 1019
1019 
Содержание
Как сделать Apache NiFi еще эффективнее, избежав трех самых популярных ошибок дата-инженера. Разбираемся с автоматизацией операций развертывания, скриптовыми процессорами, а также шаблонами и реестром NiFi для развертывания потоков данных.
Ошибка №1: ручное развертывание
Хотя Apache NiFi имеет мощный пользовательский интерфейс для проектирования конвейеров потоковой обработки данных, его не стоит рассматривать исключительно как средство LowCode. В некоторых случаях разработки кода не избежать, если необходимо кастомизировать отдельно взятые компоненты или автоматизировать некоторые операции. К ним относится обновление группы процессов до новой версии. Все их очереди должны быть пустыми, а службы контроллера и группы процессов отключены, чтобы предотвратить обработку новых сообщений и повторное заполнение очередей. Выполнение этих задач вручную займет довольно много времени и является довольно утомительным. Чтобы сделать эту процедуру более воспроизводимой, предсказуемой и менее подверженной ошибкам, ее следует автоматизировать, написав соответствующий скрипт. Так развертывание будет проходить намного быстрее, сократив время простоя и сэкономив силы дата-инженера.
Для автоматизации этой и других подобных задач в NiFi есть мощный API, для которого доступно несколько SDK, например, NiPyAPI. NiPyAPI позволяет использовать язык программирования Python, с которым сегодня знаком каждый дата-инженер и даже аналитик. NiPyAPI имеет подробную документацию и предоставляет дата-инженеру следующие функциональные возможности:
- CRUD-оболочки для процессоров, групп процессоров, шаблонов, клиентов и сегментов реестра, потоков реестра и других компонентов Apache NiFi;
- функции для задач инвентаризации, включая рекурсивное извлечение всего холста или плоский список всех групп процессов;
- поддержка планирования и очистки потоков, служб контроллера и подключений;
- извлечение и обновление реестров переменных;
- импорт и экспорт версий потоков данных из реестра NiFi;
- поддержка конфигураций Docker Compose для тестирования и развертывания;
- развертывание интерактивной среды по скрипту и защищенная конфигурация для тестирования и демонстрации.
Также с помощью NiPyAPI можно автоматизировать поиск неиспользуемых параметров или пустых конфиденциальных значений NiFI, чтобы улучшить качество среды выполнения конвейеров обработки данных.
Ошибка №2: неэффективная работа со скриптами
NiFi легко расширяется благодаря возможности писать свои скрипты, которые поддерживаются в нескольких процессорах. Одним из них является ExecuteScript, о котором мы писали здесь. Он позволяет читать содержимое и атрибуты входящего FlowFile, создавать новый файл потока, записывать данные в содержимое и атрибуты исходящего FlowFile, а также взаимодействовать с ProcessSession для передачи FlowFiles в отношения и читать/записывать в State Manager для отслеживания переменных при выполнении процессора.
Однако, чтобы применить написанные скрипты, в процессоре необходимо разрешить выполнение кода. Это разрешение позволяет выполнять произвольный код, используя все разрешения, которые есть у NiFi. Такие мощные возможности несут высокие риски, позволяя выполнять практически все, что может сделать пользователь, который запускает сервер NiFi. Если этим воспользуется злоумышленник, ущерб может быть огромным. Кроме того, процессор ExecuteScript пока еще находится в статусе экспериментального, и он потенциально может оказать негативное влияние производительность, стабильность или надежность системы в целом.
Вообще использовать скрипты в NiFI можно двумя способами:
- вставить код непосредственно в свойство процессора NiFi под названием Script Body;
- импортировать файл скрипта из файловой системы, на которой работает сервер NiFi (свойство процессора Script File).
