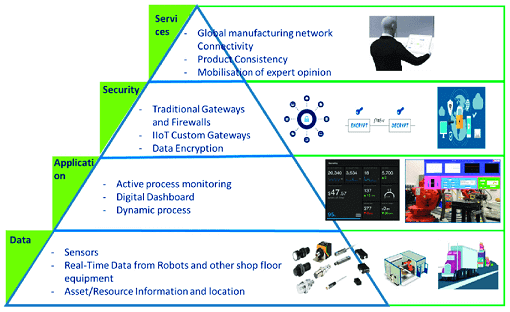
Мы уже рассматривали типовую архитектуру систем Internet of Things (IoT). Сегодня поговорим подробнее про уровневую модель передачи и обработки данных от конечных устройств до облачных IoT-платформ, а также приведем примеры наиболее популярных средств обеспечения каждого из уровней этой сложной архитектуры Industrial Internet of Things, включая инструменты Big Data. Многоуровневый IIoT:...
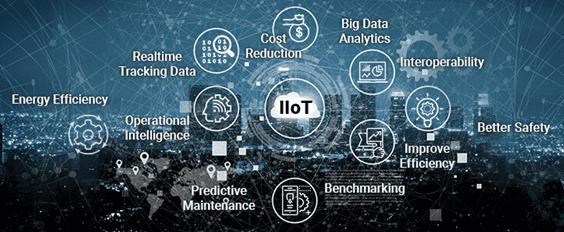
Рассмотрев основные причины задержки активного развития отечественного рынка промышленного интернета вещей (Industrial Internet of Things, IIoT), сегодня мы отметим наиболее значимые факторы роста IIoT-внедрений в России, а также поговорим про тренды этой технологии Industry 4.0, характерные для нашей страны. 7 главных факторов роста отечественного IIoT-рынка Несмотря на то, что доля...

В предыдущей статье мы анализировали текущее состояние промышленного интернета вещей (Industrial Internet of Things, IIoT) на отечественном рынке и рассматривали наиболее перспективные направления развития этого технологического стека. Сегодня мы поговорим про специфические для нашей страны проблемы, которые сдерживают наступление 4-ой промышленной революции (Industry 4.0, I4.0) в России. Основные причины задержки...
Продолжая разговор про мировые тренды развития промышленного интернета вещей (Industrial Internet of Things, IIoT), сегодня мы рассмотрим перспективы отечественного IIoT, а также проанализируем текущее развитие Big Data, Machine Learning и других ключевых технологий 4-ой промышленной революции (Industry 4.0, I4.0) в России. Промышленный интернет вещей в России: 3 главные перспективы Прежде...

В этой статье мы расскажем о 4-ой промышленной революции и прорывных технологиях, показанных на крупнейшей промышленной выставке Hannover Messe-2019: что такое коботы, цифровые близнецы и CMMS-системы, а также как все это связано с Big Data и Industrial Internet of Things. 4-я промышленная революция: что это такое и как она связана...
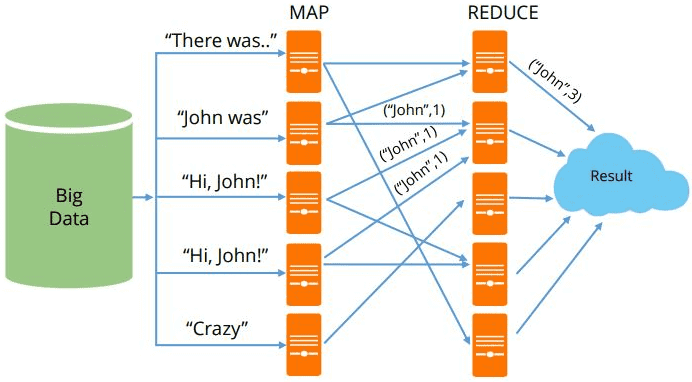
MapReduce можно назвать основой Big Data, т.к. именно данная технология позволяет обрабатывать огромные массивы информации параллельно в распределенных кластерах. Эту вычислительную модель поддерживают множество различных коммерческих и свободных продуктов: Apache Hadoop, Spark, Greenplum, Hive, MongoDB, Phoenix, DryadLINQ и прочие Big Data фреймворки и библиотеки, написанные на разных языках программирования [1]. Сегодня...

Проанализировав сходства и различия пяти самых популярных Big Data фреймворков для распределенных потоковых вычислений (Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza), в этой статье мы сравним их по 10 критериям и отметим, какие именно факторы являются наиболее значимыми для объективного выбора. Сравнительный анализ самых популярных фреймворков потоковой обработки...

В этой статье мы рассмотрим, чем похожи и чем отличаются 5 самых популярных инструментов распределенной обработки потоков Big Data: Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza, а также поговорим про наиболее значимые факторы выбора между этими программными средствами. 5 общих характеристик распределенных Big Data фреймворков потоковой обработки Прежде...

Apache Samza часто сравнивают с другими Big Data фреймворками распределенных потоковых вычислений в реальном времени (Real Time, RT): Kafka Streams, Spark Streaming, Flink и Storm. Apache Spark и Flink обладают практически одинаковым набором функциональных возможностей и компонентов, поэтому их можно сравнивать между собой более-менее объективно. Apache Samza является более простой...

Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм,...