 605
605 
Содержание
Сегодня рассмотрим особенности ухода с коммерческого дистрибутива Hadoop к версии сообщества на примере американской рекламной платформы Outbrain. Читайте далее, зачем дата-инженеры компании приняли такое решение, почему им не подошли альтернативы от MapR, Cloudera и Google Cloud Platform (DataProc), как проходила миграция на Apache Hadoop и что получилось в итоге.
Предыстория: зачем рекламной бирже менять платформу Big Data
Об основном бизнесе компании Outbrain, ретаргетинговой веб-рекламе, мы уже рассказывали здесь, на примере системы потоковой аналитики больших данных с Apache Kafka, Spark Streaming и Druid. Это одна из ведущих платформ для поиска контента, которая предоставляет более 400 миллиардов рекомендаций миллиарду пользователей по всему миру. Благодаря персонализированному обращение к потенциальному покупателю, уже заинтересованному в продукте, эффективность рекламных кампаний существенно возрастает. Поэтому услугами Outbrain активно пользуются многие крупные корпорации DHL, FIAT, NESTLE, Mercedes-Benz, AVON, Vodafone, Volvo и множество других компаний из различных секторов экономики [1].
Технически Big Data инфраструктура Outbrain реализована на тысячах микросервисов внутри контейнеров Kubernetes, расположенных на более чем 7000 физических машинах в 3 центрах обработки данных и в публичных облаках (Google Cloud Platform, GCP, и Amazon Web Services, AWS). За формирование персональных рекомендаций отвечают алгоритмы машинного обучения, работающие в фоновом режиме поверх экосистемы Hadoop, кластера которой разделены по 2-м категориям [2]:
- онлайн — 2 кластера в режиме полного аварийного восстановления на голом железе для онлайн-обслуживания;
- R&D — несколько кластеров для разных групп и вариантов использования в GCP, чтобы офлайн проводить исследования и разработки новых решений.
Ежедневно каждый кластер получает более 50 ТБ новых данных и выполняет более 10 КБ заданий.
Изначально онлайн-кластеры Hadoop использовали коммерческое решение MapR с корпоративной поддержкой. Но через несколько лет уровень экспертизы в Hadoop у инженеров данных и администраторов Big Data компании Outbrain существенно вырос. Поэтому за несколько месяцев до истечения лицензии MapR было принято решение самостоятельной поддержки Hadoop-кластеров. Для этого нужно было решить, какой дистрибутив дальше будет использоваться в качестве основы для масштабной системы аналитики больших данных.
Какой Hadoop выбрать: поиск альтернатив
Специалисты Outbrain выбирали из следующих альтернативных дистрибутивов Hadoop [2]:
- MapR – бесплатная версия сообщества и вариант с коммерческой поддержкой;
- Cloudera – также версия сообщества для кластера не более 100 узлов и коммерческий вариант с коммерческой поддержкой;
- версия сообщества Apache Hadoop;
- DataProc от Google Cloud Platform, о котором мы рассказывали здесь и здесь.
Основными критериями для сравнения альтернатив были следующие:
- тип;
- надежность;
- сложность миграции;
- риск;
- разнообразие экосистемы;
- простота эксплуатации/сложность сопровождения;
- гибкость;
- стоимость.
Оценка сравниваемых дистрибутивов Hadoop по некоторым из этих критериев приведена в таблице.
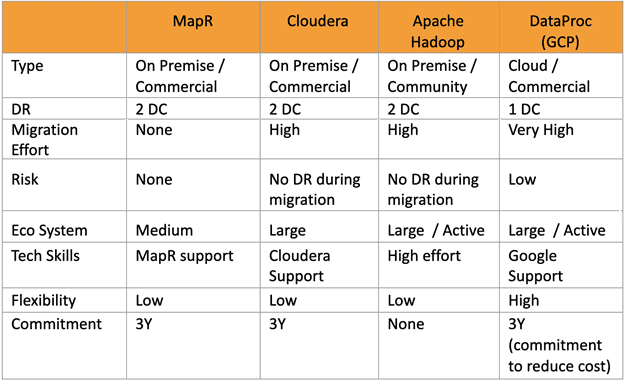
Проанализировав преимущества и ограничения каждого из вариантов, компания Outbrain пришла к выводу, что в перспективе более выгодно обучить собственных сотрудников, чем платить за коммерческие лицензии. Поэтому, при практически равных функциональных возможностях бесплатной версии сообщества Apache Hadoop по сравнению с коммерческими продуктами была выбрана именно она. Отсутствие централизованной технической поддержки инженеры Outbrain решили компенсировать собственными компетенциями.
