
Cегодня рассмотрим некоторые инструменты защиты данных в Greenplum. Читайте далее про особенности шифрования в этой MPP-СУБД и лучшие практики обеспечения информационной безопасности и защиты в этой системе хранения и аналитики больших данных. Администраторы и суперпользователи Greenplum Для надежной защиты данных, хранящихся в MPP-СУБД Greenplum, и обеспечения информационной безопасности кластера рекомендуется...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня мы поговорим про базовые и расширенные возможности обеспечения информационной безопасности этой Big Data платформы. А в качестве практического примера разберем кейс международной финтех-компании BlackRock, которая разработала собственное security-решение для Kafka на базе протокола OAuth и серверов единого доступа KeyCloak....

В январе 2021 года российский разработчик решений для хранения и аналитики больших данных, компания Arenadata, представила новый продукт в линейке сервисов отечественного дистрибутива Apache Hadoop. Модуль Arenadata Platform Security обеспечивает централизованное управление групповыми политиками безопасности кластера. Разбираемся, что представляет собой эта система, как она связана с Apache Ranger и чем...

Сегодня поговорим про особенности перехода с локального Hadoop-кластера в облачное SaaS-решение от Google – платформу Dataproc. Читайте далее, какие 5 шагов нужно сделать, чтобы быстро развернуть и эффективно использовать облачную инфраструктуру для запуска заданий Apache Hadoop и Spark в системах хранения и обработки больших данных (Big Data). Шаги переноса Data...

В этой статье рассмотрим архитектуру и принципы работы системы хранения, аналитической обработки и визуализации больших данных на базе компонентов Hadoop, таких как Apache Spark, Hive, Tez, Ranger и Knox, развернутых в облачном Google-сервисе Dataproc. Читайте далее, как подключить к этим Big Data фреймворкам BI-инструменты Tableau и Looker, а также что обеспечивает...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
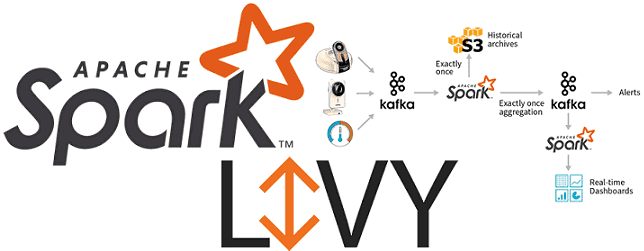
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Мы уже писали о преимуществах DaaS-похода, когда облачные провайдеры предоставляют данные как услугу, включая сложную предиктивную аналитику с использованием алгоритмов машинного обучения. Это позволяет быстро и удобно воспользоваться технологиями Big Data без существенных инвестиций в ИТ-инфраструктуру и дорогих специалистов, таких как Data Scientist, инженер и аналитик больших данных. Однако все...

Продолжая разбирать доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech, сегодня мы рассмотрим, с какими проблемами столкнулись администраторы Big Data при обеспечении информационной безопасности своих Кафка-кластеров. Читайте в нашей статье про возможные методы аутентификации в Apache Kafka и их практическое использование в...

Вчера мы говорили о том, какие организационные барьеры мешают реализации запланированных проектов национальной программы «Цифровая экономика РФ». Сегодня рассмотрим основные этические риски, которые сдерживают развитие цифровой трансформации в России и разберем некоторые возможности их обхода. Чем страшна цифровизация: 7 ключевых проблем с точки зрения этики 16 января 2020 года Центр...