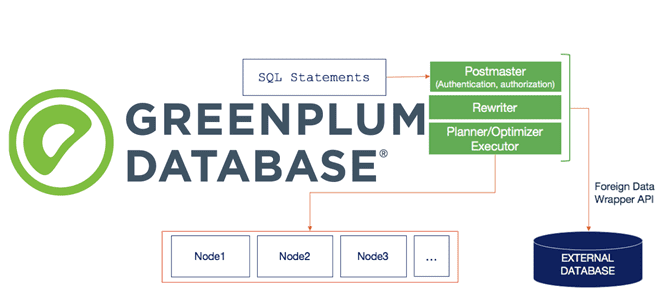
Сегодня продолжим разбираться с интеграционным фреймворком Greenplum и рассмотрим, как PXF реализует SQL-запросы к различным OLAP и OLTP-источникам, поддерживая разные форматы данных. Зачем создавать внешнюю таблицу для Greenplum и какие параметры при этом указывать, а также чем хороша технология оптимизации pushdown. SQL и PXF: интеграция Greenplum с внешними источниками на...
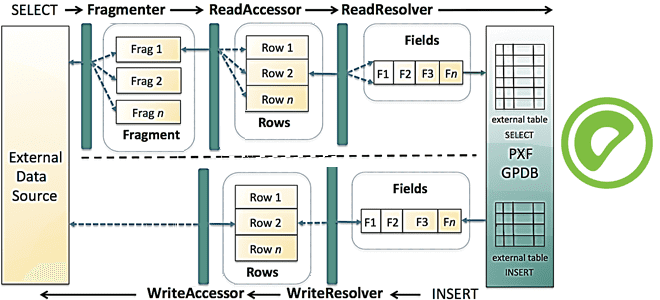
Специально для дата-инженеров, разработчиков OLAP-конвейеров и архитекторов DWH на MPP-СУБД Greenplum и Arenadata DB сегодня рассмотрим, что представляет собой PXF, из каких компонентов он состоит и как они взаимодействуют друг с другом, чтобы обеспечить параллельный высокопроизводительный доступ к данным и объединенную обработку запросов к разнородным источникам. Что PXF и зачем...
Добавляя в наши курсы по Apache Kafka еще больше полезных кейсов, сегодня рассмотрим пример интеграции этой распределенной платформы потоковой передачи событий с масштабируемой key-value СУБД GridDB через JDBC-коннекторы Kafka Connect. Apache Kafka как источник данных: source-коннектор JDBC Apache Kafka часто используется в качестве источника или приемника данных для аналитической обработки...
Чтобы добавить в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как построить конвейер преобразования CSV-файлов и загрузить данные в масштабируемую NoSQL-СУБД GridDB с помощью Apache NiFi. Краткий ликбез по GridDB и Apache NiFi в кейсе построения ML-системы для анализа данных временных рядов. Анализ данных временных рядов c...

Постоянно обновляя наши курсы по Apache Kafka, сегодня рассмотрим еще один полезный инструмент для администраторов, дата-инженеров и разработчиков, который повышает эффективность взаимодействия с этой распределенной платформой потоковой обработки событий. Что такое Saamsa, какие проблемы Kafka она решает и как ее использовать на практике. 5 вопросов разработчика и дата-инженера к Apache...
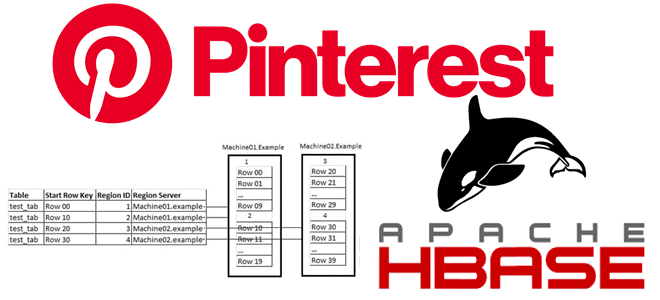
Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с...

Недавно мы писали про платформы потоковой обработки событий, альтернативные Apache Kafka и Flink/Spark Streaming. В продолжение этой темы сегодня рассмотрим еще пару вариантов для разработки и самообслуживаемого использования потоковых конвейеров аналитики больших данных: DataCater и Flow. Читайте далее, что это за системы, как они связаны с Apache Kafka и какова...

Сегодня разберем типичный для современной дата-инженерии кейс построения конвейера обработки измененных данных на Apache NiFi с учетом безопасности и масштабируемости API-вызовов. Также рассмотрим, зачем использовать Apache NiFi при межсистемной интеграции через API-вызовы и как реализовать CDC-подход к изменениям в СУБД MySQL с помощью процессоров этого популярного ETL-фреймворка. CDC и интеграция...

Продолжая недавний разговор про потоковую передачу событий и соответствующие Big Data инструменты, сегодня рассмотрим не отдельные фреймворки обработки данных в режиме реального времени, а комплексные платформы, которые объединяют сразу несколько технологий для интерактивной аналитики больших данных. Вас ждет краткий обзор Cloudera Streaming Analytics, Materialize и Rockset: что это такое, как...

Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим, что представляет собой облачная платформа VMware Tanzu Greenplum, где ее можно развернуть и каковы преимущества cloud-решения по сравнению с локальной версией этой MPP-СУБД. Что такое VMware Tanzu Greenplum и чем это отличается от open-source версии Напомним, в 2020 году корпорация...