Как реализовать потоковую публикацию данных из приложения Apache Spark Structured Streaming во внешний REST API, используя метод foreachBatch(), зачем перераспределять датафрейм перед его упаковкой в полезную нагрузку HTTP-запроса, от чего зависит число вызовов, и какие приемы помогут избежать сбоев из-за ошибок. 6 шагов потоковой публикации данных в REST API с...

Продолжая недавний разговор про настройку конвейеров из Flink-приложений, сегодня рассмотрим, почему важна локальность данных, как избежать узких мест в приемниках потоковых данных и чем хорош HybridSource для объединения гетерогенных источников. Обеспечьте локальность данных Хотя распределенные системы обладают большим потенциалом по сравнению с локальными, позволяя обрабатывать больше данных, вычисления не происходят...

10 октября 2023 года вышел очередной релиз самой популярной распределенной платформы потоковой передачи событий. Знакомимся с главными новинками Apache Kafka 3.6.0: промышленная поддержка KRaft вместо ZooKeeper, оптимизация транзакций, повышение производительности памяти и другие фичи свежего релиза для разработчика, дата-инженера и администратора. ТОП-10 новинок выпуска 3.6 Apache Kafka 3.6.0 включает 6...
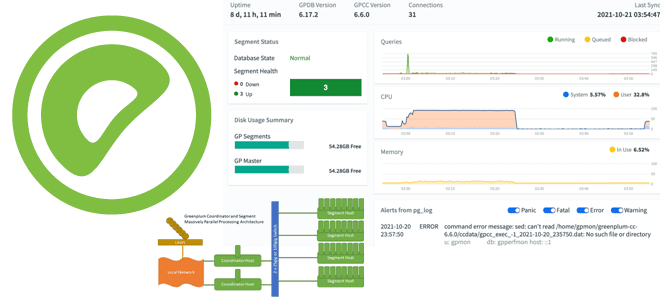
Что такое VMware Greenplum Command Center, как использовать этот инструмент для эффективного управления MPP-СУБД и чем он отличается от Arenadata Command Center для Arenadata DB. Что такое центр управления Greenplum от VMware VMware Greenplum Command Center — это инструмент управления, который отслеживает показатели производительности системы, анализирует состояние кластера и позволяет...
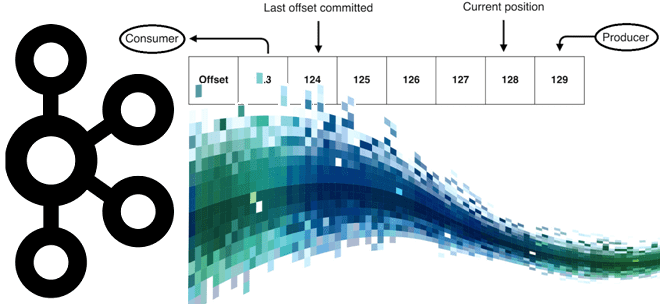
Чем политика сброса смещения earliest отличается от latest в конфигурации auto.offset.reset, зачем устанавливать свойству enable.auto.commit значение false и чем потребитель Java отличается от клиентов на основе librdkafka (C/C++, Python, Go и C#). Конфигурации Apache Kafka для управления смещением Потребитель Apache Kafka — это клиентское приложение, которое подписывается на весь топик...
Для чего разработчику Flink-приложения инструменты профилирования, и почему надо избегать сериализации Kryo и динамической загрузки классов. Используйте инструменты профилирования Разработка и отладка высоконагруженных приложений требует специальных средств, позволяющих понять причины их медленной работы и повысить производительность. Такой анализ работы приложение называется профилированием и выполняется с помощью специальных средств – инструментов...

Продолжая тему недавней статьи про настройки Greenplum 7, сегодня рассмотрим еще несколько конфигураций, которые позволят сделать эту MPP-СУБД еще быстрее и надежнее. Глобальные конфигурации Greenplum для настройки рабочих файлов Параметры глобальной конфигурации пользователя (GUC, Global User Configuration) Greenplum могут быть как глобальными, так и локальными по отношению к экземплярам сегмента. Глобальные...
Компоненты платформы Kafka Connect и их настройки для повышения скорости и объема данных, считываемых из внешних источников и публикуемых в топике Kafka. Разбираем на примере JDBC-коннектора для реляционной базы данных. Проблемы и возможности коннекторов Kafka Connect Kafka Connect — это инструмент интеграции данных с открытым исходным кодом, который упрощает процесс...
Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей. Что такое Databricks SQL Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ...
Зачем настраивать конфигурацию конвейера Flink-приложений в зависимости от рабочей нагрузки и как это сделать: примеры и рекомендации. 3 вида рабочей нагрузки в потоковых конвейерах Конвейер потоковой передачи событий может реализовывать различные сценарии: обратная засыпка (backfilling), когда конвейер потребляет все исторические данные, считывая все сообщения, доступные во входных источниках, пока не...