Недавно мы писали об изменении статуса и улучшении протокола KRaft в Apache Kafka 3.3. Сегодня погрузимся в эту тему чуть глубже и рассмотрим, как отказ от Zookeeper влияет на количество разделов и возможность одного и того же кластера Kafka с одним набором топиков обслуживать разные типы приложений в различных бизнес-сценариях....
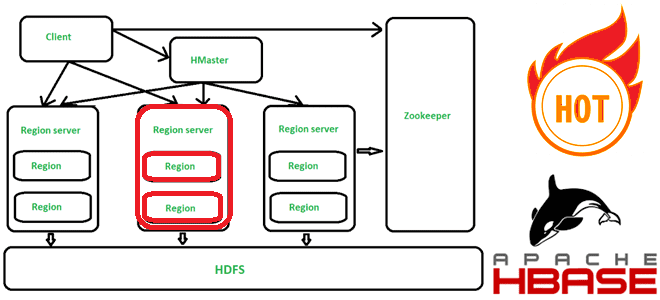
Что такое горячие точки в Apache HBase, почему они возникают, чем опасны и как их избежать. Для этого заглянем под капот NoSQL-хранилища, чтобы разобраться с особенностями хранения данных по ключу строки. Что такое горячие точки в кластере Apache HBase и почему они случаются Apache HBase представляет собой колоночно-ориентированное мультиверсионное хранилище...

23 января 2023 года вышел очередной релиз самой популярной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.3.2: готовность протокола KRaft, новый API для метрик, разделитель по умолчанию для записей без ключа, исправления и улучшения, важные для дата-инженера и администратора кластера. Apache Kafka 3.3.2: главные новинки и изменения Минорный...
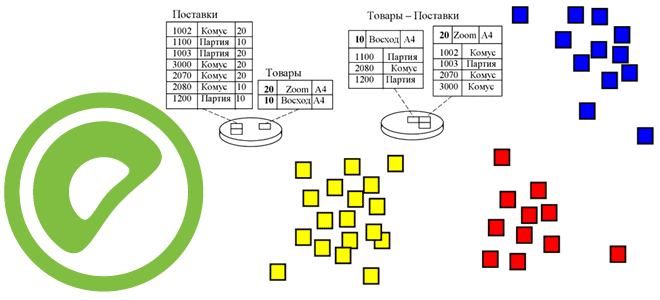
Что означает кластеризация таблиц в PostgreSQL, как это связано с индексацией и очисткой данных, чем полезно применение команды CLUSTER для AO/CO-таблиц в Greenplum 7, а также какой SQL-запрос поможет найти все кластеризованные таблицы в текущей базе данных. Как работает кластеризация таблиц в PostgreSQL Будучи основанной на объектно-реляционной базе данных PostgreSQL,...

Политики хранения, сжатия и очистки данных в топиках Apache Kafka: какие конфигурации нужно настроить, чтобы работать с файлами распределенных логов наиболее эффективно. Ликбез для администратора кластера Kafka и дата-инженера. Хранение данных в Apache Kafka Мы уже писали, что топик в Apache Kafka представляет собой не физическое, а логическое хранение данных....

Сегодня рассмотрим, как оптимизировать потребление памяти в приложениях Apache Flink, разобрав основные принципы работы и конфигурации настройки памяти этого вычислительного фреймворка. А также перечислим типовые ошибки, с которыми дата-инженер может столкнуться при разработке и эксплуатации Flink-приложений Компоненты памяти в Apache Flink Apache Flink обеспечивает эффективные рабочие нагрузки поверх JVM, строго...

Что такое SQL-оператор VACUUM, зачем эта команда нужна в Greenplum и как она работает. Разбираемся с таблицами системного каталога и тонкостями ускорения SQL-запросов в самой популярной MPP-СУБД. Что такое сборка мусора в Greenplum и PostgreSQL Напомним, в объектно-реляционной базе данных PostgreSQL, на которой основана MPP-СУБД Greenplum, о чем мы писали...

Мы уже писали про некоторые новинки свежего релиза Greenplum 7 здесь и здесь. Разбираемся, что еще полезного появилось в бета-версии, выпущенной 15 декабря 2022 года. А также рассмотрим, каковы ограничения этого выпуска и почему его пока нельзя использовать в production. Новые функции PostgreSQL Помимо возможности применения команды ALTER TABLE к...

Продолжая разбираться с новинками Greenplum версии 7, выпущенной в середине декабря 2022 года, сегодня рассмотрим, как теперь работает SQL-команда с DML-запросов изменения таблиц ALTER TABLE. Как динамически менять структуру и характеристики таблицы даже тех, что предназначены только для добавления с новыми методами доступа. Модели таблиц в Greenplum: Append Only и...
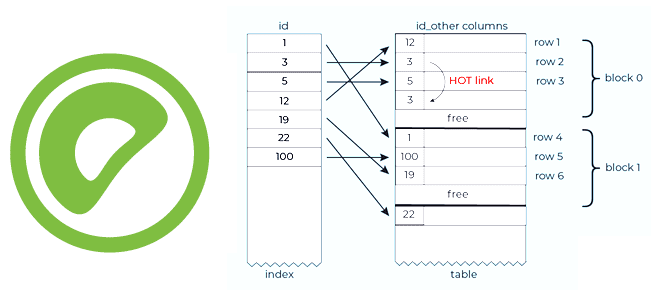
Чтобы сделать наши курсы по Greenplum еще более полезными, сегодня разберем особенности индексов и накладываемых ими ограничений на SQL-запросы к таблицам этой MPP-СУБД. Что такое уникальные индексы и как они поддерживаются в таблицах, оптимизированных для добавления, в Greenplum версии 7, выпущенной в середине декабря 2022 года. Еще раз о пользе...