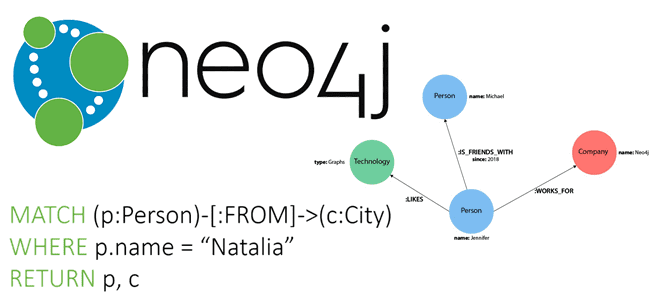
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим ключевые отличия графовых СУБД от реляционных, а также познакомимся с основами Neo4j и ее языком запросов - Cypher. Также вас ждет практический пример построения несложного графа средствами Cypher. Когда графовые СУБД лучше реляционных и почему Несмотря на...

Сегодня рассмотрим, как методы графовой аналитики больших данных помогают бороться с эпидемией финансовых мошенничеств: выявлять номера злоумышленников, идентифицировать фрод-транзакции, выявлять и предотвращать схемы отмывания денег. Читайте далее, что под капотом AML-систем и как инструменты Data Science предотвращают злоупотребление методами социальной инженерии. Немного истории: что такое социальная инженерия и чем это...

В продолжение недавней статьи для дата-инженеров про альтернативные платформы потоковой передачи событий вместо Apache Kafka, сегодня рассмотрим пример аналитики больших данных средствами Flink SQL, записи результатов в Elasticsearch и их визуализации в Kibana. Читайте далее, чем Redpanda отличается от Kafka, а Flink – от Apache Spark с точки зрения потоковой...

В рамках обучения разработчиков Spark-приложений, аналитиков данных и дата-инженеров, сегодня рассмотрим, как улучшить и визуализировать понимание обработки данных в этом Big Data фреймворке. Читайте далее про API встроенных механизмов наблюдения за качеством данных в Apache Spark и открытые библиотеки профилирования на примере Deequ. 2 уровня абстракции мониторинга Spark-приложений для дата-инженера...

При том, что Apache Kafka является фреймворком №1 в потоковой обработке Big Data, эта распределенная платформа передачи событий имеет специфические недостатки и ограничения, которые затрудняют ее использование в некоторых сценариях. Сегодня рассмотрим, что именно в Apache Kafka усложняет жизнь администраторам, разработчикам и дата-инженерам, а также как Redpanda решает эти проблемы....

Анализ данных в рамках пользовательский сеансов (сессий) – довольно востребованный кейс в Apache Spark, который не так просто реализовать из-за особенностей потоковой и пакетной обработки, а также эксплуатационных расходов. Сегодня рассмотрим, как работают сеансовые окна Spark Structured Streaming и каковы ограничения этого фреймворка. Что такое сеансовые окна: краткий ликбез по...

В этой статье для разработчиков Apache Kafka рассмотрим пример масштабирования потоковой обработки событий с Akka Streams. Читайте далее, что не так с параллелизмом при одновременном выполнении событий на запись, как Akka Streams решает эту проблему и при чем здесь Apache Kafka. Проблемы масштабирования потоковой обработки в Kafka Streams Масштабная потоковая...
На протяжении всей истории человечества пандемии являлись причинами глобальных макроэкономических изменений. Например, эпидемия чумы привела к окончательному падению монгольской империи, изменив баланс сил между мусульманским и европейским миром в пользу последнего. А эпидемия испанки, разразившаяся в конце первой мировой войны, привела к окончательной капитуляции Германии. Последняя пандемия COVID-19 изменила мир...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...
В рамках продвижения нашего нового курса по графовым алгоритмам на больших данных, сегодня разберем, что такое Pregel, и как API этой платформы реализован в Apache Spark GraphX. Читайте далее, как из RDD вершин и ребер образуется триплет, а также какие механизмы отвечают за отказоустойчивость графовой аналитики больших данных. Что такое...