
В этой статье по обучению дата-инженеров разберем, что такое Apache Beam, чем этот фреймворк отличается от AirFlow и что между ними общего. На первый взгляд Apache Airflow и Beam являются конкурентами: они предназначены для организации процессов обработки данных в определенном порядке. Оба инструмента являются open-source проектами, широко используются и поддерживаются...

Добавляя новые интересные примеры в наши курсы для дата-аналитиков, разработчиков распределенных приложений и администраторов SQL-on-Hadoop, сегодня рассмотрим опыт видеоаналитики в компании Vimeo с использованием Apache Spark. Как быстро запросить множество данных из Apache HDFS через Phoenix и Spark из моментальных снимков HBase с минимальным влиянием на кластер. Аналитика очень больших...

Сегодня рассмотрим кейс международной ИТ-компании AppsFlyer, которая создает SaaS-решения для маркетинговой аналитики в режиме онлайн. В этой статье команда разработки аналитического продукта Data Locker делится опытом оптимизации ETL-приложений Apache Spark для снижения стоимости обработки данных и ускорения вычислений. Предыстория: слишком много файлов в ETL-решении на Spark и AWS S3 в...

Всего через 1,5 месяца после выпуска версии 1.15.0, 22 декабря 2021 года вышел очередной релиз Apache NiFi. Разбираем главные новинки и исправленные баги, а также смотрим, как команда разработчиков решила избавиться от уязвимости Log4Shell. Не только Log4j: еще 3 исправленных ошибки Декабрьский релиз Apache NiFi не может похвастаться внушительным списков...

В этой статье для дата-аналитиков и разработчиков Neo4j, разберем, как реализовать GraphQL-сервер для взаимодействия с этой графовой NoSQL-СУБД. Библиотека Neo4j GraphQL и ее практическое применение для графовой аналитики больших данных в бизнес-приложениях. Еще раз про GraphQL О том, что такое GraphQL (GQL) и как это связано с архитектурным стилем REST, мы писали...

Сегодня в рамках обучения дата-аналитиков и разработчиков распределенных приложений, рассмотрим, что такое пользовательские функции в Apache Hive, как их создать и использовать. А также в чем проблема вызова UDF-функции, зарегистрированной в Hive, из Impala и при чем здесь Sentry. Простые и сложные UDF в Apache Hive Пользовательские функции в Hive...
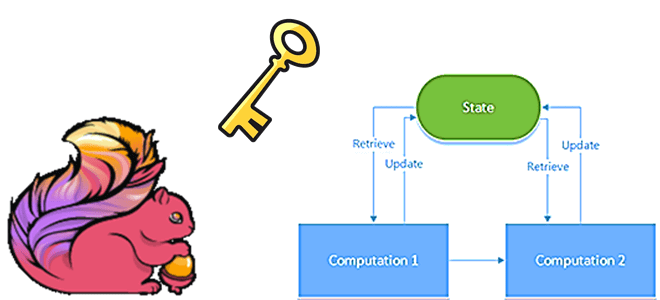
Что такое состояния в приложениях Apache Flink, каких видов они бывают, как ими управлять и зачем это нужно: основы разработки stateful-заданий и API DataStream. Чем состояние с ключом отличается от оператора состояния и почему первый чаще используется на практике. Состояния в Apache Flink Apache Flink поддерживает как stateful-, так и...

В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, что такое локальность данных и как это влияет на производительность заданий. А также разберем, где в UI Apache Spark посмотреть нахождение данных для распределенных вычислений и какие параметры конфигурации следует настроить, чтобы повысить скорость их выполнения. Что такое локальность данных в...
В этой статье разберем кейс бразильской фудтех-компании Ifood по реализации микросервисной ML-системы на Apache Kafka и serverless NoSQL-СУБД DynamoDB с пропускной способностью миллиарды сообщений в секунду. Сложности масштабирования микросервисов и оперативное чтение данных из Feature Store с помощью библиотеки Sarama – Go-клиента для Apache Kafka. Проблема микросервисов при множестве обращений...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня поговорим про визуализацию графов в NoSQL-СУБД Neo4j. А также рассмотрим, как с помощью GraphKer получить визуальное отображение графа данных о информационной безопасности: уязвимости, атаки и прочие нарушения cybersecurity. ТОП-5 способов визуализации графов в Neo4j Поскольку люди лучше воспринимают визуальную информацию, инструменты...