Тонкости перехода: миграция и ее результаты
Миграцию нужно было выполнить, пока существующая система на базе MapR продолжала работать, частично дублируя предоставляемые пользователям услуги, чтобы избежать каких-либо потерь. Поскольку оба кластера находились в отдельных контроллерах домена, переход выполнялся по одному кластеру за раз и был произведен за несколько циклов. Перенос данных строился следующим образом [2]:
- новые данные загружались через интеграцию кластера Apache с текущим конвейером доставки данных;
- исторические данные были перенесены итеративно, в рамках каждого цикла копировались только те данные, которые требовались в этот раз.
Миграция рабочей нагрузки также состояла из нескольких этапов и выполнялась циклично:
- перенос отдельных заданий из кластера MapR в кластер Apache;
- останов перенесенных заданий в кластере MapR;
- перевод машин из MapR в кластер Apache;
- некоторые задания переносились вместе как единое целое, с учетом их зависимостей друг от друга и емкости кластера.
Подготовка к миграции заняла несколько месяцев, а сам переход произведен в кратчайшие сроки: около 1 месяц на кластер. В результате компания Outbrain получила следующие результаты [2]:
- сотрудники значительно улучшили свои компетенции в Apache Hadoop и могут поддерживать ее самостоятельно на профессиональном уровне;
- повысилась производительность кластера – при том же количестве ядер все задания обрабатываются в 2 раза быстрее;
- во время подготовки к миграции было удалено более 700 ТБ «лишних» данных (некорректных, устаревших, дублирующихся, нерелевантных), что снизило загрузку кластера с 73% до 49%;
- оптимизация рабочих нагрузок и команд, например, из 19 групп осталось 16;
- снижение технического долга за счет использования последних версий всех интегрированных пакетов, обновления Apache Spark и Spark Streaming, внедрения Presto в качестве дополнительного высокопроизводительного инструмента SQL-on-Hadoop, который может объединять несколько источников данных в одном запросе.
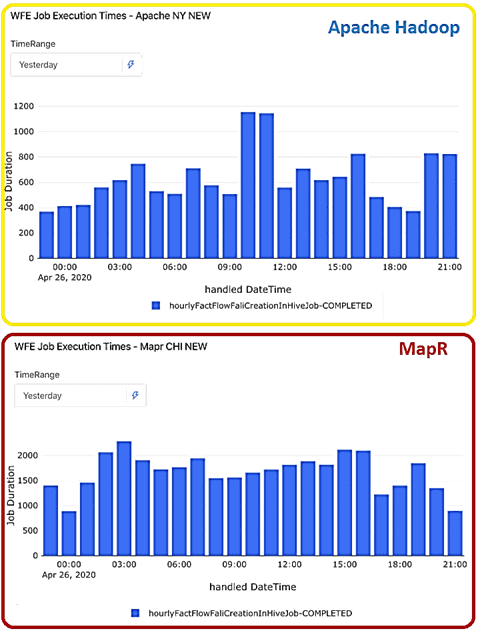
Таким образом, рассмотренный кейс компании Outbrain подтверждает эффективность самостоятельной поддержки даже сложных Big Data платформ при наличии соответствующих компетенций. Получить подобные знания и практические навыки работы с Apache Hadoop, научиться администрировать кластера и разрабатывать распределенные системы аналитики больших данных с компонентами этого фреймворка вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Hadoop
- Администрирование кластера Hadoop
- Безопасность озера данных Hadoop
- Hadoop для инженеров данных
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
Источники

