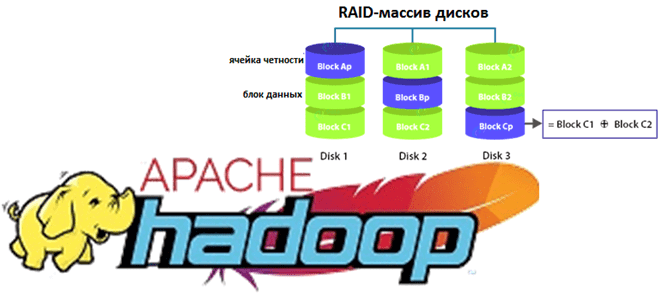
Недавно мы рассказывали про новые функции свежего релиза Apache Hadoop 3.3.1. Сегодня разберем подробнее, что такое Erasure Coding и как эта технология кодирования со стиранием экономит место в распределенной файловой системе HDFS. Также заглянем внутрь EC и рассмотрим, чем алгоритм Рида-Соломона лучше ассоциативной операции XOR для обеспечения отказоустойчивости хранилища больших...
Чтобы добавить в курсы по Apache AirFlow еще больше полезных примеров, сегодня рассмотрим, как избежать дублирования кода при загрузке данных. Этот пример пригодится дата-инженерам в работе с ELT-процессами наполнения информацией корпоративных хранилищ и озер данных. Читайте про фреймворк динамической загрузки данных на базе конфигурационных YAML-файлов, DAG-фабрик и загрузчиков. Проблема дублирования...

Поскольку Greenplum и Arenadata DB основаны на популярной open-source СУБД PostgreSQL, сегодня разберем, чем они отличаются от этой объектно-реляционной базы данных. Далее вас ждет краткий и понятный ответ на вопрос Greenplum vs PostgreSQL: сходства и отличия этих систем с учетом аналитики больших данных и практических кейсов дата-инженерии. Что общего между...

В этой статье в поддержку курсов по Apache NiFi заглянем под капот этой платформы маршрутизации потоковых данных и рассмотрим, как дата-инженер может создать собственный процессор. Смотрите далее, как устроены процессоры в Apache NiFi, что общего между отношениями и маршрутами движения потоковых данных, как создать FlowFile, зачем нужен метод onTrigger() и...
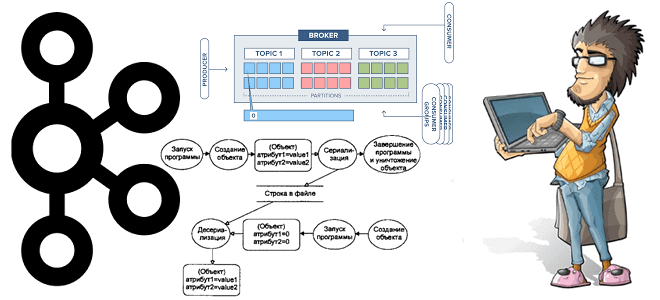
В рамках курсов по Apache Kafka для разработчиков и администраторов кластера, сегодня заглянем под капот AdminClient и на практических примерах разберем, как динамически создавать новый топик и описывать его программным способом через API. Еще рассмотрим, почему метод deleteTopics() нужно применять очень осторожно, а также вспомним основы ООП, говоря про классы...

Обучая разработчиков и администраторов Greenplum, а также в рамках продвижения курсов по Arenadata DB, сегодня рассмотрим, как SQL-оптимизатор ORCA ускоряет аналитику больших данных, позволяя реализовать многостороннее соединение таблиц через JOIN-запросы. Читайте далее, что такое GPORCA, как его использовать, насколько он эффективен по сравнению с другими планировщиками SQL-запросов в этой MPP-СУБД...

Мы уже писали про преимущества разделения пакетов в Apache AirFlow 2.0. Сегодня рассмотрим, как открытый реестр Python-пакетов от компании Astronomer облегчает разработку конвейеров обработки данных, чем провайдеры отличаются от модулей и насколько удобно дата-инженеру всем этим пользоваться. От монолита к мульти-пакетной архитектуре в Apache Airflow 2.0 Напомним, во 2-ой версии...

Постоянно обновляя наши курсы по Apache Hadoop для администраторов кластеров и инженеров данных, сегодня рассмотрим главные новинки июньского релиза 2021. Читайте далее, как поддержка Erasure Coding сэкономит место в HDFS, зачем обновляться до 8-ой версии Java, чем хорош YARN Timeline Service v.2, как повысить надежность кластера Hadoop еще больше и...

Недавно мы рассказывали про новые функции обеспечения информационной безопасности в свежем релизе Apache NiFi 1.14.0. В продолжение темы cybersecurity, сегодня рассмотрим пару внутренних уязвимостей с умеренной степенью серьезности. Читайте далее, чем опасно раскрытие конфиденциальных данных и значений параметров свойств процессора при переходе в режим отладки, а также как была устранена...

Продолжая обучение основам Apache Hadoop для начинающих администраторов, сегодня рассмотрим архитектуру и принципы работы YARN в кластере. Также разберем, какие отказы могут случиться на каждом из его компонентов и как Resource Manager системы YARN обеспечивает высокую доступность кластера Apache Hadoop. Зачем Apache Hadoop нужен YARN и как он работает Поскольку...