 690
690 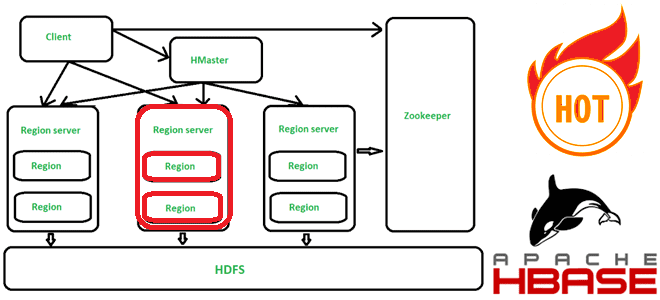
Содержание
Что такое горячие точки в Apache HBase, почему они возникают, чем опасны и как их избежать. Для этого заглянем под капот NoSQL-хранилища, чтобы разобраться с особенностями хранения данных по ключу строки.
Что такое горячие точки в кластере Apache HBase и почему они случаются
Apache HBase представляет собой колоночно-ориентированное мультиверсионное хранилище типа key-value поверх HDFS и обеспечивает возможности Google BigTable для Hadoop. Как и другие NoSQL-базы, HBase использует интересные проектные решения относительно хранения данных. Данные в HBase хранятся в таблицах, проиндексированных первичным ключом (RowKey), для каждого из которых может иметься неограниченный набор атрибутов (колонок). Колонки организованны в группы колонок (Column Family), список которых фиксирован и имеет четкую схему. Физически записи физически хранятся в порядке, отсортированном по первичному ключу, а информация из разных колонок хранится отдельно. Поэтому можно считывать данные только из нужного семейства колонок, что ускоряет чтение. Атрибуты, принадлежащие одной группе колонок и соответствующие одному ключу, физически хранятся как отсортированный список. Любой атрибут для каждого ключа может присутствовать или отсутствовать, причем отсутствие не влечет накладных расходов на хранение пустых значений.
При создании таблицы записей следует учитывать аспекты, которые влияют на производительность HBase:
- Количество регионов на таблицу записей, т.е. диапазона записей, соответствующих определенному диапазону первичных ключей, идущих подряд друг за другом;
- Дизайн ключа строки, т.е. как создается уникальный идентификатор (UUID);
- Количество групп колонок;
- Разделение;
- Долговечность.
Некорректная настройка какого-либо из этих элементов снизит производительность загрузки данных. Также могу возникнуть горячие точки (hotspotting), когда только один из узлов кластера загружен (высокая загрузка ЦП), а остальные простаивают. Горячие точки могут возникать просто при загрузке данных или даже при выполнении пакетных заданий, таких как получение, сравнение или связывание данных. Фактически горячие точки в HBase возникают, когда большой объем трафика от разных клиентов перенаправляется на один или очень небольшое количество узлов в кластере. Этот трафик может представлять операции чтения, записи или другие операции. Трафик перегружает единственный компьютер, отвечающий за размещение этого региона, что приводит к снижению производительности всей системы и недоступности региона. Это также может иметь неблагоприятные последствия для других регионов, размещенных на том же сервере региона, поскольку этот хост не может обслуживать запрошенную нагрузку. При этом, когда узел с большим объемом данных из-за неправильно заданного ключа строки HBase становится слишком загруженным или вовсе отказывает по причине огромного числа запросов с клиентов, другие узлы кластера бездействуют. Весь трафик приходит на одну машину, ответственную за размещение региона, содержащего необходимые данные, что снижает производительность всей Big Data системы и чревато недоступностью региона. Поэтому важно разработать шаблоны доступа к данным таким образом, чтобы кластер использовался полностью и равномерно.
Итак, горячие точки в HBase случаются из-за архитектурных особенностей хранения данных в этой NoSQL-СУБД, т.е. неправильного дизайна ключа строки. Строки в HBase сортируются лексикографически по ключу строки. Этот дизайн оптимизирован для сканирования, позволяя хранить связанные строки или строки, которые будут считываться вместе. Поэтому плохо спроектированные ключи строк приводят к возникновению горячих точек. Чтобы избежать этого, следует спроектировать ключ строки так, чтобы данные равномерно распределялись по всем регионам на всех узлах кластера HBase. При этом ключи строк надо определить так, чтобы строки, которые действительно должны находиться в одном и том же регионе, находились в одном регионе, но в целом данные записывались в несколько регионов кластера. Как это сделать, рассмотрим далее.
