 1057
1057 
Содержание
Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм, предназначенный только для относительно простой по логике распределенной обработки потоковых событий, не совсем объективно. Более целесообразно выбирать между Сторм и Apache Samza, что мы рассмотрим в нашей следующей статье. А сегодня поговорим о том, где используется Apache Storm и в каких случаях следует применять именно этот Big Data фреймворк потоковых RT-вычислений.
Apache Storm – Hadoop для потоков Big Data
Чтобы понять, где стоит использовать Шторм, следует вспомнить историю его появления. Storm часто называют Hadoop в мире потоковой обработки Big Data. Apache Hadoop создан для обработки огромного количества данных распределенным способом на обычных аппаратных средствах, но не в реальном времени. Задача MapReduce требует большого дискового пространства: каждый раз при выполнении она извлекает данные с диска, обрабатывает их в памяти и затем записывает обратно на диск, после чего завершается. Для следующей партии данных будет создана новая задача, и весь цикл повторится снова.
В реальном времени информация будет поступать непрерывно, поэтому необходимо параллельно и быстро в распределенном режиме без потери данных получать их, обрабатывать их и продолжать записывать результаты. Именно для этого и был разработан Apache Storm [1].
Отметим, что именно Сторм входит в состав коммерческих дистрибутивов Apache Hadoop от MapR и HortonWorks. Также Apache Storm является основой для S4 – собственной модели обработки событий компании Yahoo!. Однако, Шторм обеспечивает гарантированную обработку сообщений в случае отказов, тогда как S4 может терять сообщения. Для достижения максимальной производительности обмена сообщениями напрямую между задачами, исключая промежуточные очереди, Storm использует оригинальный механизм ZeroMQ, который обнаруживает заторы и изменяет сообщения для оптимизации пропускной способности кластера [2].
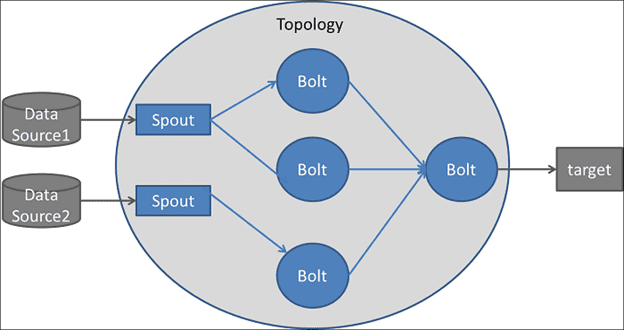
Да будет Шторм: кто, когда и почему выбирает этот фреймворк
Итак, Storm будет отличным выбором для реализации высокоскоростной системы обработки событий, обеспечивающей инкрементные вычисления, в т.ч. по требованию. Однако, если в рамках Шторм необходимо обеспечить сохранение состояния (stateful) и в точности однократную доставку сообщений (exactly once), следует использовать Trident API, который позволяет работать с микропакетами, как Apache Spark.
На практике Apache Storm используется в Big Data системах следующих компаний: Twitter, Yahoo!, Spotify, The Weather Channel, Groupon [3]. Также Сторм хорошо работает в IoT-платформах, например, в качестве простой системы оповещения о событиях по аналогии с Apache Kafka Streams. Таким образом, Шторм хорошо подходит для относительно простых задач потоковой обработки Big Data, но из-за отсутствия гибких возможностей реализации сложной бизнес-логики он не способен заменить собой Apache Spark, Flink и Kafka Streams [4]. В частности, одна из крупнейших ecommerce-платформ, китайская компания Taobao отмечает, что основной проблемой при обработке большого набора данных в режиме реального времени с помощью Шторм является сохранение состояний и результатов. Taobao использует Сторм для анализа статистической информации (логов) следующим образом [5]:
- журналы логов считываются из постоянных Kafka-подобных очередей сообщений в носители данных,
- затем обрабатываются и передаются по топологиям Сторм для вычисления желаемых результатов,
- полученные результаты сохраняются в распределенных базах данных для последующего использования. Количество входных журналов варьируется от 2 миллионов до 1,5 миллиарда каждый день, размер которых составляет до 2 терабайт.
Аналогичным способом Apache Storm используется в компаниях Metamarkets, Impetus Technologies, Wize Commerce, Baidu, Alibaba, Flipboard и множестве других бизнесов по всему миру [5].

Узнайте больше о потоковой обработке больших данных в режиме реального времени на наших специализированных курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Источники
- http://why-not-learn-something.blogspot.com/2015/12/apache-storm-introduction/
- https://www.ibm.com/developerworks/ru/library/os-twitterstorm/index/
- http://datareview.info/article/obrabotka-potokovyx-dannyx-storm-spark-i-samza
- https://medium.com/@chandanbaranwal/spark-streaming-vs-flink-vs-storm-vs-kafka-streams-vs-samza-choose-your-stream-processing-91ea3f04675b
- http://storm.apache.org/Powered-By/

