
Недавно мы рассказывали про KafkaJS – клиент Apache Kafka для Node.js, который отличается небольшим размером и простым развертыванием с удобным API. Сегодня рассмотрим еще пару полезных инструментов визуализации данных о Kafka-кластере на базе KafkaJS и Prometheus. Читайте далее, что такое FlowKat и Monokl, а также зачем они нужны дата-инженеру, разработчику...
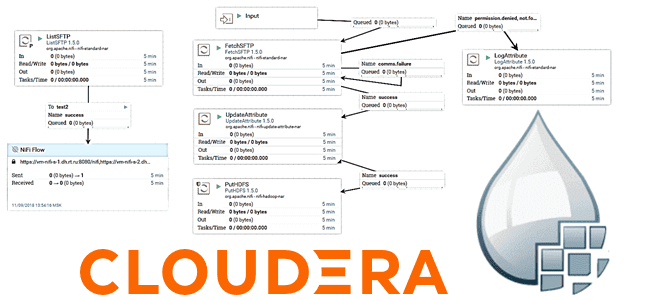
В рамках обучения дата-инженеров сегодня заглянем под капот системы Cloudera Flow Management, которая является частью платформы Cloudera DataFlow и основана на Apache NiFi. Вас ждет разбор основных концепций жизненного цикла потоковой разработки и их реализация в Apache NiFi с практическими примерами и рекомендациями по применению. Что такое Cloudera Flow Management...

Хотя наши практические курсы по Greenplum и Arenadata DB больше ориентированы на аналитиков и дата-инженеров, чем на администраторов, в программы обучения также включены важные сведения по настройке этих MPP-СУБД. В этой статье мы собрали лучшие практики системного конфигурирования кластера Greenplum, которые помогут повысить эффективность аналитики больших данных в этой Big...
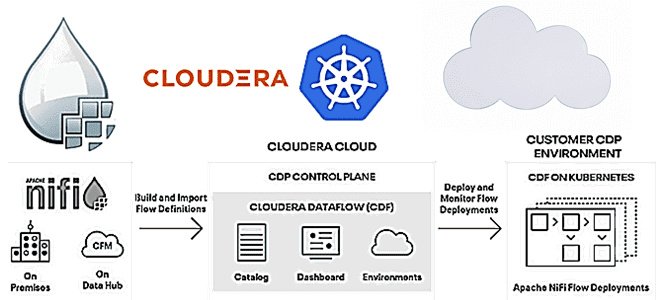
Чтобы сделать наши курсы по Apache NiFi для дата-инженеров еще более полезными, сегодня рассмотрим новые возможности последнего релиза Cloudera Flow Management 2.1.1 на базе этого фреймворка. Выпущенная в апреле 2021 года, платформа Cloudera Flow Management в составе публичного и частного облака предоставляет Apache NiFi версии 1.13.2, включая дополнительные компоненты, а...
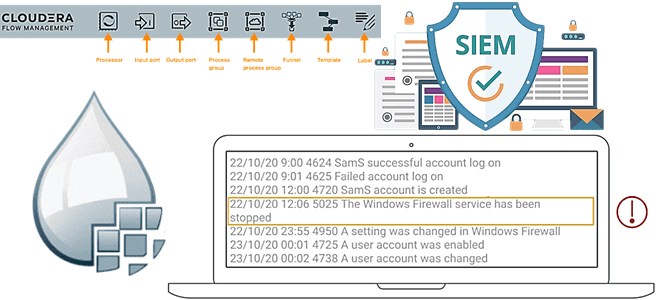
В этой статье для дата-инженеров рассмотрим, что такое Cloudera Flow Management и как это позволяет ускорить аналитику больших данных в кейсах информационной безопасности. Читайте далее о преимуществах SIEM-анализа, преобразования и распределения security-событий с помощью Apache NiFi и его легковесного агента MiNiFi для устройств интернета вещей (Internet Of Things, IoT). Что...
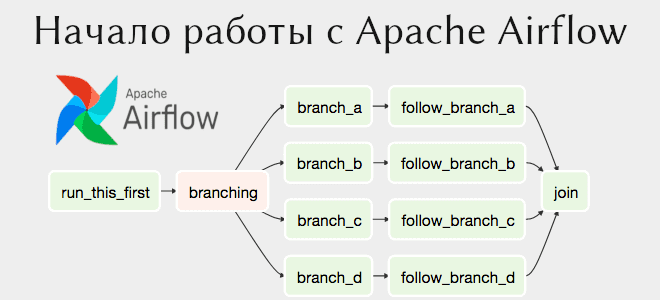
В прошлой статье мы рассмотрели установку Apache Airflow на свой компьютер. Данная платформа предназначена для планирования задач, например, выполнения скриптов Bash и Python в заданное время, в заданной последовательности. Сегодня на примере выполнения двух Bash-команд расскажем, как создать свой первый граф. Читайте в этой статье: связи между задачами, создание графа...

Apache Airflow имеет множество зависимостей, поэтому установка может быть проблематичной. В отличие от 1-й версии, Airflow 2 устанавливается гораздо проще. В этой статье разберем установку Apache Airflow через пакетный менеджер pip и через Docker. Локальная установка Apache Airflow Apache Airflow был протестирован на: Python: 3.6, 3.7, 3.8, 3.9 СУБД (Система...
В рамках программы курсов по Greenplum и Arenadata DB, сегодня рассмотрим важную для разработчиков и администраторов тему об особенностях оптимизатора SQL-запросов GPORCA, который ускоряет аналитику больших данных лучше встроенного PostgreSQL-планировщика. Читайте далее, как выбирать ключ дистрибуции, почему для GPORCA важна унифицированная структура многоуровневой партиционированной таблицы и каким образом оптимизаторы обрабатывают...

YARN считается самым распространенным диспетчером ресурсов в кластерах Apache Hadoop и Spark, отвечая за выделение ресурсам распределенным приложениям. Сегодня в рамках обучения дата-инженеров и администраторов Hadoop рассмотрим достоинства и недостатки 3-х вариантов планирования ресурсов в YARN. Читайте далее, что такое иерархия очереди и как вычисляется ее мгновенная справедливая доля. Планирование...

Apache Storm обычно сравнивают со другими популярными фреймворками потоковой аналитики больших данных: Spark и Flink. Однако для несложной обработки событий дата-инженер может заменить эти платформы более легким инструментом маршрутизации потоковых данных в виде Apache NiFi. Сегодня сравним Apache NiFi co Storm и разберем практический пример, когда предпочтительнее именно его для...