Продолжая говорить про обучение разработчиков и администраторов Apache Kafka, сегодня разберем сложности семантики строго однократной доставки сообщений (exactly once) в случае нескольких экземплярах, находящихся в разных кластерах. Читайте далее, что не так с межкластерными транзакциями, какие KIP’ы связаны с этой проблемой и при чем здесь MirrorMaker. Что не так с...
Сегодня рассмотрим важную тему из курсов для разработчиков и администраторов Apache Kafka: как сэкономить место на диске и увеличить пропускную способность всей Big Data системы на базе этой платформы потоковой обработки событий. Читайте далее, зачем добавлять задержку перед отправкой сообщений брокеру, как кодеки сжатия помогут снизить затраты на облачный Kafka-кластер...

В этой статье поговорим про практическое обучение Apache Kafka и рассмотрим, как сделать продюсеров еще более отказоустойчивыми, чтобы улучшить общую надежность всей Big Data системы. Читайте далее про наиболее важные конфигурации продюсеров Kafka и эффективные рекомендации по их настройке. 10 самых важных параметров продюсера Apache Kafka Из множества конфигурационных параметров...

В рамках обучения дата-инженеров, сегодня рассмотрим проблему роста числа операций ввода-вывода в секунду (IOPS) при обработке большого количества данных в потоках Apache NiFi и способы ее решения. Читайте далее, как перемещение репозиториев NiFi с жесткого диска в оперативную память снижает IOPS, а также зачем при этом в Big Data систему...
Обновляя наши курсы для администраторов Apache Kafka, в этой статье разберем полезные средства, которые помогут вам следить за состоянием кластера, чтобы вовремя заметить существующие и предупредить возможные проблемы. Читайте далее, как отследить снижение производительности всей Big Data системы и сбои на отдельных брокерах с помощью дэшбордов в различных инструментах администрирования....
Вчера мы упоминали, как долгожданный KIP-500, реализованный в марте 2021 года, позволяет не только отказаться от Zookeeper в кластере Apache Kafka, но и снимает ограничение числа разделов, чтобы масштабировать брокеры практически до бесконечности. Однако, не все так просто: читайте далее, какие важные функции еще не поддерживаются в этом экспериментальном режиме...
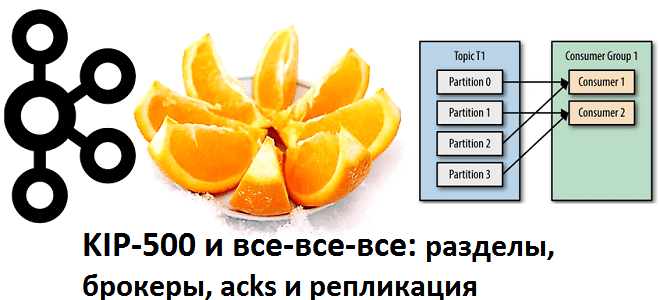
Сегодня рассмотрим важную практическую задачу из курсов Kafka для разработчиков и администраторов кластера – разделение топиков по брокерам. Читайте далее, как пропускная способность всей Big Data системы зависит от числа разделов, коэффициента репликации и ответного ack-параметра, а также при чем здесь KIP-500, позволяющий отказаться от Zookeeper. Что такое партиционирование в...

Сегодня рассмотрим особенности ухода с коммерческого дистрибутива Hadoop к версии сообщества на примере американской рекламной платформы Outbrain. Читайте далее, зачем дата-инженеры компании приняли такое решение, почему им не подошли альтернативы от MapR, Cloudera и Google Cloud Platform (DataProc), как проходила миграция на Apache Hadoop и что получилось в итоге. Предыстория:...

В январе 2021 года российский разработчик решений для хранения и аналитики больших данных, компания Arenadata, представила новый продукт в линейке сервисов отечественного дистрибутива Apache Hadoop. Модуль Arenadata Platform Security обеспечивает централизованное управление групповыми политиками безопасности кластера. Разбираемся, что представляет собой эта система, как она связана с Apache Ranger и чем...

В этой статье рассмотрим типичные проблемы топиков Apache Kafka, с которыми сталкивается каждый администратор Big Data кластера. Читайте далее, почему топики чрезмерно разрастаются, как работает очистка логов, когда старые сообщения могут остаться в почищенных сегментах и какие параметры конфигураций помогут справиться со всем этим. Брокеры и разделы: как устроены топики...