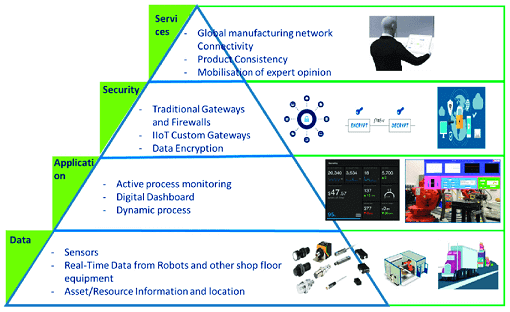
Мы уже рассматривали типовую архитектуру систем Internet of Things (IoT). Сегодня поговорим подробнее про уровневую модель передачи и обработки данных от конечных устройств до облачных IoT-платформ, а также приведем примеры наиболее популярных средств обеспечения каждого из уровней этой сложной архитектуры Industrial Internet of Things, включая инструменты Big Data. Многоуровневый IIoT:...

В этой статье мы рассмотрим, чем похожи и чем отличаются 5 самых популярных инструментов распределенной обработки потоков Big Data: Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza, а также поговорим про наиболее значимые факторы выбора между этими программными средствами. 5 общих характеристик распределенных Big Data фреймворков потоковой обработки Прежде...

Apache Samza часто сравнивают с другими Big Data фреймворками распределенных потоковых вычислений в реальном времени (Real Time, RT): Kafka Streams, Spark Streaming, Flink и Storm. Apache Spark и Flink обладают практически одинаковым набором функциональных возможностей и компонентов, поэтому их можно сравнивать между собой более-менее объективно. Apache Samza является более простой...

Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм,...

Проанализировав сходства и различия Apache Kafka Streams и Spark Streaming, можно сделать некоторые выводы относительно выбора того или иного решения в качестве основного инструмента потоковой обработки Big Data. В этой статье мы собрали для вас аргументы в пользу Кафка Стримс и Спарк Стриминг в конкретных ситуациях, а также нашли некоторые...

Сегодня мы рассмотрим популярные Big Data инструменты обработки потоковых данных: Apache Kafka Streams и Spark Streaming: чем они похожи и чем отличаются. Стоит сказать, что Спарк Стриминг и Кафка Стримс – возможно, наиболее популярные, но не единственные средства обработки информационных потоков Big Data. Для этой цели существует еще множество альтернатив,...

В этой статье мы продолжим говорить про основы Apache Kafka Streams для начинающих и рассмотрим одно из самых важных свойств Кафка – возможность обработки любых данных, накопленных с начала работы Big Data системы. Что такое окна Apache Kafka Streams и зачем они нужны Кафка обеспечивает объективную достоверность накопленных исторических данных...
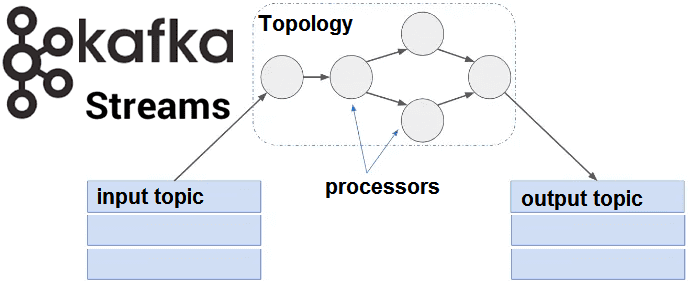
Как мы уже писали, в Apache Kafka Streams таблица и поток данных – это базовые и взаимозаменяемые понятия. Сегодня поговорим о том, как работать с этими объектами Big Data с помощью внутренних средств Кафка Стримс, используя готовые методы высокоуровневого языка DSL и низкоуровневый API-интерфейс для распределенной обработки потоковых данных в...
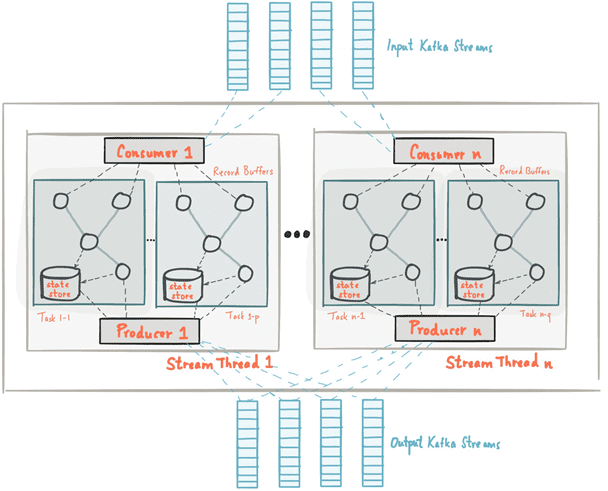
В продолжение темы про основы Apache Kafka Streams для начинающих, сегодня мы поговорим про то, как абстрактные понятия топика (topic), таблицы (table) и потока (stream) позволяют распараллелить обработку информационных потоков. Читайте в нашем новом материале, что такое обработчики потоков Кафка Стримс, как они обрабатывают разделы топиков (topic partition) Kafka и...
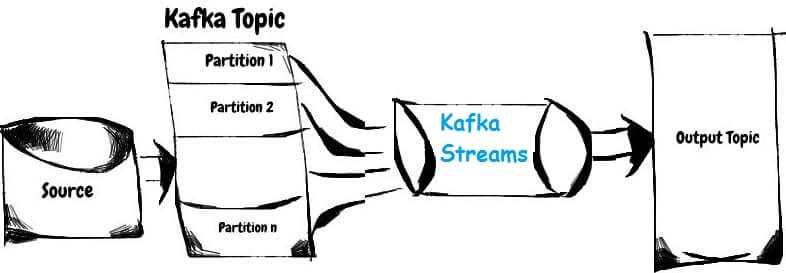
Сегодня мы поговорим про базовые понятия Apache Kafka Streams: потоки, таблицы и топики Кафка. Читайте в нашей статье, как Stream, Table и Topic связаны между собой, чем они похожи, когда таблица становится потоком и почему это обеспечивает эластичность и отказоустойчивость распределенных потоковых приложений Big Data. Что такое таблица, топик и...