 786
786 
Содержание
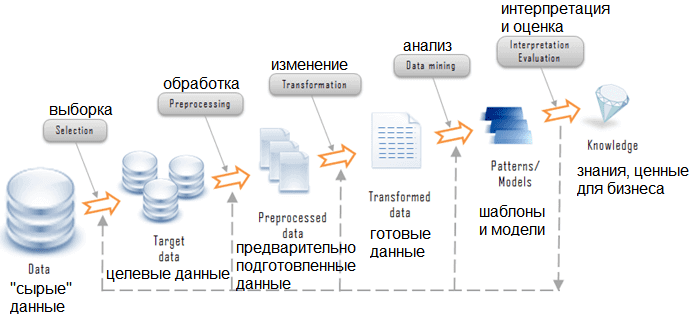
CRISP-DM, SEMMA и другие стандарты Data Mining не случайно выделяют подготовку данных в отдельную фазу. Data Preparation — весьма трудоемкий итеративный процесс, который занимает до 80% всех затрат ресурсов и времени в жизненном цикле Data Mining и включает следующие задачи обработки исходных («сырых») данных [1]:
- Выборка данных – отбор признаков (features или предикторов) и объектов с учетом их релевантности для целей Data Mining, качества и технических ограничений (объема и типа) [2];
- Очистка данных – удаление опечаток, некорректных значений (например, число в строковом параметре и пр.), отсутствующих значений (Missing values или NA), исключение дублей и разных описаний одного и того же объекта, восстановление уникальности, целостности и логических связей [3];
- Генерация признаков – создание производных признаков и их преобразование в векторы для модели Machine Learning, а также трансформация для повышения точности алгоритмов машинного обучения [4];
- Интеграция – слияние данных из различных источников (информационных систем, таблиц, протоколов и пр.), включая их агрегацию, когда новые значения вычисляются путем суммирования информации из множества существующих записей [2];
- Форматирование – синтаксические изменения, которые не меняют значение данных, но требуются для инструментов моделирования, например, сортировка в определенном порядке или удаление ненужных знаков препинания в текстовых полях, обрезка «длинных» слов, округление вещественных чисел до целого и т.д. [2].

Почему нужно готовить данные к моделированию?
Далеко не всегда исходные данные получены из корпоративного хранилища или витрины данных и имеют четкую структуру. А, вопреки общественному мнению, машинное обучение не работает автономно и самостоятельно. Для адекватного функционирования этого инструмента, как и любого ИТ-средства, необходимы четко определенные исходные данные и инструкции. Невозможно загрузить в алгоритм Machine Learning все накопленные большие данные разных форматов и получить на выходе корректные результаты. Кроме того, исходные данные зачастую искажены и ненадежны: в них могут присутствовать значения, выходящие за границы допустимых диапазонов (шумы), аномальные значения (выбросы), а также пропуски (отсутствие значений).
К тому же, часто возникает задача предварительной подготовки исходных данных. Например, если стоит задача определения тональности клиентских отзывов, необходимо сначала разбить текст на смысловые выражения (токены), «оцифровать» слова и превратить их в числовые вектора. В географических данных могут встречаться опечатки в адресах и ошибки определения координат из-за особенностей местности, в частности, в подвальных помещениях, среди холмов и т.д. [4]. В числовых рядах могут встречаться значения, выходящие за пределы возможного диапазона, например, цифра 7 в пятибальной шкале оценок. Также числовые значения исходных данных могут сильно варьироваться по абсолютным величинам: от нескольких сотых процентов до десятков тысяч единиц [5]. Подобные погрешности исказят результаты моделирования и не позволят получить модель машинного обучения с приемлемым качеством.
Как Data Scientist готовит данные: методы и средства Data Preparation
Перед тем, как применять алгоритмы машинного обучения, данные необходимо преобразовать в табличное представление, которое наиболее распространено в Machine Learning и Data Mining. Получив файл с «сырыми» данными, например, в формате CSV, аналитик сначала просматривает его, чтобы понять характер записей (строк), а также смысл, тип и диапазон значений признаков (столбцов). Затем data scientist формирует выборку (dataset, датасет) – отбирает данные, которые потенциально имеют отношение к проверяемой гипотезе машинного обучения. Например, по номеру телефона можно определить регион абонента, чтобы предложить пользователю обратиться в местный филиал компании.
Далее выполняется очистка данных с помощью встроенных инструментов программных средств Big Data, например Hive, Azure, SQL Server Data Tools и пр. [6]. Иногда исследователь данных самостоятельно пишет скрипт, например, на языке R или Python, чтобы исправить опечатки в текстовых значениях, в частности, «ординатор» вместо «ординатр» и т.д. Аналогично, с помощью встроенных команд среды обработки данных или собственного скрипта, выполняется конвертация типов данных, агрегация признаков, заполняются отсутствующие значения, исправляются шумы и выбросы. Для числовых переменных применяется нормализация данных, чтобы привести их к одинаковой области изменения и использовать их вместе в одной модели Machine Learning [5]. Как правило, нормализация данных означает преобразование исходных числовых значений в новые в диапазоне от 0 до 1, основываясь на начальном минимуме и максимуме.
Определив независимые предикторы и сгенерировав на их основе целевые признаки, data scientist снова проверяет полученный датасет, чтобы исключить мультиколлинеарность факторов, которая повышает размерность модели Machine Learning и может стать причиной ее переобучения. Для этого используются методы отбора признаков (Feature Selection), в частности, главных компонент и ридж-регрессия (ridge regression).
Интеграция и форматирование датасета, как правило, выполняются средствами СУБД для Big Data или инструментами, предназначенными для подобных операций: IBM SPSS, SAS. Все эти действия, от выборки до сортировки данных, проводятся несколько раз, до тех пор, пока dataset не станет пригодным для моделирования, с учетом особенностей выбранных алгоритмов машинного обучения и проверяемой гипотезы.
Практический пример анализа данных временных рядов средствами Python и Apache Spark смотрите в нашей новой статье.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
16 марта, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Как на практике подготовить данные к моделированию для использования в системах аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://habr.com/ru/company/lanit/blog/328858/
- http://www.machinelearning.ru/wiki/index.php?title=CRISP-DM/Data_Preparation
- http://iso.ru/ru/press-center/journal/1789.phtml
- https://m.habr.com/ru/company/ods/blog/325422/
- https://neuronus.com/theory/nn/925-sposoby-normalizatsii-peremennykh/
- https://docs.microsoft.com/ru-ru/azure/machine-learning/team-data-science-process/prepare-data

