spark Structured Streaming могут отличаться от времени события в топике Kafka. Читайте далее, почему это случается и какие подходы к...
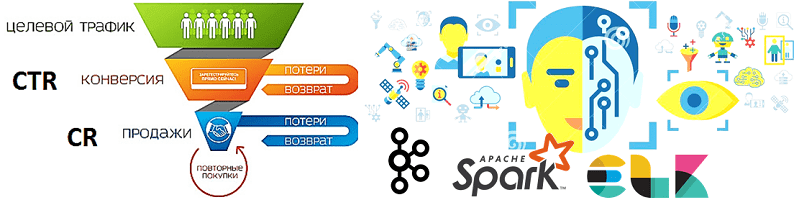
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
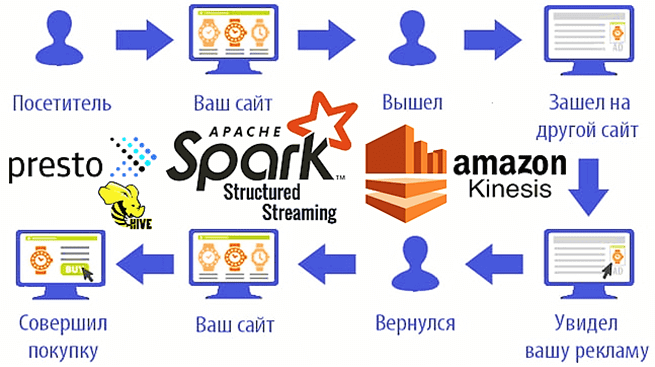
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

Продолжая разговор про фиксацию заданий Apache Spark при работе с облачными хранилищами больших данных, сегодня подробнее рассмотрим, насколько эффективны commit-протоколы экосистемы Hadoop, предоставляемые по умолчанию, и почему известный разработчик Big Data решений, компания Databricks, разработала собственный алгоритм. Читайте далее про сравнение протоколов фиксации заданий в Spark-приложениях: результаты оценки производительности и...

Сегодня поговорим про особенности транзакций в Apache Spark, что такое фиксация заданий в этом Big Data фреймворке, как она связано с протоколами экосистемы Hadoop и чем это ограничивает переход в облако с локального кластера. Читайте далее, как найти компромисс между безопасностью и высокой производительностью, а также чем облачные хранилища отличаются...

В этой статье рассмотрим, что такое Apache Spark Structured Streaming и Spark Streaming, чем они отличаются и что общего между этими 2-мя способами обработки потоковых данных в самом популярном фреймворке аналитики больших данных. Читайте далее, как микро-пакетная передача приближается к режиму реального времени и при чем здесь структуры данных для...

Вчера мы говорили про реализацию exactly once семантики доставки сообщений в Apache Spark Structured Streaming. Сегодня рассмотрим, что не так с размером компактных файлов для хранения контрольных точек потоковой передачи, какие параметры конфигурации Spark SQL отвечают за такое логирование и как ускорить микро-пакетную обработку больших данных и чтение результатов выполнения...

Недавно мы рассматривали оптимизацию SQL-запросов и выполнение JOIN-операций в Apache Spark. Сегодня поговорим, что обеспечивает строго однократную семантику доставку сообщений (exactly once) в этом Big Data фреймворке и как на это влияют особенности микро-пакетной обработки больших данных с помощью заданий Spark Structured Streaming. Особенности exactly once доставки сообщений в Apache...