
В этой статье поговорим про интеграцию данных с помощью CDC-подхода и репликацию SQL-таблиц из корпоративной СУБД в несколько разных удаленных хранилищ в реальном времени с применением Apache Kafka и Debezium, развернутых в Kafka Connect и Confluent Cloud. Постановка задачи: CDC с Big Data в реальном времени Рассмотрим кейс, который часто...

Чтобы сделать ваше самостоятельное обучение Apache Kafka и прочим технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам открытый интерактивный тест по этой платформе потоковой обработки событий. Ответьте на 10 простых вопросов и узнайте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного...

Вчера мы говорили про ускорение аналитики больших данных в конвейере из множества заданий Apache Spark. Продолжая речь про обучение инженеров данных, сегодня рассмотрим, как снизить стоимость выполнения Spark-приложений, сократив накладные расходы на обработку Big Data и повысив эффективность использования кластерной инфраструктуры. Экономика Big Data систем: распределенная разработка и операционные затраты...

Сегодня рассмотрим несколько простых способов ускорить обработку больших данных в рамках конвейера задач Apache Spark. Читайте далее про важность тщательной оценки входных и выходных данных, рандомизацию рабочей нагрузки Big Data кластера и замену JOIN-операций оконными функциями. Оптимизируй это: почему конвейеры аналитической обработки больших данных с Apache Spark замедляются Обычно со...

В рамках обучения инженеров больших данных, вчера мы рассказывали о новой версии Apache AirFlow 2.0, вышедшей в декабре 2020 года. Сегодня рассмотрим особенности перехода на этот релиз: в чем сложности миграции и как их решить. Читайте далее про сохранение кастомизированных настроек, тонкости работы с базой метаданных и конфигурацию для развертывания...

В конце 2020 года вышел мажорный релиз Apache AirFlow, основные фишки которого мы рассмотрим в этой статье. Читайте далее про 10 главных обновлений Apache AirFlow 2.0, благодаря которым этот DataOps-инструмент для пакетных заданий обработки Big Data стал еще лучше. 10 главных обновлений Apache AirFlow 2.0 Напомним, разработанный в 2014 году...

Совместное использование Apache Kafka и Spark очень часто встречается в потоковой аналитике больших данных, например, в прогнозировании пользовательского поведения, о чем мы рассказывали вчера. Однако, временные метки (timestamp) в приложении Spark Structured Streaming могут отличаться от времени события в топике Kafka. Читайте далее, почему это случается и какие подходы к...
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
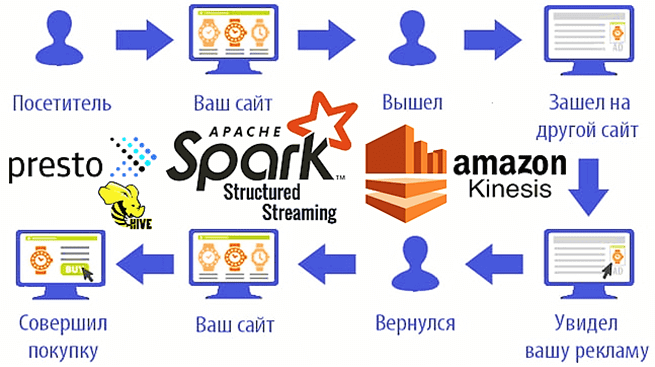
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

Продолжая разговор про фиксацию заданий Apache Spark при работе с облачными хранилищами больших данных, сегодня подробнее рассмотрим, насколько эффективны commit-протоколы экосистемы Hadoop, предоставляемые по умолчанию, и почему известный разработчик Big Data решений, компания Databricks, разработала собственный алгоритм. Читайте далее про сравнение протоколов фиксации заданий в Spark-приложениях: результаты оценки производительности и...