
Сегодня рассмотрим тему анализа и оптимизации бизнес-процессов средствами графовой аналитики больших данных. Как устроены информационные системы класса Process Mining, где еще применяются эти идеи и другие приложения теории графов в бизнесе на примере Python-библиотеки PM4Py. Что такое Process Mining Чтобы понять, как выполняется процесс, бизнес-аналитик строит его схему в виде подробной EPC...
Мы уже рассказывали про важность переносимости ML-моделей, что является одним из аспектов MLOps-концепции. Сегодня разберем, почему популярный формат Pickle не лучший выбор для сохранения модели Machine Learning и что использовать вместо него. Пара достоинств и 7 главных недостатков формата Pickle Согласно концепции MLOps, направленной на сокращение разрыва между различными специалистами,...
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем особенности работы оператора MERGE во встроенном SQL-подобном языке запросов Cypher популярной NoSQL-СУБД Neo4j. Чем он отличается от запросов CREATE и MATCH, а также когда этот оператор более всего полезен. Как работает MERGE-запрос в Neo4j Data Scientist’ы и аналитики данных знают,...
Продолжая разбираться с популярными MLOps-инструментами, сегодня рассмотрим, как MLflow реализует управление версиями модели и данных, а также чем это отличается от DVC. Преимущества и недостатки популярных MLOps-инструментов с возможностями их совместного использования. Плюсы и минусы MLflow для MLOps-инженера Концепция MLOps, направленная на сокращение разрыва между различными специалистами, участвующими в процессах...

Недавно мы писали, от каких факторов зависит выбор подходящего MLOps-инструмента. В продолжение этой темы сегодня специально для ML-инженеров разберем сходства и различия двух самых популярных MLOps-решений: что общего у MLflow и Kubeflow, чем они отличаются и в каких случаях выбирать тот или иной инструмент. Краткий обзор 2-х самых популярных MLOps-решений...
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем сложности рефакторинга графовых моделей в Neo4j и способы их обхода с помощью библиотеки APOC и плагина Liquibase. Что такое Liquibase и как Data Scientist и аналитик данных могут использовать его совместно с Neo4j. Гибкость модели данных и трудности...
Чтобы сделать наши курсы для специалистов по Machine Learning еще более интересными, сегодня рассмотрим 5 лучших практик по использованию популярного MLOps-инструмента. Как Data Scientist может работать с MLflow и сделать свои конвейеры машинного обучения еще более эффективными. Компоненты Mlflow для разработки и развертывания ML-систем Сегодня MLOps считается одним из самых...
В этой статье для специалистов по Machine Learning рассмотрим, от каких факторов зависит выбор MLOps-средств и как сделать его наиболее верным способом. Когда развертывание продукта с открытым исходным кодом или индивидуального решения на собственной инфраструктуре лучше готового инструмента в облаке и почему часто бывает наоборот. 3 главных фактора выбора MLOps-решений...

В линейке продуктов Databricks не только облачная платформа аналитики больших данных на базе Apache Spark. В портфолио компании также присутствует популярный MLOps-инструмент под названием MLflow, последний релиз которого (1.27.0) вышел 1 июля 2022 года. Однако, разработчики уже анонсировали в мажорный выпуск новой версии MLOps-фреймворка с открытым исходным кодом. Читайте далее,...
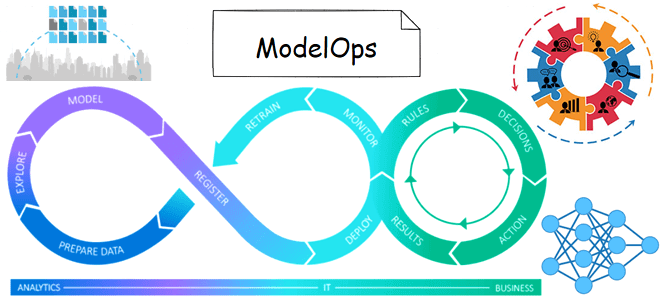
Пока инженеры данных и специалисты по Data Science привыкали к MLOps, начав понимать важность и необходимость этой концепции непрерывной разработки и эксплуатации систем машинного обучения, в Data Science появился новый термин с модным –Ops окончанием. Разбираемся, что такое ModelOps, чем это отличается от MLOps и как применить его на практике....

