Сегодня реализуем простой ETL-конвейер для реляционной СУБД PostgreSQL, запустив Apache AirFlow в интерактивной среде Google Colab. Пример DAG из 3-х задач: получить количество строк в одной из таблиц БД, сгенерировать новые строки и записать их, не нарушив ограничений уникальности первичного ключа. Постановка задачи Возьмем в качестве примера базу данных для...
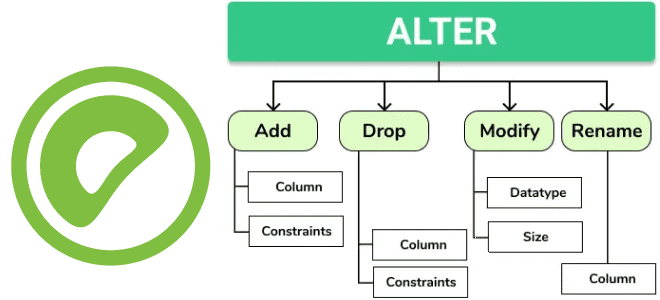
Какие команды изменения таблиц добавлены в 7-ю версию Greenplum и чем они полезны дата-инженеру. Разбираемся с новыми функциями: как добавить столбец, изменить его тип, кодировку хранения и перезаписать несколько таблиц одной командой. Добавление столбца О новых функциях работы с партиционированаными таблицами в Greenplum 7 мы уже писали. В частности, Greenplum...
Чем полезны новые фичи Apache Spark SQL, выпущенные в релизе 3.4. Разбираемся с псевдонимами столбцов и параметризованными SQL-запросами на простых примерах, запуская Spark-приложение в Google Colab. Псевдонимы столбцов Хотя с момента выхода Apache Spark 3.4 в апреле 2023 года, о чем мы писали здесь, прошло почти полгода, возможность ссылаться на...
Как включить отрицательные веса в поиск пути, выявлять центральные и периферийные кластеры на основе заданной плотности, а также делать выборки из больших графов для масштабирования машинного обучения. Знакомимся с графовыми алгоритмами, недавно добавленными в библиотеку Neo4j Graph Data Science 2.4: декомпозиция K-ядра, алгоритм кратчайшего пути Беллмана-Форда и случайное блуждание с...

Недавно мы писали про уязвимости Apache Kafka, обнаруженные и исправленные в 2023 и 2022 гг. Сегодня рассмотрим, как одна из них устранена в отладочном релизе 3.5.1, опубликованного 21 июля 2023 года. А также познакомимся с другими улучшениями и исправлениями ошибок этого выпуска. Обновления Apache Kafka 3.5.1 Релиз Apache Kafka 3.5.1...
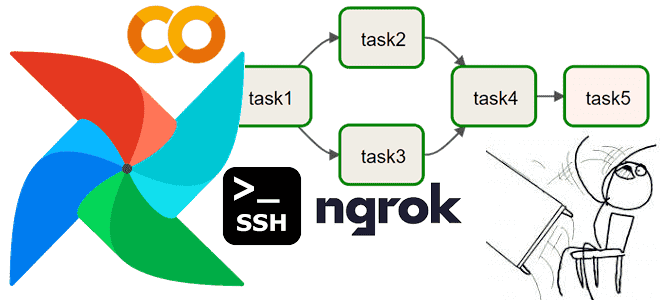
Медленно, муторно, небезопасно: что не так с запуском Apache AirFlow в интерактивной среде Google Colab и можно ли с этим смириться. Разбираем на личном опыте. Трудности работы с Apache AirFlow в среде Google Colab О том, что можно настроить AirFlow в Google Cloud Platform, и запускать DAG-файлы из Colab, используя...

Что такое спекулятивное выполнение заданий в Apache Flink, какой планировщик его поддерживает, какие конфигурации нужно настроить для его эффективного использования и зачем при этом переопределять поведение генератора разделений потокового источника данных. Что такое спекулятивное выполнение заданий Apache Flink Распределенная природа Apache Flink приводит к тому, что приложения, созданные с помощью...

От межсайтового скриптинга до внедрения вредоносного кода: какие проблемы информационной безопасности были обнаружены и исправлены в Apache Spark в 2023, 2022 и 2021 годах. Последние известные и исправленные проблемы информационной безопасности Apache Spark Недавно мы писали о механизмах обеспечения информационной безопасности в Apache Spark. Однако, несмотря на наличие этих средств,...
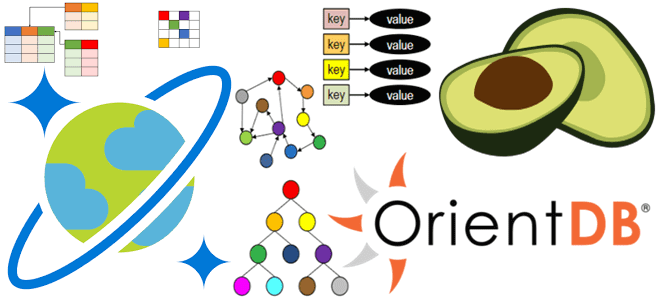
Как устроены по-настоящему мультимодельные базы данных, чем они отличаются от реляционных и NoSQL-СУБД, а также какова истинная природа универсального подхода к хранению и оперированию данными. Разбираемся на примере ArangoDB, OrientDB и Cosmos DB. Что такое мультимодельная СУБД и зачем она нужна Любая технология предназначена, прежде всего, для решения конкретных проблем,...
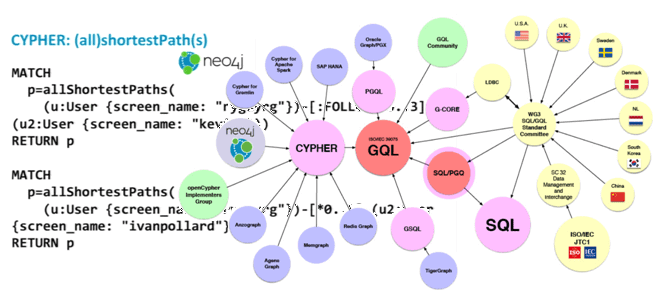
Кто и зачем создает аналог SQL для запросов к графовым базам данных, когда выйдет официальная версия стандарт и при чем здесь Cypher из Neo4j. Что такое GQL и кто его разрабатывает В рамках продвижения нашего курса по графовым алгоритмам в бизнес-приложениях мы часто рассказываем про инструменты хранения и анализа графовых...