Как Apache Spark использует протокол удаленного вызова процедур для межпроцессного взаимодействия, какие параметры отвечают за эффективное выполнение RPC-запросов и где их настроить.
RPC в Apache Spark
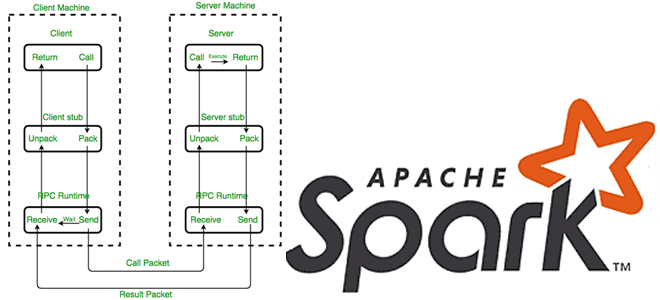
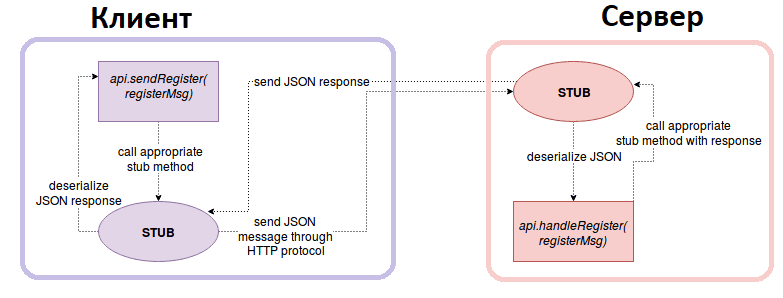
Распределенный характер Apache Spark предполагает взаимодействие между компонентами, расположенными на разных узлах, например, драйвер на мастер-узле взаимодействует с исполнителями на рабочих узлах. В качестве протокола связи между процессами фреймворк использует удаленный вызов процедур (RPC, Remote Procedure Call). RPC реализует подход клиент-сервер, позволяя клиенту вызывать функции или процедуры на удалённом сервере так, будто они выполняются локально. RPC абстрагирует сетевое взаимодействие благодаря специальным программным конструкциям (stub, заглушка), которые предоставляют интерфейс, идентичный вызываемой удалённой функции, сериализуют параметры вызова процедуры в формат, подходящий для передачи по сети, отправляют сериализованные данные через сеть на сервер, получают ответ и десериализуют его. Клиентская заглушка формирует вызов функции, собирает параметры и отправляет их на сервер. Серверная заглушка принимает вызов, распаковывает параметры и передаёт их локальной реализации функции.
RPC в Apache Spark реализован с помощью клиент-серверного фреймворка Netty, который обеспечивает высокую производительность и низкую задержку передачи данных. Обмен сообщениями осуществляется асинхронно, что позволяет Spark эффективно управлять ресурсами и избегать блокировок потоков. Для многопоточной обработки количество потоков, используемых в пуле потоков сервера, задается в конфигурации spark.rpc.io.serverThreads, а в пуле потоков клиента – в spark.rpc.io.clientThreads. Количество потоков, используемых в пуле потоков диспетчера сообщений RPC, определяется в spark.rpc.netty.dispatcher.numThreads.
Длина очереди приема для сервера RPC регулируется параметром spark.rpc.io.backLog, по умолчанию равным 64. Для приложений с большим количеством соединений рекомендуется увеличить это значение, чтобы входящие соединения не сбрасывались, когда их поступает много за короткий промежуток времени. Продолжительность блокирующего ожидания клиентом результата операции RPC-запроса регулируется параметром spark.rpc.askTimeout, а длительность ожидания операции поиска удаленной конечной точки RPC до истечения времени ожидания – параметром spark.rpc.lookupTimeout. За время установления соединения между узлами RPC отвечает конфигурация spark.rpc.io.connectionCreationTimeout, а за время ожидания для установленных соединений между узлами RPC – конфигурация spark.rpc.io.connectionTimeout.
Чтобы позволяет обеспечивать безопасность передаваемых данных, RPC в Spark поддерживает шифрование и аутентификацию. В настоящее время аутентификация для каналов RPC основана на использовании общего секрета. За это отвечает параметр конфигурации spark.authenticate. Точный механизм, используемый для генерации и распространения общего секрета, зависит от развертывания. В целях безопасности рекомендуется использовать разные секреты для разных приложений и системных служб Spark.
