
В отличие от каменных зданий, архитектуры данных постоянно меняются. Сегодня рассмотрим новую архитектурную модель под названием BigLake, выпущенную Google весной 2022 года. Что это такое, как устроено, чем похоже на Lakehouse, озеро данных и Data Mesh, а также чем от них отличается и какую пользу несет для конвейеров аналитики Big...

Недавно мы писали, от каких факторов зависит выбор подходящего MLOps-инструмента. В продолжение этой темы сегодня специально для ML-инженеров разберем сходства и различия двух самых популярных MLOps-решений: что общего у MLflow и Kubeflow, чем они отличаются и в каких случаях выбирать тот или иной инструмент. Краткий обзор 2-х самых популярных MLOps-решений...
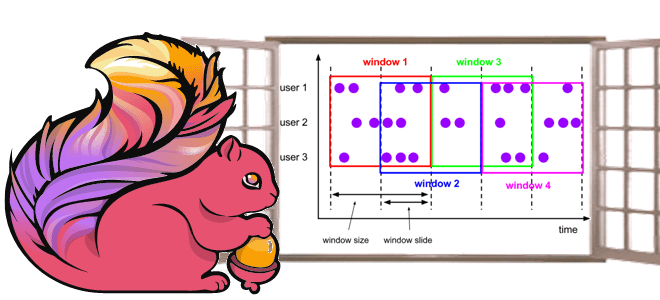
Чтобы сделать наши курсы по Apache Flink для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня рассмотрим, как этот фреймворк потоковой аналитики больших данных реализует концепцию оконных функций. Жизненный цикл окна, ключевые понятия и оконные операции Apache Flink, управляемые данными и временем. Что такое окно в потоковой обработке данных...
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем сложности рефакторинга графовых моделей в Neo4j и способы их обхода с помощью библиотеки APOC и плагина Liquibase. Что такое Liquibase и как Data Scientist и аналитик данных могут использовать его совместно с Neo4j. Гибкость модели данных и трудности...

Как найти компромисс между задержкой, пропускной способностью, долговечностью и доступностью в Apache Kafka: проблемы CAP-теоремы и поиски оптимальной стороны PACELC-ромба. Архитектурные ограничения распределенных систем и лучшие практики для настройки конфигурационных параметров для администратора кластера Apache Kafka и дата-инженера потоковых приложений аналитики больших данных. CAP-теорема и распределенные системы На производительность Apache...

Сегодня рассмотрим особенности использования оператора LIMIT в Spark SQL: как он выполняется и почему вместо него лучше использовать оператор TABLESAMPLE. Для этого в рамках обучения дата-инженеров, разработчиков распределенных приложений и аналитиков данных заглянем под капот оптимизатора Catalyst в Apache Spark и сравним физические планы выполнения SQL-запросов. Недостатки оператора LIMIT в...

В рамках обучения аналитиков данных, дата-инженеров и разработчиков распределенных приложений, сегодня поговорим про материализованные представления в Apache Hive. Что это такое, зачем нужно и как реализуется в самом популярном NoSQL-хранилище стека SQL-on-Hadoop. Что такое материализованное представление и зачем это надо в аналитике больших данных: краткий ликбез Аналитика данных включает в...

Специально для обучения администраторов кластера Apache Hadoop сегодня рассмотрим, как улучшить производительность распределенной файловой системы. Зачем перемещать файлы на последний узел в кластере, как оптимизировать управление дисками, а также чем полезно централизованное кэширование в HDFS. Оптимизация операций ввода-вывода на жестком диске Преимущества HDFS – распределенной файловой системы Apache Hadoop по...
Чтобы сделать наши курсы для специалистов по Machine Learning еще более интересными, сегодня рассмотрим 5 лучших практик по использованию популярного MLOps-инструмента. Как Data Scientist может работать с MLflow и сделать свои конвейеры машинного обучения еще более эффективными. Компоненты Mlflow для разработки и развертывания ML-систем Сегодня MLOps считается одним из самых...

Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза. Как работает LakeSoul: краткий обзор Напомним, LakeSoul от команды DMetaSoul представляет собой...