
Сегодня рассмотрим основные преимущества ClickHouse – аналитической СУБД от Яндекса для обработки запросов по структурированным большим данным в реальном времени. Читайте в нашей статье, чем еще хорош Кликхаус, кроме высокой скорости, и почему эту систему так любят аналитики, разработчики и администраторы Big Data. Чем хорош ClickHouse: главные преимущества Напомним, основным...

Интеграционный движок Kafka Engine для потоковой загрузки данных в ClickHouse из топиков Кафка – наиболее популярный инструмент для связи этих Big Data систем. Однако, он не единственное средство интеграции Кликхаус с Apache Kafka. Сегодня рассмотрим, как еще можно организовать потоковую передачу больших данных от самого популярного брокера сообщений в колоночную...

Вчера мы рассматривали интеграцию ClickHouse с Apache Kafka с помощью встроенного движка. Сегодня поговорим про проблемы, которые могут возникнуть при его практическом использовании и разберем способы их решения для корректной связи этих Big Data систем. Почему случаются тайм-ауты: многопоточность и безопасность Напомним, интеграцию ClickHouse и Kafka обеспечивает встроенный движок (engine),...

В этой статье рассмотрим интеграцию ClickHouse с Apache Kafka: когда и зачем она нужна, как связать эти две Big Data системы, каковы ограничения и недостатки существующих способов и каким образом их можно обойти. Также разберем, почему кластер Кликхаус использует Zookeeper и что такое материализованное представление таблицы Кафка. Big Data маркетинг,...

Мы уже рассказывали про интеграцию Tarantool с Apache Kafka на примере Arenadata Grid. Сегодня рассмотрим, как интегрировать Кафка с MPP-СУБД Greenplum и каковы ограничения каждого из существующих способов. Читайте в сегодняшнем материале, что такое GPSS, PXF и при чем тут Docker-контейнер с коннектором Кафка для Arenadata DB. IoT и не...

Сегодня рассмотрим ключевые достоинства и недостатки резидентных СУБД для больших данных на примере Tarantool. Читайте в нашей статье про основные сценарии использования In-Memory Database (IMDB) в области Big Data с конкретными кейсами из реального бизнеса от Альфа-Банка, Аэрофлота, Тинькофф-Банка и Мегафона. Где и как используются In-Memory в Big Data: 4...
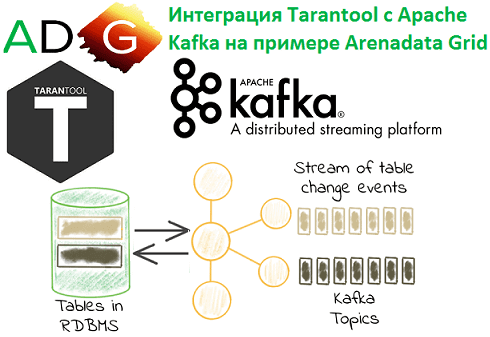
Продолжая разбираться с In-Memory СУБД Tarantool и Arenadata Grid, сегодня рассмотрим, как эти резидентные базы данных интегрируются с Apache Kafka. Читайте в нашей статье, что такое коннекторы и процессоры, а также как записать в топик Кафка сообщение, SQL-запрос или часть таблицы. Arenadata Grid и Apache Kafka: коннектор + процессоры Напомним,...

Вчера мы разбирали In-Memory СУБД на примере Tarantool. Сегодня поговорим про Arenadata Grid: что это такое, чем хороша эта база данных, каким образом она связана с Тарантул и чем от него отличается. Также рассмотрим, как Arenadata Grid интегрируется с внешними Big Data системами, в т.ч. основными компонентами инфраструктуры Apache Hadoop...

В этой статье мы рассмотрим резидентные (In-Memory) базы данных на примере Tarantool и Arenadata Grid: что это, как они работают и где используются. Еще поговорим, каким образом эти Big Data системы могут ускорить работу распределенных приложений без замены существующих СУБД, а также при чем здесь промышленный интернет вещей и экосистема...
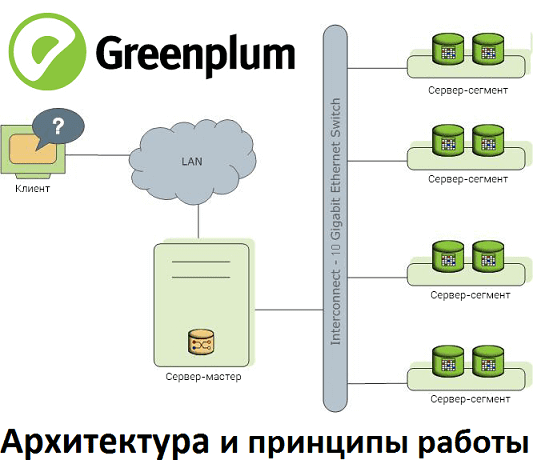
В этом материале рассмотрим реализацию массово-параллельной архитектуры для хранения и аналитической обработки больших данных на примере популярной Big Data СУБД Greenplum. Прочитав эту статью, вы поймете, почему MPP-базы потребляют много ресурсов и как связано число сегментов со скоростью работы кластера. MPP, Greenplum и PostgreSQL Напомним, СУБД Greenplum – это типичный представитель...