Для защиты RPC-подключений Spark поддерживает AES-шифрование. Его использование требует включить и правильно настроить RPC-аутентификацию. AES-шифрование использует библиотеку Apache Commons Crypto, которую можно настроить в конфигурации Spark. Этот протокол имеет две взаимно несовместимые версии. Версия 1 не применяет функцию деривации ключа (KDF) к выходным данным протокола обмена ключами, а версия 2 применяет KDF для обеспечения равномерного распределения полученного сеансового ключа. Хотя версия 1 используется по умолчанию для обратной совместимости, для улучшения свойств безопасности рекомендуется применять версию 2. Используемая версия (1 или 2) настраивается в параметре spark.network.crypto.authEngineVersion. Также поддерживается SASL-шифрование, которое считается устаревшим, но по-прежнему требуется при обращении к shuffle-сервисам из Spark старше 2.2.0.
Чтобы включить RPC-шифрование на основе AES, в т.ч. новый протокол аутентификации, добавленный в версии 2.2.0., надо установить параметру spark.network.crypto.enabled значение True. Также Spark поддерживает шифрование временных данных, записанных на локальные диски, включая файлы shuffle, shuffle spills и блоки данных, хранящиеся на диске для кэширования и широковещательных переменных. Чтобы включить шифрование ввода-вывода локального диска, надо установить параметр spark.io.encryption.enabled в значение True. В настоящее время это поддерживается всеми режимами развертывания Spark-приложений, кроме Mesos.
Объект, отвечающий за отправку сообщений в соответствующую конечную точку (заглушку клиента), представлен классом Dispatcher, который подготавливает экземпляр сообщения RPC (класс RpcMessage ) и отправляет его в ожидаемую конечную точку. Максимальный размер сообщения в байтах, которое может быть отправлено или получено через RPC-механизм, задается в конфигурации spark.rpc.message.maxSize. По умолчанию эта конфигурация равна 128 МБ. Это значение следует увеличить, если приложение обрабатывает большие объемы данных и надо передавать крупные объекты между узлами кластера. Однако, это может увеличить потребление памяти, поскольку сообщения большого размера требуют больше ресурсов. Настройка этого параметра обычно производится в конфигурационном файле spark-defaults.conf или выполняется программно при создании конфигурации SparkConf в самом приложении.
Конечные точки RPC в Spark представлены двумя классами: RpcEndpoint определяет 3 метода (onStart(), receive() и onStop()), а RpcEndpointRef отправляет синхронные или асинхронные запросы. Для обработки сообщений конечных точек PRC используется среда RpcEnv (RPC Environment). Она управляет всем жизненным циклом конечных точек RPC: регистрирует (настраивает) конечные точки (по имени или URI), направляет им входящие сообщения останавливает их. Среда RPC определяется именем, хостом и портом. Адрес среды RpcAddress кодируется как URL-адрес Spark: spark://host:port. Конечные точки RPC определяют, как обрабатывать RPC-сообщения, т.е. какие функции выполнять для данного сообщения. Экземпляры класса RpcEndpoint регистрируются с именем или URI в среде RpcEnv для получения сообщений от экземпляров класса RpcEndpointRef. Когда удаленная конечная точка разрешена, локальная среда RPC подключается к удаленной в течение времени, заданного в параметрах spark.rpc.lookupTimeout или spark.network.timeout.
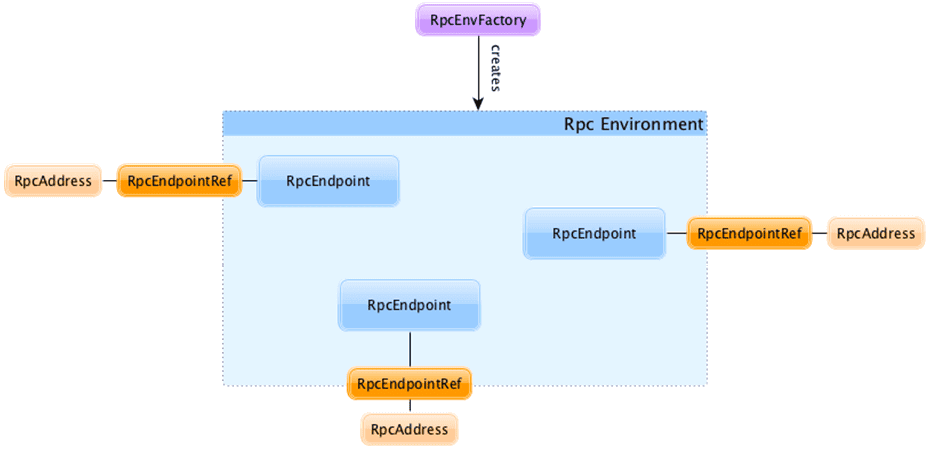
Для реализаций конечных точек RPC есть следующие классы:
- BlockManagerMasterEndpoint– отслеживает статусы всех менеджеров блоков подчиненных устройств, обрабатывая сообщения регистрации, отправки тактового сигнала, проверки кэша, обновления и получения информации о блоках, состоянии памяти и хранилища, удалении RDD, трансляции, исполнителя;
- BlockManagerSlaveEndpoint– отвечает за управление менеджерами блоков на подчиненных узлах;
- ClientEndpoint– прокси, передающий сообщения драйверу в автономном кластере для его запуска и завершению работы;
- CoarseGrainedExecutorBackend— конечная точка исполнителя в режиме, когда исполнители удерживаются только во время выполнения задания Spark и уничтожаются по его окончании. Эта конечная точка обрабатывает сообщения регистрации в драйвере, жизненный цикл задачи и исполнителя.