Сегодня рассмотрим несколько полезных приемов по работе с Apache Hive, которые пригодятся инженеру данных и специалисту по Data Science в проектах аналитики больших данных. Как разделить и сегментировать таблицы, зачем изменять значение конфигурации памяти этапов MapReduce, чем полезна автоматическая обработка асимметрии данных и еще пара лайфхаков для ускорения выполнения SQL-запросов...
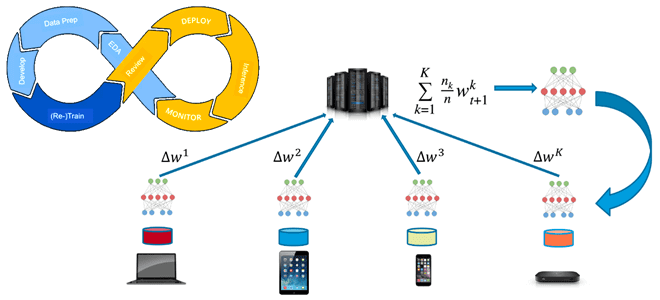
Сегодня в области Data Science именно машинное обучение является такой одновременно научной и прикладной сферой, где постоянно возникают новые прорывные идеи и технологии их реализации. Одной из самых популярных ML-тем сегодня считается федеративное машинное обучение. Что это такое и при чем здесь хайповый MLOps, читайте далее. Что такое федеративное машинное...

Сегодня разберемся, когда для Data Science-проектов вместо Apache Spark, самого популярного вычислительного движка аналитики больших данных, стоить выбрать Dask – легковесную Python-библиотеку для параллельных вычислений. И, наоборот, в каких случаях инженер данных и Data Scientist получают преимущества, выбирая Spark. Что такое Dask и зачем он нужен Data Scientist’у Прежде чем...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое связность в графе, зачем вычислять компоненты связности и как это сделать для ориентированных графов. Продемонстрируем все вычисления с помощью методов Python-библиотеки Networkx в Google Colab. Основы теории графов и применения Networkx в Google...
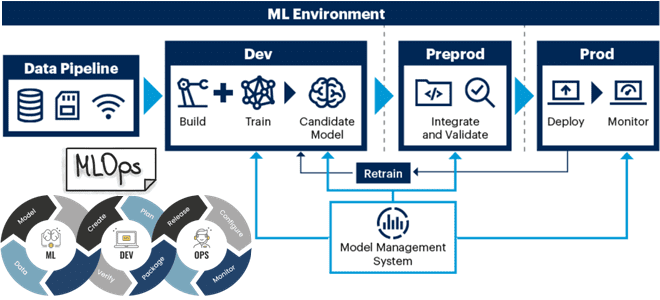
Что и насколько часто меняется в системах машинного обучения, почему необходимо отслеживать эти изменения и как MLOps помогает справиться с управлением ML-моделями, данными, кодом и инфраструктурой развертывания. Почему стек технологий MLOps такой разношерстный и какие инструменты выбирать для практического использования. MLOps для решения дрейфа данных и других проблем ML-систем Машинное...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...
Что не так с датасетами в системах машинного обучения, с какими трудностями сталкиваются аналитики, инженеры данных и специалисты по Data Science при внедрении MLOps, почему важна согласованность различных информационных хранилищ, зачем и как внедрять оперативный мониторинг за качеством данных. Разбираем трудности разработки и поддержки Machine Learning в production. 5 проблем...
Зачем нужен мониторинг ML-систем в production, чем он отличается от простого отслеживания метрик ПО и при чем здесь MLOps. Как настроить телеметрию ML-приложений в New Relic: 5 простых шагов для специалистов по Machine Learning и дата-инженеров. Зачем нужен мониторинг ML-систем и при чем здесь MLOps В реальных системах машинного обучения...
Что такое непрерывное машинное обучение, как оно работает и при чем здесь MLOps. Почему сложно вести разработку ML-моделей в стиле CI/CD и как CML помогает обойти эти ограничения. Автоматизация процессов непрерывной интеграции и доставки с помощью open-source CLI-инструмента от Iterative.ai. Трудности CI/CD в Machine Learning и MLOps Поддерживаемые DevOps-концепцией идеи...
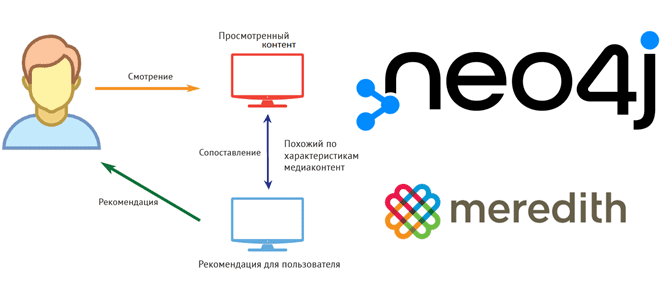
Развивая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим американского медиаконгломерат Meredith Corporation по персонализации пользовательских профилей с помощью графовой СУБД Neo4j и алгоритма непересекающихся множеств (Union-Find). Постановка задачи: сложности идентификации анонимных клиентов Различными контент-продуктами конгломерата Meredith Corporation ежемесячно пользуется более 180 миллионов человек через приложения,...