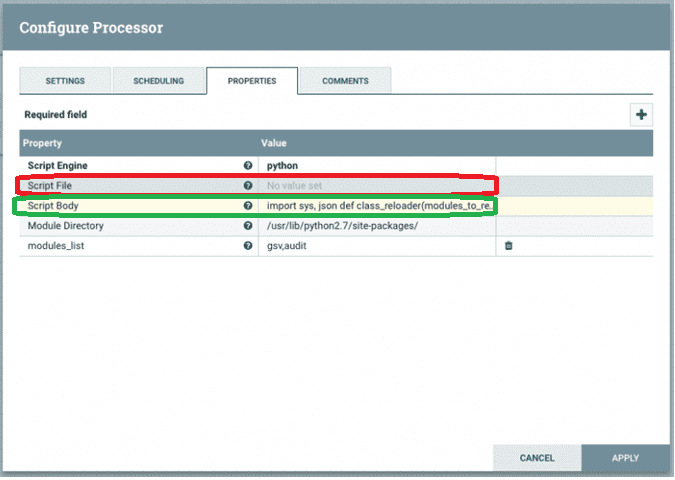
При вставке кода через свойство процессора Script Body, скрипт попадает в реестр NiFi при фиксации новой версии группы процессов. Однако, в реестре NiFi отсутствуют некоторые функции внешних продуктов, специально созданных для контроля версий кода, например, Git. В NiFi можно лишь увидеть, кто зафиксировал какую группу процессов, но невозможно выполнить ветвление или слияние версий. Понять, кто виновник ошибки в конкретной строке кода возможно при использовании Git с поддержкой реестра NiFi.
При использовании свойства процессора Script File через импорт файла из файловой системы управление версиями группы процессов и скрипта в NiFi становятся вообще невозможными. Если нужно обновить скрипт, это нельзя сделать из API или веб-интерфейса NiFi, т.к. нужен доступ к файловой системе сервера NiFi всех узлов. Это не только небезопасно, но и требует развертывания пользовательских скриптов в дополнение к реестру NiFi. Кроме того, в этом случае придется скоординировать развертывание потока и скрипта в одном релизе, добавляя дополнительную сложность. Лучше избегать этого способа.
При использовании внешних зависимостей их следует поместить в файловую систему сервера и явно настроить. В случае Python-скриптов, который в случае NiFi на самом деле является Jython, можно столкнуться с проблемой отсутствия Jython для доступного модуля Python. В таком случае придется использовать ExecuteProcess для запуска собственного интерпретатора Python, который должен быть установлен на сервере NiFi. Также придется сделать FlowFile доступным для этого процесса, сперва сохранив его где-то, чтобы потом использовать в качестве аргумента скрипта. Это занимает много времени, требует места на жестком диске, небезопасно и сложно в обслуживании. Поэтому вместо свойства процессора Script File лучше использовать Script Body для выполнения пользовательского скрипта в NiFi.
Ошибка №3: игнорирование шаблонов и реестра NiFi
Apache NiFi позволяет создавать шаблоны групп процессов, которые можно экспортировать в одну среду и импортировать в другую. Однако, не совсем правильно использовать их для продвижения изменений из одной среды в другую или для настройки локальной среды из места без доступа к реестру NiFi.
Шаблон содержит группы процессов, процессоры, соединения и службы контроллеров, которые ограничены группой процессов. Группы процессов в шаблоне теряют связь с контролем версий. Также теряется явное назначение контекстов параметров группам процессов. Это означает, что если параметры или контексты параметров отсутствуют, процессоры станут недействительными при импорте в другую среду. Когда связь с контролем версий потеряна, нет простой возможности восстановить это. Даже если запустить контроль версий для неверсионируемых групп процессов, NiFi будет предупреждать, что группа процессов уже присутствует в реестре.
Тем не менее, шаблоны могут очень пригодиться во время разработки, особенно когда есть много относительно похожих потоков данных. Можно создать шаблон с большим количеством параметров, и назначить контекст каждому из них, чтобы сделать его конкретным. Но при применении шаблона к новому объекту ссылка на исходный шаблон теряется. Поэтому при обновлении исходного шаблона потоки, созданные на его основе, обновляться не будут.
Обойти ограничение с потерей ссылок и отсутствием версионирования поможет реестр Apache NiFi. При использовании реестра NiFi для потоков данных ссылка на группу процессов в контроле версий остается. Даже когда дочерние группы процессов управляются версиями, они также остаются связанными с системой управления версиями. Ссылка позволяет увидеть, была ли изменена локальная версия по сравнению с версией в реестре, доступна ли новая версия в реестре и не вызывают ли локальные изменения конфликт с новой версией. Контексты параметров группы процессов являются частью того, что зафиксировано в реестре. Это упрощает работу с ними в разных средах, позволяя сократить количество скриптов или ручных задач.
Узнайте больше про использование Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