- DriverEndpoint– конечная точка драйвера, которая обрабатывает сообщения по обновлению статуса задачи и исполнителя.
- HeartbeatReceiver— отвечает за heartbeat-сообщения, тактовые сигналы, информирующие о работоспособности исполнителя.
- LocalEndpoint– используется для локального режима;
- MapOutputTrackerMasterEndpoint—хранит информацию о том, где на мастере находится выход сопоставления заданного этапа из задач shuffle-map. Конечная точка отвечает за получение местоположений выходов карты для заданного шага shuffle и остановку этой конечной точки.
- Master– представляет конечную точку мастер-узла, обрабатывая такие сообщения, как регистрация нового рабочего процесса, завершение неизвестных или завершенных процессов драйвера и исполнителя, проверка тайм-аута, обработка контрольных сигналов рабочих процессов, жизненный цикл приложения, изменение состояния драйвера и исполнителя, выборы лидера и восстановление мастера после сбоев.
- OutputCommitCoordinatorEndpoint— представляет класс полномочий, который решает, можно ли зафиксировать вывод в HDFS. Исполнители всегда отправляют запросы в полномочия драйвера. Этот класс отвечает только за сообщение, сообщающее об остановке конечной точки.
- RpcEndpointVerifier— проверяет наличие других конечных точек RPC.
- StateStoreCoordinator — координирует экземпляры apache.spark.sql.execution.streaming.state.StateStore, хранящиеся удаленно в исполнителях. Этот класс отвечает за некоторые потоковые stateful-операции, например, FlatMapGroupsWithState, дедупликация или агрегации. При этом обрабатываются следующие сообщения: активные экземпляры StateStore, сообщающие о заданном исполнителе, проверка статуса экземпляра, получение местоположения определенного StateStore, деактивация StateStore или остановка координатора хранилища состояний.
- Worker – представляет рабочий узел, который глобально отвечает за все коммуникации с главным узлом. Он обрабатывает сообщения статуса регистрации, отправка тактовых импульсов, очистка каталога приложения, событие завершения приложения, жизненный цикл главного узла, исполнителя и драйвера.
- WorkerWatcher— подключается к Worker, чтобы завершить работу JVM для прерванного соединения. Он не получает сообщений, а лишь обрабатывает подключения к удаленному узлу, отключения удаленного узла и все сетевые ошибки между конечной точкой и любым удаленным адресом.
Когда среда RpcEnv перехватывает неперехваченные исключения, она отправляет их обратно отправителю или регистрирует их, если такого отправителя нет или исключение несериализуемо. Например, из-за нехватки памяти работа Spark-приложения может завершиться сбоем с исключением org.apache.spark.rpc.RpcTimeoutException и сообщением Futures timed out:
org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [120 seconds]. This timeout is controlled by spark.rpc.askTimeout at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48)
Эти ошибки вызваны недостатком ресурсов памяти при обработке данных. Если запускается процесс сборки мусора Java, приложение Spark может перестать отвечать на запросы. И обработка запросов прервется из-за истечения время ожидания. Ошибка Futures timed out означает, что кластер работает в условиях сильной перегрузки. Исправить это можно, добавив в кластер дополнительные рабочие узлы или увеличив объем памяти для существующих узлов. Можно также снизить объем одновременно обрабатываемых данных. Увеличение времени ожидания для всех сетевых подключений в параметре spark.network.timeout может дать некоторый запас времени для завершения критически важных операций, но не позволит полностью устранить проблему.
Таким образом, Apache Spark использует протокол RPC для связи между процессами, синхронизации драйвера и исполнителя, а также управления блоками, тактовых импульсов и потоковых агрегаций. Этот протокол оказывает сильное влияние на производительность Spark-приложения, поэтому для его эффективной работы нужно правильно настроить связанные конфигурации. Как аналогичное реализуется в Apache Flink, читайте в нашей новой статье.
Узнайте больше про использование Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
Источники
- https://spark.apache.org/docs/latest/security.html#encryption
- https://www.waitingforcode.com/apache-spark/rpc-apache-spark/read
- https://spark.apache.org/docs/3.5.1/configuration.html
- https://books.japila.pl/apache-spark-internals/rpc/spark-rpc-netty/
- https://learn.microsoft.com/ru-ru/azure/hdinsight/spark/apache-spark-troubleshoot-rpctimeoutexception

