Как с помощью Apache NiFi запрашивать информацию из баз данных постранично. Разбираемся с возможностями и рисками использования процессоров NiFi для пагинации в SQL-запросах.
Пагинация баз данных и процессоры Apache NiFi
Apache NiFi позволяет запрашивать из баз данных целые таблицы с помощью разбиения на страницы, т.е. пагинации. Напомним, базы данных хранят информацию специальным образом, располагая их на диске фиксированными сегментами, которые называются страницами. Фактически страница хранит кортежи, т.е. строки разных таблиц. Если результатом запроса являются данные со страницы, она переносится с диска в память и кэшируется, а все процессы базы данных получают к ней доступ. Страничная модель удобна для хранения данных и транзакционных алгоритмов, но не удобна для пользователя, т.к. страницы читаются по битам. Поэтому пользователи пишут запросы к базе данных на специализированных языках, например, SQL.
Apache NiFi имеет множество готовых процессоров для работы с различными базами данных, например, PutSQL, CaptureChangeMySQL, а также ExecuteSQLRecord и ExecuteSQL. В частности, ExecuteSQL выполняет предоставленный SQL-запрос на выборку данных (SELECT) из реляционной базы. Результат запроса преобразуется в строковый бинарный формат AVRO. Благодаря потоковой передачи поддерживаются произвольно большие наборы результатов. Этот процессор можно запланировать для запуска по таймеру или выражению cron, используя стандартные методы планирования. Также процессор ExecuteSQL может быть запущен входящим FlowFile, атрибуты которого используются для SQL-запроса. Например, атрибут executesql.row.count указывает количество строк на выборку. Аналогично работает процессор ExecuteSQLRecord, который преобразует результат SQL-запроса на выборку в формат, указанный Record Writer.
Но иногда количество извлекаемых строк может быть слишком большим и использование процессора ExecuteSQL вызывает исключение OutOfMemoryException. Впрочем, для Elasticsearch этого можно избежать, используя процессор PaginatedJsonQueryElasticsearch, который позволяет пользователю выполнять запрос с разбивкой на страницы (с агрегированием), написанный с помощью JSON DSL этой документо-ориентированной NoSQL-СУБД. Он будет использовать содержимое потокового файла для запроса, если атрибут QUERY не заполнен. Результаты поиска и результаты агрегирования можно разделить на несколько потоковых файлов. Результаты агрегации будут разделены только на верхнем уровне, потому что вложенные агрегации теряют свой контекст и, следовательно, ценность, если они отделены от родительской агрегации. Кроме того, результаты со всех страниц могут быть объединены в один потоковый файл, но процессор будет загружать в память только каждую страницу данных в любой момент времени.
Чтобы разбить результаты по страницам при работе с другими базами данных, можно использовать процессор GenerateTableFetch, который генерирует SQL-запросы на выборку с извлечением страниц из таблицы. Свойство размера раздела вместе с количеством строк в таблице определяют размер и количество страниц и сгенерированных потоковых файлов. Можно увеличить размер выборки, установив максимальные значения столбцов, чтобы извлекать только те строки, значения столбцов которых превышают наблюдаемые максимумы.
Однако, процессор GenerateTableFetch предназначен для работы только на основном узле кластера Apache NiFI. Еще одним ограничением является то, что он может работать только с реальными таблицами, а не с пользовательскими запросами. Решить эту проблему можно, используя временную таблицу при наличии прав на запись данных в исходную базу и возможность держать текущий сеанс открытым.
Если же такой возможности нет, а требуется извлечь данные из одной базы и вставить страницы в другую базу с помощью Apache NiFi, можно пойти обходным путем, реализовав конвейер из нескольких процессоров, как описано в источнике [1]. Также можно написать скрипт для процессора ExecuteScript, который выполняет пользовательский сценарий, поддерживающий движки для разных языков программирования (Clojure, ECMAScript, Groovy, lua, Python, Ruby) с учетом FlowFile и сеанса процесса. Подробнее об этом процессоре мы писали здесь.
В частности, модуль groovy-sql Groovy обеспечивает более высокий уровень абстракции по сравнению с Java-технологией JDBC. Сам JDBC предоставляет низкоуровневый, но достаточно полный API, обеспечивающий унифицированный доступ ко всему разнообразию поддерживаемых систем реляционных баз данных. Многие методы извлечения SQL в Groovy имеют дополнительные параметры, которые можно использовать для выбора конкретной страницы. Начальная позиция и размер страницы указываются как целые числа, как показано в следующем примере:
def qry = 'SELECT * FROM Author' assert sql.rows(qry, 1, 3)*.firstname == ['Dierk', 'Paul', 'Guillaume'] assert sql.rows(qry, 4, 3)*.firstname == ['Hamlet', 'Cedric', 'Erik'] assert sql.rows(qry, 7, 3)*.firstname == ['Jon']
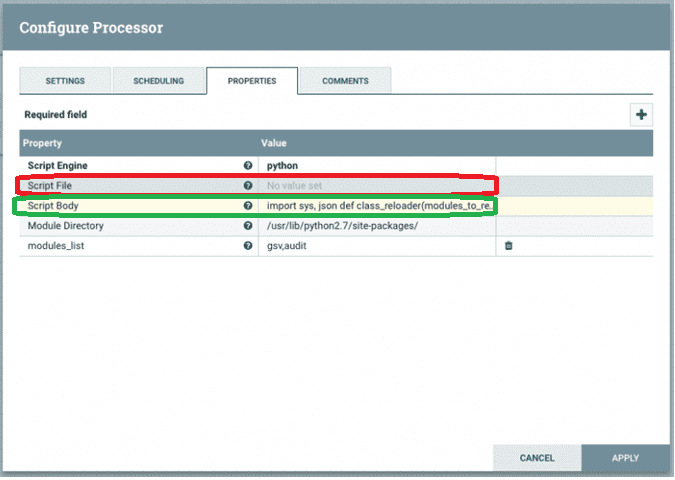
Однако, чтобы применить написанные скрипты, в процессоре ExecuteScrip следует разрешить выполнение кода, что несет высокие риски, позволяя выполнять практически все, что может сделать пользователь, который запускает сервер NiFi. Подробнее об этом мы писали здесь. Для эффективной работы с процессором ExecuteScript скрипт рекомендуется вставлять в поле Script Body вместо Script File.
Освойте все возможности Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники