
Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
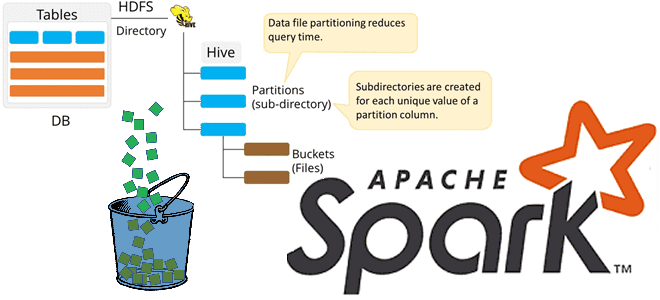
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к сервисам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать...

Сегодня поговорим про бакетирование таблиц в Apache Spark для оптимизации производительности заданий и снижения затрат на кластер при их выполнении. Читайте далее, что такое Bucketing в Spark SQL и как это предотвращает операции перетасовки в приложениях аналитики больших данных. Что такое Bucketing и зачем это нужно в Big Data Бакетирование...

Сегодня в качестве пятничного развлечения для дата-инженеров, разработчиков распределенных приложений, администраторов, аналитиков и других специалистов по большим данным мы приготовили небольшой квиз по Apache Hadoop. Проверьте свое знание главной технологии Big Data, решив кроссворд, филворд и небольшой тест по основным компонентам и главным принципам работы этой платформы хранения и аналитики...

В этой статье рассмотрим, как сделать SQL-запросы к колоночному хранилищу больших данных с поддержкой ACID-транзакций Delta Lake еще быстрее с помощью Apache Presto. Читайте далее про синергию совместного использования Apache Spark и Presto в Delta Lake для ускорения OLAP-процессов при работе с Big Data. Еще раз об OLAP: схема звезды...

Сегодня продолжим разбираться с реализацией CDC-подхода в современных Big Data решениях и погрузимся в Databricks Delta Lake – облачный уровень хранения и аналитики больших данных с поддержкой ACID-транзакций. Читайте далее про переход от ночных ETL-пакетов с Informatica к быстрому обновлению данных в Amazon S3 на конвейере Spark и Kafka. Возможности...

В прошлый раз мы говорили про виды таблиц для быстрой работы с Big Data в Apache Hive. Сегодня поговорим про создание пользовательских функций и их применение в Hive. Читайте далее про особенности создания и применения UDF для работы с Big Data в распределенной платформе Apache Hive. Что такое пользовательские функции...

Чтобы самостоятельное обучение по Хайв стало еще интереснее, сегодня мы предлагаем вам простой тест по основам архитектуры распределенной SQL-платформы Apache Hive, включая элементы, из которых она состоит и их структуру. Тест по основам архитектуры Hive для новичков Для начинающих самостоятельное обучение по Apache Hive мы предлагаем простой интерактивный тест...
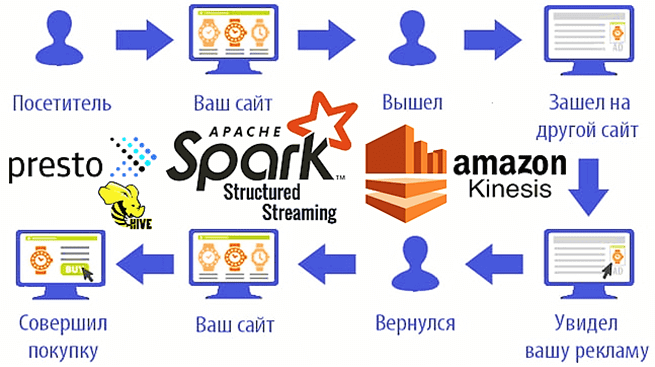
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...