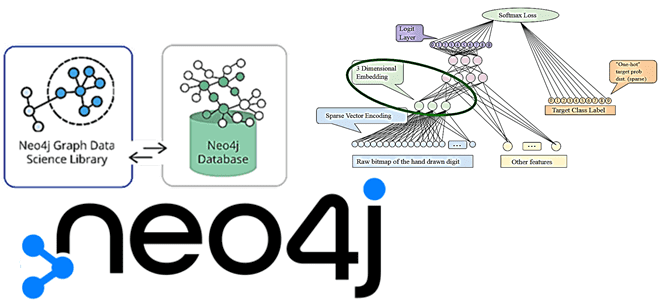
В рамках нашего нового курса графовым алгоритмам в бизнес-приложениях, сегодня разберем эмбеддинг-алгоритмы в библиотеке Graph Data Science СУБД Neo4j: их особенности и возможности практического использования для задач обработки естественного языка (NLP). Также рассмотрим, чем FastRP отличается от GraphSAGE с Node2Vec. NLP, эмбеддинги и Graph Data Science В обработке естественного языка...

В рамках нашего нового курса по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим популярную сегодня тему про невзаимозаменяемые токены в криптовалютах и не только. Пример анализа графа по NFT-транзакциям в графовой СУБД Neo4j с помощью инструкций языка запросов Cypher. Что такое NFT и причем здесь блокчейн с криптовалютами Уникальный или невзаимозаменяемый...

Продвигая наш новый курс по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим применение теории графов к задаче анализа социальных связей на практическом примере возможностей библиотеки Graph Data Science СУБД Neo4j и ее языка запросов Cypher. А также разберем сопутствующую теорию: что такое центральность графа, почему эта мера не подходит для сетей...

Дополняя наши курсы по аналитике больших данных в бизнес-приложениях новыми полезными примерами, сегодня рассмотрим, как Apache Arrow помогает повысить производительность извлечения данных из Neo4j с помощью их колоночного представления и обработки в памяти, а не на диске. Чем neo4j-arrow лучше драйверов Java и Python, а также собственной Neo4j библиотеки Graph...

Сегодня рассмотрим, что такое Great Expectations, чем этот инструмент полезен для специалистов по Data Science и дата-инженеров, а также как связать его с Apache Airflow, какую пользу это принесет в задачах обеспечении качества данных. Также разберем кейс совместного использования Apache Airflow и Great Expectations в компании Vimeo и заглянем под...

MLOps и построение конвейеров машинного обучения – одни из самых актуальных задач современной Data Science. Сегодня рассмотрим, чем совместное использование Apache Airflow и Ray полезно для дата-инженера и ML-разработчика. Читайте далее про кластерное развертывание Python-кода ML-моделей и упрощение ETL-процессов с Apache Airflow и Ray. Apache AirFlow для ML: возможности и...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим работу Data Science исследователей из Пизанского университета и сотрудников крупного ритейлера H&M по анализу данных торгового ассортимента компании с помощью ML-моделей на графах. Читайте далее, как машинное обучение на графовых нейросетях автоматизирует подбор сочетаемых предметов одежды и...
В этой статье поговорим про Viewflow: что такое, как устроено, чем полезно аналитикам данных и Data Scientist’ам. Встречайте новый фреймворк на базе Apache AirFlow от DataCamp – американского edu-стартапа в области ИИ, который упрощает создание и управление материализованными представлениями на SQL, R и Python в концепции low code, т.е. практически...

Отвечая на вопрос, что такое большие данные для чайников, сегодня мы рассмотрим 3 практических примера использования технологий Big Data в малом и среднем бизнесе. Никакой Rocket Science, только понятные кейсы, которые актуальны для любой современной компании, даже если она состоит из пары человек: аналитика больших данных и машинное обучение для...
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...
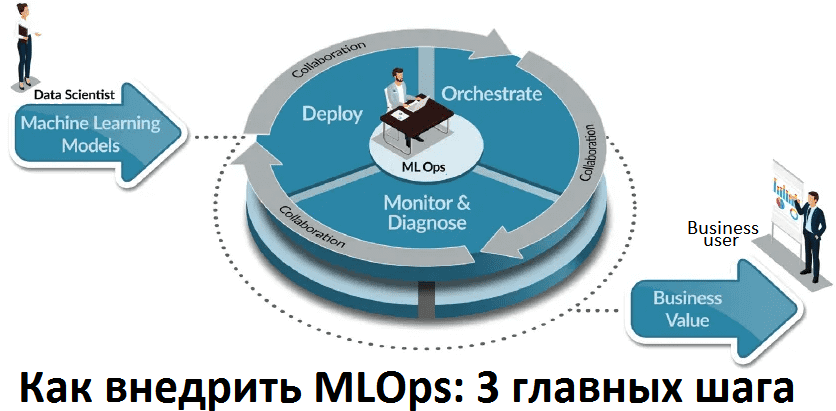
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production). 2 направления для...
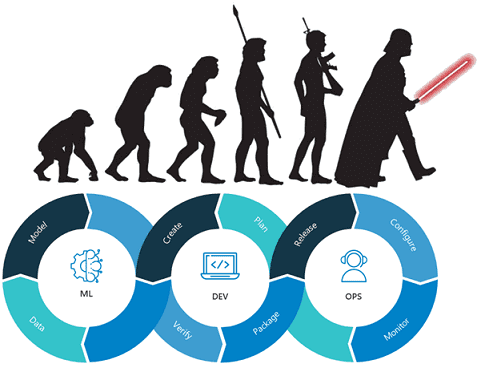
Недавно мы рассказывали про модель зрелости MLOps от Google. Сегодня рассмотрим альтернативную методику оценки зрелости операций разработки и эксплуатации машинного обучения, которая больше похоже на наиболее популярную в области управленческого консалтинга модель CMMI, часто используемую в проектах цифровизации. Читайте далее, по каким критериям измеряется Machine Learning Operations Maturity Model и...
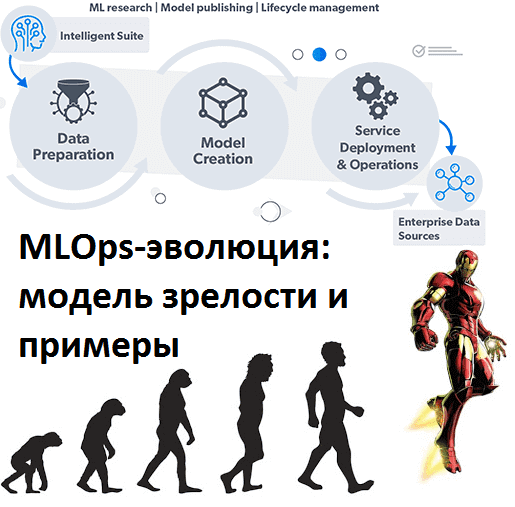
Цифровизация и запуск проектов Big Data предполагают некоторый уровень управленческой зрелости бизнеса, который обычно оценивается по модели CMMI. MLOps также требует предварительной готовности предприятия к базовым ценностям этой концепции. Читайте в нашей статье, что такое Machine Learning Operations Maturity Model – модель зрелости операций разработки и эксплуатации машинного обучения, из...
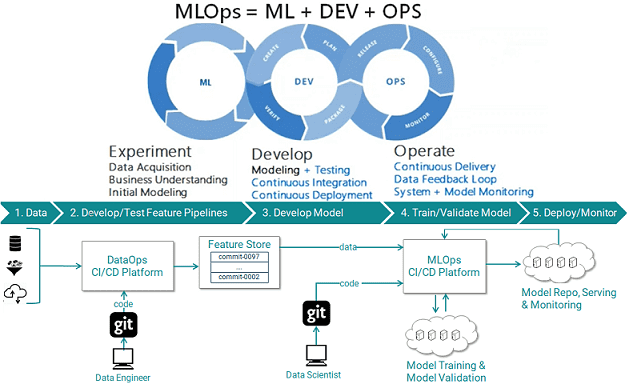
Пока цифровизация воплощает в жизнь концепцию DataOps, мир Big Data вводит новую парадигму – MLOps. Читайте в нашей статье, что такое MLOps, зачем это нужно бизнесу и какие специалисты потребуются при внедрении практик и инструментов сопровождения всех операций жизненного цикла моделей машинного обучения (Machine Learning Operations). Что такое MLOps, почему...
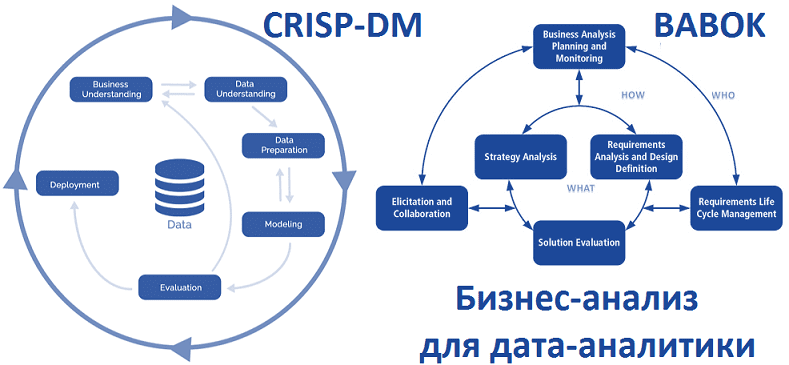
Мы уже рассказывали, что цифровизация и другие масштабные проекты внедрения технологий Big Data должны обязательно сопровождаться процедурами бизнес-анализа, начиная от выявления требований на старте до оценки эффективности уже эксплуатируемого решения. Сегодня рассмотрим, как задачи бизнес-анализа из руководства BABOK®Guide коррелируют с этапами методологии исследования данных CRISP-DM, которая считается стандартом де-факто в...
Недавно мы рассказывали, что такое PySpark. Сегодня рассмотрим, как подключить PySpark в Google Colab, а также как скачать датасет из Kaggle прямо в Google Colab, без непосредственной загрузки программ и датасетов на локальный компьютер. Google Colab Google Colab — выполняемый документ, который позволяет писать, запускать и делиться своим Python-кодом через...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...

В этой статье мы рассмотрим несколько популярных мифов о Data Science и аналитике больших данных (Big Data), разобрав, когда и почему простое использование BI-систем или облачных DaaS-платформ бывает гораздо эффективнее попыток внедрения алгоритмов машинного обучения (Machine Learning) и прочих методов Data Science в операционные и стратегические бизнес-процессы. Почему 80% Data...

CRISP-DM, SEMMA и другие стандарты Data Mining не случайно выделяют подготовку данных в отдельную фазу. Data Preparation - весьма трудоемкий итеративный процесс, который занимает до 80% всех затрат ресурсов и времени в жизненном цикле Data Mining и включает следующие задачи обработки исходных («сырых») данных [1]: Выборка данных – отбор признаков...

Иван Гуз, директор по аналитике и клиентскому сервису Avito, 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе компании [1] рассказал о самых главных проблемах, которые подстерегают исследователя данных на практических проектах и от чего не убережет даже подробно проработанный стандарт CRISP-DM. Из его...