7 способов предотвратить hotspotting
Как уже было отмечено ранее, таблицы HBase используют механизм регионирования для равномерного распределения записей. По сути, регионы — это места, где данные HBase хранятся в HFiles. При создании таблицы HBase можно явно указать количество регионов или позволить принять решение об этом самому движку. Рекомендуется явно задавать количество регионов, чтобы улучшить производительность и стабильность других шагов. Это также полезно для кластера Hadoop в целом и может предотвратить появление горячих точек. Считается, что количество регионов должно быть равно общему количеству ЦП на всех серверах региона. Узнать это число можно, выполнив команду lscpu.
Чтобы правильно задать количество регионов, можно рассчитать этот параметр по следующей формуле: (количество серверов регионов — 1) * количество логических ЦП.
Поскольку уникальный идентификатор UUID определяет ключ строки, его нужно правильно создать UUID, чтобы избежать горячих точек. В частности, можно генерировать UUID случайным образом для каждой записи. Для генерации UUID выделено 122 случайных бита (всего 128 бит: 2 бита для указания RFC 41222 и 4 бита для указания версии, например, 0100 = генерируется случайным образом). Поэтому вероятность того, что любые два заданных UUID имеют одинаковое значение, крайне мала.
Для генерации UUID рекомендуется использовать встроенную утилиту Java (java.util.UUID) в среде Linux. Она генерирует случайные UUID, которые затем можно объединить с файлами данных для каждой записи. Альтернативой является использование номера записи в качестве ссылки, преобразованной в байты. Этот метод также обеспечивает уникальное создание UUID, применяя контрольную точку (номер записи). После создания файлов UUID можно использовать команду paste для их объединения с файлом данных, а команда split -l поможет разделить один большой файл на несколько файлов меньшего размера.
import java.util.UUID;
public class GenerateUUID {
public static final void main(String... args) {
long count = Long.parseLong(args[0]);
for (long i = 0L ; i < count; i++) {
UUID idOne = UUID.randomUUID();
log(idOne);
}
}
private static void log(Object aObject){
System.out.println( String.valueOf(aObject) );
}
}
Другим приемом задания ключа строки в HBase является соление (salting) — добавление случайно назначенного префикса к началу ключа, чтобы изменить порядок сортировки. Количество возможных префиксов соответствует количеству регионов, по которым надо распределить данные. Соление полезно, когда есть несколько шаблонов ключей строк, которые появляются чаще других, распределенных более равномерно. Так соление может распределять нагрузку по записи между несколькими серверами регионов.
Вместо вставки случайных значений можно применить одностороннее хеширование, которое выполнит соление строки с одним и тем же префиксом так, чтобы распределить нагрузку между серверами регионов, обеспечивая предсказуемость во время чтения. Использование детерминированного хэша позволяет клиенту реконструировать полный ключ строки и использовать операцию Get для извлечения этой строки в обычном режиме.
Также повысить производительность HBase позволяет разделение (splitting). Ручное разделение данных требует от дата-инженера знания их характера и структуры. Вместо этого можно разделить данные в HBase, используя подход по умолчанию под названием HexStringSplit. Он автоматически оптимизирует количество разделений для операций HBase. Еще одним вариантом разделить данные является их бакетирование (bucketing) – метод оптимизации производительности задачи, который разбивает данные на более управляемые части (сегменты или бакеты), чтобы ускорить последовательные чтения данных для последующих заданий.
Наконец, еще одним приемом для предотвращения горячих точек в Apache HBase является переворачивание ключа строки (reversing) — изменение его таким образом, чтобы часть, которая изменяется чаще всего (наименее значащая цифра), была первой. Это эффективно рандомизирует ключи строк в ущерб их упорядочивания.
Узнайте больше подробностей про администрирование и эксплуатацию Apache Hive и других компонентов экосистемы Hadoop для хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

