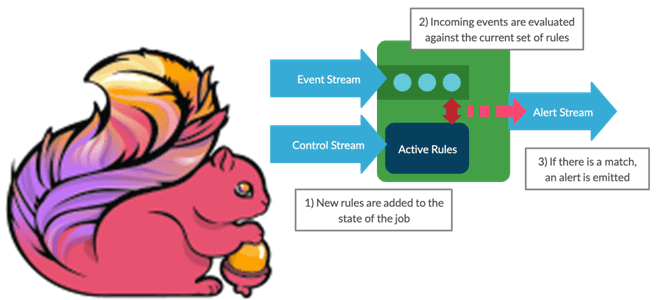
Мы уже писали про динамическое изменение правил фильтрации без перезапуска Flink-приложений. В продолжение этой темы в рамках продвижения нашего нового курса по потоковой обработке данных помощью Apache Flink, сегодня рассмотрим, как избежать неравномерного распределения данных во время выполнения программы.
Больше 3-х не собираться: бизнес-правила и динамика разделения данных
Перекос или неравномерное перераспределение данных при shuffle-операциях является одной из частых задач, с которыми сталкивается дата-инженер в конвейерах распределенных приложений. Если изменения редки, перекосы не создают особых проблем: достаточно просто перезапустить приложение. Однако, такое решение не подойдет в более сложных сценариях, когда бизнес-правила непосредственно влияют на распределение и обработку данных. Например, логика приложения постоянно меняется, и его невозможно перезапускать каждый раз. Необходимо сохранить гибкость и контроль над распределением данных по мере изменения бизнес-правил во время выполнения приложения без его перезапуска. На помощь придет динамическое повторное разделение.
Чтобы наглядно показать, как работает эта идея, рассмотрим пример со счетчиком посетителей – датчик, который подсчитывает количество людей в помещении. Предположим, требуется получать уведомление, когда это количество людей превышает пороговое значение в каком-либо помещении. Допустим, требуется получать уведомление, когда на кухне собирается более 5 человек. Приложение будет следить за кухней и, когда в кухне будет больше 5 человек, отправит уведомление. Правила запуска уведомлений могут меняться во время выполнения приложения. Опишем набор данных для этого бизнес-правила:
# Rule ruleID - unique rule identifier isActive - flag for rule removal ruleDescription * appliedOn - spaceIDs and regionIDs where we apply rule * threshold - a limit for people count (e.g. 10.0 people allowed) * operator - an operator such as <=, >=, >, <, etc # RegionCount spaceID - an identifier for a building or a space regionID - an identifier of a region inside the space (building) timestamp - a timestamp of a measurement count - number of people at point of time
Каждое правило применяется ко всем записям из определенного пространства. Целью механизма является проверка всех записей датчиков на соответствие всем применимым правилам. Это означает, что несколько правил могут независимо срабатывать для одного и того же пространства. Поле оператора сообщает, нужно ли мы получать оповещения, если фактическое значение показателя превышает заданный порог. Приложение проверяет каждое правило раз в минуту и генерирует уведомления, если оно проходит проверку правила.
Сперва необходимо реализовать управление правилами, например добавление, удаление и замена правил в приложении. Здесь поможет использование широковещательных состояний для динамической фильтрации. При широковещательном состоянии приложение сохраняет копию каждого правила для каждого рабочего процесса, и нужно лишь определить логику того, как приложение поддерживает состояние.
Если правила независимы, то одна и та же запись может запускать несколько разных правил. Поэтому проверка правил должна выполняться параллельно: нужно сгруппировать правила сопоставления и записи вместе. Как это сделать в рамках Flink-приложения, рассмотрим далее.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
26 мая, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Реализация динамического повторного разделения в Apache Flink
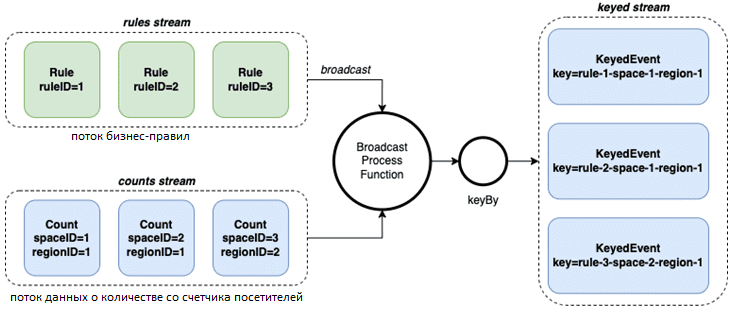
В Apache Flink в основе любой структуры обработки данных лежит оператор keyBy (groupBy, groupByKey и т. д.). Он перемешивает данные в кластере, поэтому записи с одним и тем же ключом лежат в одном разделе. Это позволяет выполнять обработку масштабируемым образом. Хотя оператор keyBy охватывает большинство вариантов использования, он не очень гибок: нужно предоставить селектор, который будет извлекать поля из записи и использовать их в качестве ключа. Если связать данные правила и датчика как одну запись с некоторым ключом, можно использовать keyBy, чтобы гарантировать параллельное выполнение правила.
