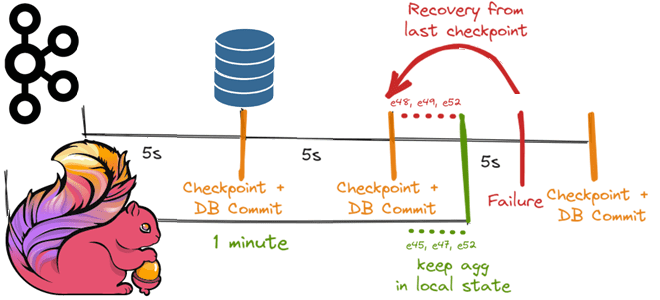
Как Apache Flink реализует строго однократную доставку событий в потовой обработке данных с помощью контрольных точек для записи данных в реляционную базу, используя функцию TwoPhasedCommitSink(), основанную на механизме согласованных snapshot’ов 35-летней давности и Kafka Transaction API. Трудности строго однократной доставки в потоковой обработке данных Распределенная обработка потоков с отслеживанием состояния...

Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...

Разработка высоконагруженных систем потоковой аналитики больших данных включает не только написание кода, но и его оптимизацию. Поэтому разработчикам приложений Apache Spark Structured Streaming и дата-инженерам полезно знать, как можно повысить эффективность своих Big Data систем. В этой статье мы рассмотрим конфигурации и приемы, которые могут ускорить пакетные и потоковые вычисления....

10 октября 2022 года вышел очередной релиз Apache NiFi. Разбираемся с его ключевыми новинками: провайдеры параметров, подключаемый реестр клиентов, новые процессоры и улучшения протокола MQTT. Самые главные фичи свежего выпуска для дата-инженера и администратора кластера Apache NiFi. ТОП-7 новых фич свежего релиза Будучи популярным инструментов современной дата-инженерии, Apache NiFi активно...

Как турецкая e-commerce компания Trendyol повысила эффективность пакетных вычислений, используя распределенную платформу потоковой обработки событий Apache Kafka вместе с серверной утилитой сбора и фильтрации данных из разных источников Logstash. Пакетная обработка данных и конвейер на Logstash Хотя сегодня все больше организаций переходят на потоковую обработку событий в реальном времени, пакетная...
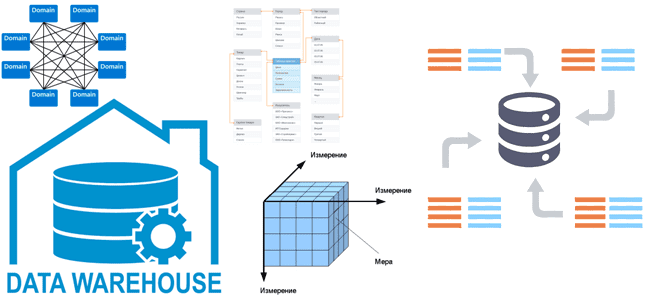
Все архитекторы DWH и многие дата-инженеры знакомы с идеями Ральфа Кимбалла, согласно которым хранилище данных — это сочетание множества различных витрин данных, облегчающих отчетность и анализ важных бизнес-показателей. Читайте далее, как реализовать этот подход при проектировании корпоративного хранилища данных и при чем здесь Data Mesh. КХД по Кимбаллу: доменные витрины...
В этой статье продолжим говорить про лучшие практики работы с Greenplum и рассмотрим тонкости проектирования схем данных в этой MPP-СУБД, которая часто применяется для хранения и аналитики больших данных. Почему надо задавать одинаковые типы данных для столбцов, используемых в SQL-запросах c оператором JOIN, чем хранилище кучи отличается от Append Only,...
Сегодня рассмотрим, как реализовать MLOps-идеи при разработке приложений Apache Flink с использованием MLeap, библиотеки сериализации для моделей машинного обучения. Зачем инженеры GetInData разрабатывали для этого свой коннектор и как его использовать на практике. Что такое MLeap и при чем здесь MLOps Будучи популярным вычислительным движком для потоковой аналитики больших данных,...
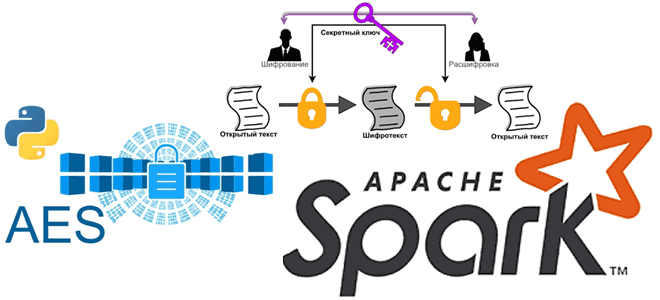
Мы уже писали про использование криптографии в Apache Spark. Сегодня в рамках обучения дата-инженеров и разработчиков распределенных приложений рассмотрим, как шифровать столбцы датафрейма в PySpark и расшифровывать их с использованием алгоритма шифрования AES. Основы кибербезопасности: ликбез по шифрованию данных Шифрование данных преобразует данные в другую форму или код, чтобы их...

Каждый разработчик и дата-аналитик с закрытыми глазами напишет SQL-запрос с регулярными выражениями для поиска данных по шаблону в реляционной базе. А вот в NoSQL-СУБД такая простая задача реализуется довольно сложно. Как написать регулярное выражение в Apache HBase и запустить его на исполнение в CLI-интерфейсе shell-оболочки этого хранилища данных. Что такое...