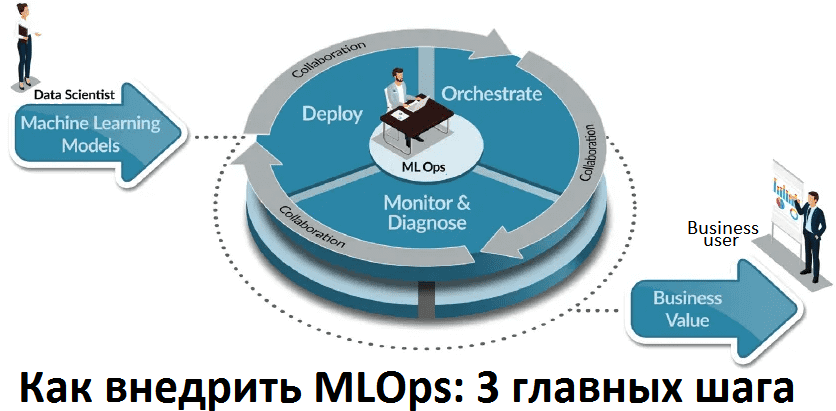
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production). 2 направления для...
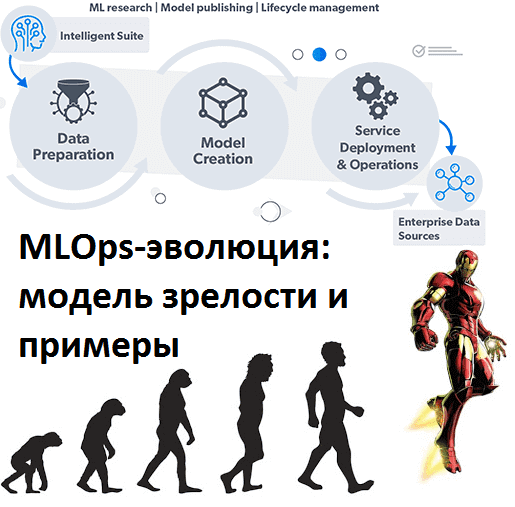
Недавно мы рассказывали про модель зрелости MLOps от Google. Сегодня рассмотрим альтернативную методику оценки зрелости операций разработки и эксплуатации машинного обучения, которая больше похоже на наиболее популярную в области управленческого консалтинга модель CMMI, часто используемую в проектах цифровизации. Читайте далее, по каким критериям измеряется Machine Learning Operations Maturity Model и...
Цифровизация и запуск проектов Big Data предполагают некоторый уровень управленческой зрелости бизнеса, который обычно оценивается по модели CMMI. MLOps также требует предварительной готовности предприятия к базовым ценностям этой концепции. Читайте в нашей статье, что такое Machine Learning Operations Maturity Model – модель зрелости операций разработки и эксплуатации машинного обучения, из...
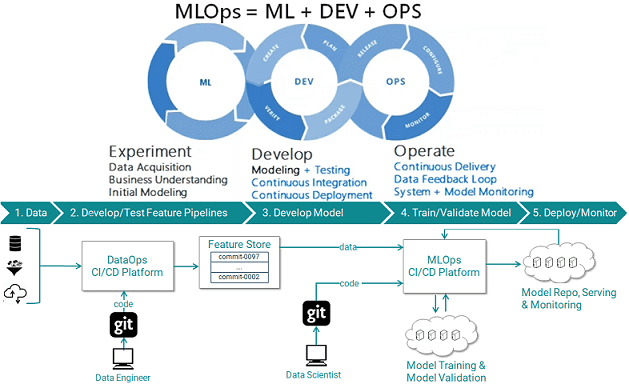
Пока цифровизация воплощает в жизнь концепцию DataOps, мир Big Data вводит новую парадигму – MLOps. Читайте в нашей статье, что такое MLOps, зачем это нужно бизнесу и какие специалисты потребуются при внедрении практик и инструментов сопровождения всех операций жизненного цикла моделей машинного обучения (Machine Learning Operations). Что такое MLOps, почему...
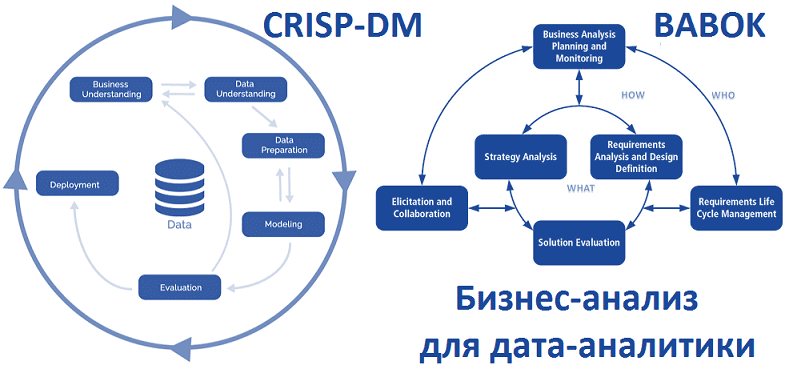
Мы уже рассказывали, что цифровизация и другие масштабные проекты внедрения технологий Big Data должны обязательно сопровождаться процедурами бизнес-анализа, начиная от выявления требований на старте до оценки эффективности уже эксплуатируемого решения. Сегодня рассмотрим, как задачи бизнес-анализа из руководства BABOK®Guide коррелируют с этапами методологии исследования данных CRISP-DM, которая считается стандартом де-факто в...
Недавно мы рассказывали, что такое PySpark. Сегодня рассмотрим, как подключить PySpark в Google Colab, а также как скачать датасет из Kaggle прямо в Google Colab, без непосредственной загрузки программ и датасетов на локальный компьютер. Google Colab Google Colab — выполняемый документ, который позволяет писать, запускать и делиться своим Python-кодом через...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...

В этой статье мы рассмотрим несколько популярных мифов о Data Science и аналитике больших данных (Big Data), разобрав, когда и почему простое использование BI-систем или облачных DaaS-платформ бывает гораздо эффективнее попыток внедрения алгоритмов машинного обучения (Machine Learning) и прочих методов Data Science в операционные и стратегические бизнес-процессы. Почему 80% Data...

CRISP-DM, SEMMA и другие стандарты Data Mining не случайно выделяют подготовку данных в отдельную фазу. Data Preparation - весьма трудоемкий итеративный процесс, который занимает до 80% всех затрат ресурсов и времени в жизненном цикле Data Mining и включает следующие задачи обработки исходных («сырых») данных [1]: Выборка данных – отбор признаков...

Иван Гуз, директор по аналитике и клиентскому сервису Avito, 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе компании [1] рассказал о самых главных проблемах, которые подстерегают исследователя данных на практических проектах и от чего не убережет даже подробно проработанный стандарт CRISP-DM. Из его...