 1026
1026 
Как найти компромисс между задержкой, пропускной способностью, долговечностью и доступностью в Apache Kafka: проблемы CAP-теоремы и поиски оптимальной стороны PACELC-ромба. Архитектурные ограничения распределенных систем и лучшие практики для настройки конфигурационных параметров для администратора кластера Apache Kafka и дата-инженера потоковых приложений аналитики больших данных.
CAP-теорема и распределенные системы
На производительность Apache Kafka будут влиять многие факторы, в т.ч. количество разделов и реплик, подтверждение продюсера и размер пакета сообщений. Но разные приложения имеют разные требования: одним нужна низкая задержка, а другим высокая пропускная способность, третьим – долговечность, а четвертым — доступность. Будучи распределенной системой, Apache Kafka сталкивается с поиском компромисса между задержкой и пропускной способностью, что мы рассматривали здесь и здесь. Задержка здесь относится к тому, сколько времени требуется для обработки одного сообщения, тогда как пропускная способность характеризует, сколько сообщений может быть обработано за отдельный период времени. Выбор архитектуры, улучшающий одну цель, обычно ухудшает другую, поэтому их можно рассматривать как противоположные концы спектра. Две другие противоположные цели — долговечность и доступность. Долговечность определяет, насколько устойчива вся система к сбоям, а доступность описывает вероятность ее работы. Эти две характеристики тоже разнонаправлены.
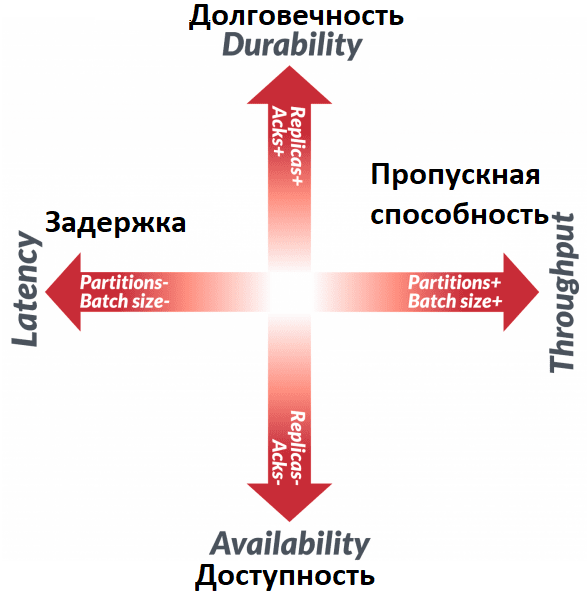
Впрочем, вообще для всех распределенных систем, а не только для Apache Kafka, характерна проблема поиска компромисса между доступность и надежностью, а также задержки и пропускной способности. Наглядно, но слегка примитивно это выражает CAP-теорема, описывая способность распределенных систем одновременно обеспечивать только 2 свойства из 3-х: согласованность (Consistency), доступность (Availability) и устойчивость к разделению (Partition tolerance). Эта гипотеза была высказана профессором Эриком Брюером в 2000-м году, а 2-мя годами е формальное доказательство опубликовали Сет Гилберт и Нэнси Линч из MIT. Однако, CAP-теорему критикуют за чрезмерное упрощение важных понятий, что приводит к неверному пониманию первоначального смысла модели. Даже сам автор этой концепции отмечает ее несостоятельность для оценки современных Big Data систем.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Альтернативой считается теорема PACELC, впервые описанная Даниелом Дж. Абади из Йельского университета в 2012 году. Она основана на модели CAP, но, помимо согласованности, доступности и устойчивости к разделению также включает временную задержку (L, Latency) и логическое исключение между сочетаниями этих понятий. Согласно PACELC, в случае сетевого разделения (P) в распределенной системе необходимо выбирать между доступностью (A) и согласованностью (C), как и в CAP- теореме, но в остальном (E, ELSE), даже при нормальной работе системы без разделения, нужно выбирать между задержкой (L) и согласованностью (C). Описать смысла PACELC-теоремы можно следующим образом: IF P -> (C or A), ELSE (C or L). Так PACELC расширяет и уточняет CAP-теорему за счет поиска компромисса между временной задержкой и согласованностью данных. Подробнее об этом мы писали здесь.