Этого можно добиться, соединив вместе два потока и внедрив функцию BroadcastProcessFunction для обработки как управления правилами, так и слияния данных.
class RegionDynamicKey extends BroadcastProcessFunction[RegionCount, RegionRule, KeyedEvent] {
val SPACE_ID = "spaceID"
val REGION_ID = "regionID"
override def processElement(
value: RegionCount,
ctx: BroadcastProcessFunction[RegionCount, RegionRule, KeyedEvent]#ReadOnlyContext,
out: Collector[KeyedEvent]
): Unit = {
// create a scala map of rules from the broadcast state
val rules = {
for {
el <- ctx.getBroadcastState(RULE_DESCRIPTOR).immutableEntries().asScala
} yield (el.getKey -> el.getValue)
}.toMap
// get rules that matches current value's space and region
// the rule can be applied to all regions inside space, or at particular space - region
// in practice, this is the place where we can apply much complex matching logic
// create keyed event out of current value and rule with matching key
rules
.filter { case (_, (rule, _)) =>
value.regionID == rule.ruleDescription.appliedOn.getOrElse(
REGION_ID,
value.regionID
) && value.spaceID == rule.ruleDescription.appliedOn.getOrElse(SPACE_ID, value.spaceID)
}
.foreach { case (ruleID, (rule, _)) =>
val key = List(
ruleID,
rule.ruleDescription.appliedOn.getOrElse(SPACE_ID, ""),
rule.ruleDescription.appliedOn.getOrElse(REGION_ID, "")
).mkString("--") // Here we can apply something simpler or better for key generation
out.collect(KeyedEvent(value, key, ruleID)) // collect enriched output event
}
}
override def processBroadcastElement(
value: RegionRule,
ctx: BroadcastProcessFunction[RegionCount, RegionRule, KeyedEvent]#Context,
out: Collector[KeyedEvent]
): Unit = {
// ommited for simplicity
}
Теперь запись содержит триплет, ключ, сгенерированный с помощью правила пространства-региона, идентификатор правила для справки и саму запись. Сгенерированный ключ гарантирует, что все записи с определенным правилом пространства-региона будут находиться в одном разделе, что позволяет гибко управлять окнами и другими функциями состояния.
# Function application and keyBy val countsStream = ... val rulesStream = ... countsStream .connect(rulesStream) .process(new RegionDynamicKey()) .keyBy(event => event.key)
В вышеприведенном коде оконная функция принимает поток правил и поток агрегированных результатов. Если среднее значение удовлетворяет правилу внутри окна, создается новое уведомление. Можно расширить определение правила, добавив дополнительный параметр длительности окна и пользовательскую оконную функцию, такую как среднее, минимальное, максимальное или что-то другое. После этого нужно будет изменить функцию выполнения правил (AlertFunction).
// Full pipeline val countsStream = ... val rulesStream = ... countsStream .connect(rulesStream) .process(new RegionDynamicKey()) // calculate sum and count for average .map(event => KeyedEventAggregate(...)) .keyBy(event => event.key) .window(TumblingEventTimeWindows.of(Time.minutes(1))) .reduce(new RegionCountReducer()) // now goes rule check and alerting .connect(rulesStream) // notice rule connection again .process(new AlertFunction()) // alerting function
Далее рассмотрим функцию, которая проверяет правила и генерирует уведомления. Благодаря наличию ruleID, встроенного в запись с ключом, можно получить доступ к экземпляру правила, используя простой поиск широковещательного состояния.
class AlertFunction extends BroadcastProcessFunction[KeyedEventAggregate, RegionRule, FiredRule] {
override def processElement(
value: KeyedEventAggregate,
ctx: BroadcastProcessFunction[KeyedEventAggregate, RegionRule, FiredRule]#ReadOnlyContext,
out: Collector[FiredRule]
): Unit = {
val state = ctx.getBroadcastState(RULE_DESCRIPTOR)
Option(state.get(value.ruleID)).foreach { case (rule, check) =>
val average = value.sum / value.count
if (check(average)) // if rule is satisifed raise an alert
out.collect(FiredRule(value.timestamp, average, rule))
}
}
override def processBroadcastElement(
value: RegionRule,
ctx: BroadcastProcessFunction[KeyedEventAggregate, RegionRule, FiredRule]#Context,
out: Collector[FiredRule]
): Unit = { /* rule upsert and removal */ }
}
Таким образом, весь конвейер динамического перераспределения данных по кластеру при изменении бизнес-логики во время выполнения Flink-приложения выглядит так:
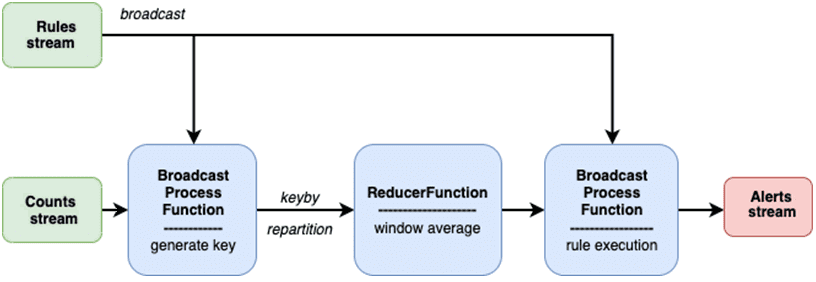
Скопировав записи с соответствующими правилами, чтобы обеспечить параллельное выполнение правил, можно обрабатывать их в большем количестве, используя больше машин в кластере. А быстрота поиска нужного правила обеспечивается за счет сохранения состояния и широковещательной трансляции. Обратной стороной этих достоинств является дублирование данных в записях датчиков на основе количества правил. Дополнительно можно объединить несколько правил в виде логических выражений. Например, генерировать уведомления, когда в одном помещении более 5 человек или в другом менее 10 человек.
Больше подробностей про администрирование и эксплуатацию Apache Flink и Spark, а также другие технологии потоковой обработки событий для распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка данных с помощью Apache Flink
- Hadoop для инженеров данных
- Потоковая обработка в Apache Spark
Источники

