
15 марта 2022 года вышло очередное обновление MPP-СУБД VMware Tanzu Greenplum, в основе которой лежит одноименный open-source проект. Читайте далее, какие новые фичи добавлены в выпуск 6.20 и что за проблемы устранены в этом минорном релизе. Самое главное: краткий обзор новых фич Greenplum 6.20 Greenplum 6.20.0 включает следующие новые и...
Зачем проверять подключение к Neo4j, какую URI-схему выбрать, чем плохи транзакции с автофиксацией и как передавать переменные в Cypher-запросы: рекомендации по использованию драйверов графовой СУБД в реальных приложениях аналитики больших данных. Драйверы и особенности подключения к базе данных Напомним, драйвер – это сущность, которая реализует определённые API-интерфейсы для взаимодействия с...

Мы уже рассказывали о победителях российского ИТ-конкурса «Проект Года 2020» от профессионального сообщества GlobalCIO в номинации «Аналитика и Big Data», где «Газпром нефть» и банк ВТБ делятся опытом применения российских продуктов Arenadata. Сегодня рассмотрим кейс призера 2021 года - проект «Фабрика данных» в АО «Народный банк Казахстана», в результате которого...

В этой статье для инженеров данных и разработчиков Hadoop-приложений рассмотрим опыт индийской компании Wynk по применению Apache Flink в качестве средства потоковой аналитики больших данных пользовательского поведения в мобильных приложениях прослушивания музыки. Особое внимание уделим вопросу формирования и обработки пользовательских сессий. Постановка задачи и выбор решения Wynk Music является одним...
Сегодня рассмотрим, можно ли построить на Apache Kafka быстрый и надежный блокчейн для криптовалюты, NFT или других проектов, где нужны технологии распределенного реестра. Что общего у топика Apache Kafka с blockchain-цепочкой, чем они отличаются, возможно ли совместить их и для каких случаях. А в качестве примеров перечислим несколько реальных проектов....

Сообщество разработчиков Apache NiFi регулярно радует новыми выпусками. Не успели мы полностью освоить январский релиз 2022, в начале марта появилась еще более свежая версия этого потокового маршрутизатора. Самое главное в Apache NiFi 1.16.0 для дата-инженера и администратора кластера. Главные новинки Apache NiFi 1.16.0 Apache NiFi 1.16.0 включает несколько десятков улучшений,...

Постоянно добавляя в наши курсы по Apache Spark и машинному обучению практические примеры для эффективного повышения квалификации Data Scientist’ов и инженеров данных, сегодня рассмотрим задачу пакетного прогнозирования и планирование ее запуска по расписанию без применения масштабных MLOps-решений. Apache Spark для пакетного прогнозирования Есть много готовых решений и инструментов для пакетного...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...

11 марта 2022 года вышла новая версия Apache Airflow Helm Сhart. Рассмотрим главные новинки релиза 1.5.0 и их практическую ценность с точки зрения прикладной дата-инженерии. А также разберем ключевые понятия этого менеджера пакетов Kubernetes. Что такое Helm chart в Kubernetes и причем здесь Apache AirFlow Напомним, Helm – это менеджер пакетов...
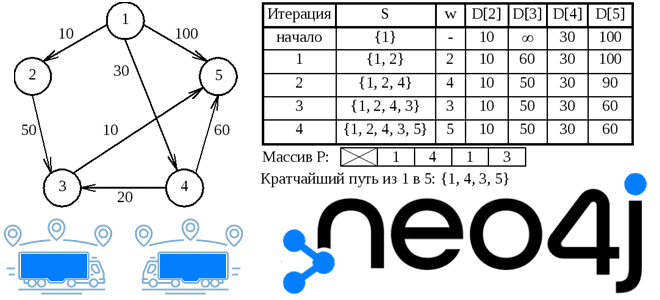
Вопрос перестройки логистических цепочек сегодня стал очень остро перед множеством предприятий, от малого до очень крупного бизнеса. Рассмотрим, как методы Data Science и аналитики больших данных помогают бизнесу справиться с современными вызовами на примере реализации алгоритма Дейкстры в библиотеке Graph Data Science графовой СУБД Neo4j. Постановка задачи: поиск кратчайшего пути...