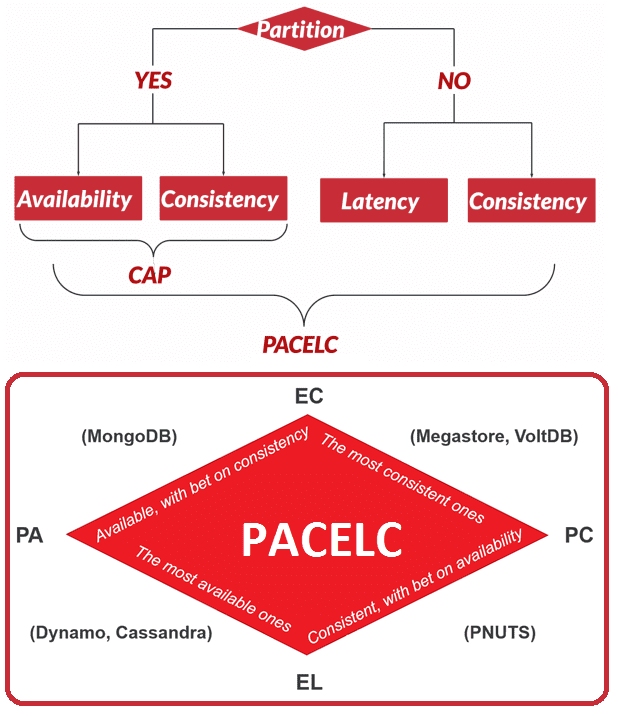
Поиск PACELC-компромисса в Apache Kafka
Учитывая вышесказанное про требования PACELC-теоремы и ограничения распределенных систем, можно сказать, что каждый раз при администрировании кластера Apache Kafka, создании топика, настройке продюсера или потребителя, необходимо выбирать между задержкой и пропускной способностью, а также между доступностью и надежностью. В частности, разделы топиков представляют собой единицу параллелизма в Kafka. В брокере и клиентах чтение и запись в разные разделы могут выполняться полностью параллельно. Хотя пропускную способность могут ограничивать многие факторы, большее количество разделов для топика обычно обеспечивает более высокую пропускную способность. Однако, слишком много разделов приводит к созданию большего количества метаданных, которые необходимо передавать и обрабатывать всем брокерам и клиентам, что увеличивает задержку. Смягчить этот побочный эффект можно, добавив брокерам дополнительные ресурсы.
Другой пример связан с репликацией данных. Реплики определяют количество копий, включая лидера, для каждого раздела топика в кластере. Устойчивость данных обеспечивается размещением реплик раздела в разных брокерах. Большее количество реплик гарантирует, что данные будут скопированы на большее количество брокеров, что обеспечит лучшую устойчивость данных в случае сбоя отдельных узлов. Меньше реплик снижает надежность данных, но может повысить их доступность для продюсеров или потребителей, допуская большее количество сбоев брокера.
Доступность для потребителя определяется наличием синхронизированных реплик, тогда как доступность для продюсера определяется минимальным количеством синхронизированных реплик, заданных в параметре конфигурации min.isr. При небольшом количестве реплик доступность всего потока данных зависит от того, какие брокеры вышли из строя и синхронизированы ли другие узлы. Поэтому меньшее количество реплик приводит к более высокой доступности приложений и меньшей устойчивости данных.
Впрочем, разделы и реплики относятся к брокерам и не являются единственными примитивами, влияющими на компромиссы между пропускной способностью и задержкой, а также между надежностью и доступностью. Другие источники поиска компромиссов оптимизации Apache Kafka, находятся в клиентских приложениях. Топики используются продюсерами, которые отправляют сообщения, и потребителями, которые их читают. Продюсеры и потребители имеют разные предпочтения между пропускной способностью и задержкой, надежностью и доступностью, что задается с помощью различных параметров конфигурации. Именно сочетание конфигураций топика Kafka и клиентского приложения с другими конфигурациями на уровне кластера, таких как выборы лидера, определяет, для чего оптимизировано приложение.
Для примера рассмотрим поток событий, состоящий из продюсера, потребителя и топика. Оптимизация такого потока событий для средней задержки на стороне клиента требует настройки продюсера и потребителя для обмена меньшими пакетами сообщений. Тот же поток можно настроить на среднюю пропускную способность, настроив продюсера и потребителя для больших пакетов сообщений.
Продюсеры и потребители имеют разные предпочтения по долговечности или доступности. Приложение-продюсер, которому надежность важнее доступности, может потребовать большее количество подтверждений, указав acks=all. Меньшее количество подтверждений, т.е. ниже min.isr по умолчанию (0 или 1), может привести к более высокой доступности с точки зрения продюсеры, допуская большее количество отказов брокера. Однако, это снижает надежность данных в случае сбоев, затрагивающих брокеров. Подробнее про параметр конфигурации acks мы писали здесь.
Конфигурации потребителя более сложны, т.к. зависят от логики приложения. Потребитель может повысить согласованность, чаще фиксируя смещения потребления сообщений. Это не влияет на долговечность записей в брокере, но влияет на то, как отслеживаются потребляемые записи, и можно ли предотвратить дублирование обработки сообщений в потребителе. В качестве альтернативы потребитель может повысить доступность, увеличив различные тайм-ауты и допуская сбои брокера в течение более длительных периодов времени.
Таким образом, при обработке любого потока данных Apache Kafka ищет компромиссы между пропускной способностью и задержкой, а также надежностью и доступностью.
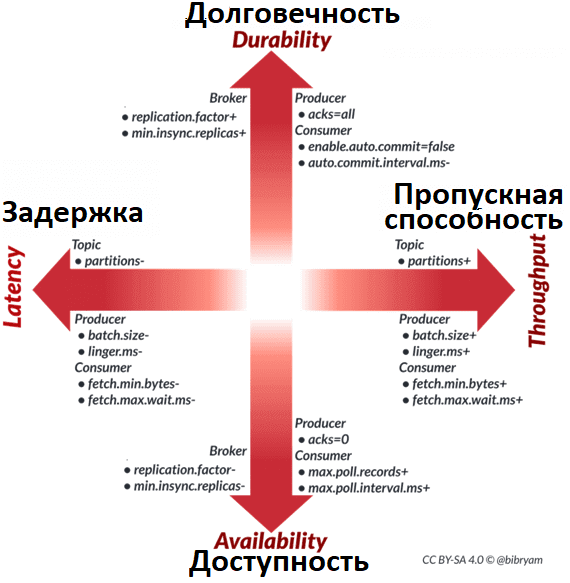
Например, оптимизация сквозного потока данных для уменьшения задержки лучше всего достигается при использовании небольших пакетов сообщений производителя и потребителя в сочетании с небольшим количеством разделов. А поток данных, оптимизированный для более высокой пропускной способности, будет иметь крупные пакеты сообщений продюсера и потребителя, а также большее количество разделов для параллельной обработки.
Поток данных, оптимизированный для устойчивости, будет иметь большее количество реплик и потребует большего количества подтверждений продюсера и детальных фиксаций потребителя. В потоке данных, оптимизированном для обеспечения доступности, нужно меньше реплик и подтверждений продюсера с большими тайм-аутами.
Тем не менее, на практике четкой корреляции в конфигурации разделов, реплик, продюсеров и потребителей нет. Можно иметь много реплик для топика, но с продюсером, который требует acks, равным 0 или 1. Или можно настроить большее количество разделов, поскольку этого требует логика приложения, имея небольшие пакеты сообщений продюсера и потребителя. Apache Kafka позволяет реализовать все эти сценарии, благодаря гибкому набору конфигурационных параметров обработки событий, который удовлетворяет многим вариантам использования.
В реальности кластеры Kafka, независимо от того, работают ли они локально с чем-то вроде Strimzi или как полностью управляемое сервисное предложение типа OpenShift Streams, чаще всего развернуты в одном регионе. Кластер Kafka производственного уровня обычно распределяется по трем зонам доступности с коэффициентом репликации 3 (RF=3) и минимальным числом синхронизированных реплик 2 (min.isr=2). Эти значения обеспечивают хороший уровень устойчивости данных в счастливые времена и хорошую доступность для клиентских приложений при временных сбоях. Эта конфигурация представляет собой твердую золотую середину, поскольку min.isr=3 не позволит продюсеру отправлять сообщения в топик Kafka, даже если отказал всего 1 брокер. А при min.isr=1 предполагает только 1 реплику данных, что повлияет как на продюсера, так и на потребителя, если вдруг лидер станет недоступен. Обычно эта конфигурация репликации сопровождается acks=all на стороне продюсера и конфигурациями фиксации смещения по умолчанию для потребителей.
На практике требования к пропускной способности и задержке у приложений сильно различаются. Количество разделов топика зависит от данных, логики их обработки и требований к упорядоченности. В то же время количество разделов определяет максимальный параллелизм и пропускную способность сообщений. Поэтому нет оптимального числа или диапазона по умолчанию для точного количества разделов. По умолчанию клиенты Kafka оптимизированы для низкой задержки, что видно из значений по умолчанию для продюсера (batch.size=16384, linger.ms=0, Compression.type=none) и потребителя (fetch.min.bytes=1, fetch.max.wait.ms=500). Оптимизация клиентских приложений для обеспечения пропускной способности требует увеличения времени ожидания и размеров пакетов в 5-10 раз.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

