Мы уже рассказывали про основы хранения и аналитики больших данных в Greenplum, а также рассматривали особенности индексации и сжатия данных в этой MPP-СУБД. Продолжая разговор о нашем новом курсе «Greenplum для инженеров данных», сегодня разберем лучшие практики разбиения данных на разделы и пример их распределения по сегментам кластера.
Кратко о партиционировании таблиц и распределении данных в GP
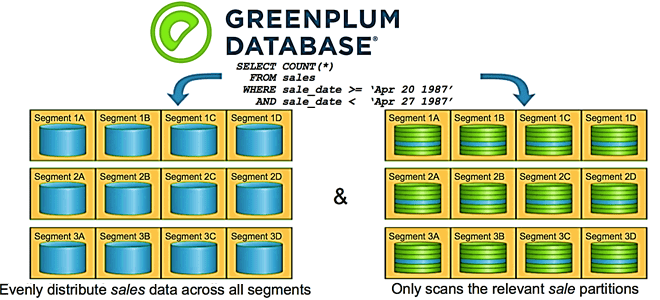
Данные в Greenplum хранятся на серверах-сегментах в отдельных экземплярах объектно-реляционной базы данных PostreSQL, которые взаимодействуют на сетевом уровне с помощью быстрых обособленных сетей — интерконнектов (interconnect). Обычно 1 узел кластера Greenplum (хост-сегмент) содержит 2-8 сегментов – независимых экземпляров СУБД PostgreSQL, где хранится часть данных [1]. Как и любам распределенная система хранения и аналитики больших данных, Greenplum обеспечивает высокую скорость обработки информации за счет разделения данных и оптимального распределения их по узлам кластера.
В частности, грамотное разделение (партиционирование, partitioning) таблиц сокращает объем данных для сканирования, позволяя запросу читать только нужные разделы. Каждый раздел в Greenplum – это отдельный физический файл или tile-набор (для колоночных таблиц) в каждом сегменте. Аналогично тому, как чтение полной строки в таблице с множеством столбцов требует больше времени, чем чтение той же строки из таблицы кучи (heap storage), чтение всех разделов в партиционированной таблице выполняется дольше, чем при отсутствии разделения. Поэтому для оптимального разбиения данных по разделам в GP следует учитывать рекомендации, о которых мы поговорим далее.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
7 июля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Партиционирование таблиц в Greenplum
Чтобы повысить скорость выполнения аналитических запросов на чтение данных из MPP-СУБД Greenplum, пригодятся следующие лучшие практики разделения таблиц [2]:
- разбивать на разделы нужно только большие таблицы и лишь в том случае, если исключение или сокращение партиций может быть достигнуто на основе критериев SQL-запроса и достигается партиционированием таблицы на основе его предиката.
- Партиционирование по диапазонам предпочтительнее разделения по списку.
- Планировщик запросов может выборочно сканировать партиционированные таблицы только если SQL-запрос содержит прямое и простое ограничение таблицы с использованием неизменяемых операторов, таких как =, <, <=,>,> = и <>.
- Выборочное сканирование распознает стабильные (STABLE) и неизменяемые (IMMUTABLE) функции в SQL-запросе, но не определяет изменчивые (VOLATILE). Например, условие WHERE в выражении date>CURRENT_DATE заставит планировщик запросов выборочно сканировать партиционированную таблицу. Но при использовании того же условия WHERE в выражении time>TIMEOFDAY этого НЕ произойдет. Поэтому важно убедиться, что SQL-запросы выборочно сканируют партиционированные таблицы, удаляя ненужные разделы. Это можно сделать, изучив план запроса EXPLAIN.
- Не рекомендуется использовать разделы по умолчанию – они всегда сканируются и часто переполняются, что приводит к снижению производительности.
- Не следует разделять и размещать таблицы в одном столбце.
- Хотя Greenplum и поддерживает многоуровневое разделение (деление на подразделы), эта практика НЕ рекомендуется, т.к. обычно подразделы содержат мало данных или вообще не содержат их. Не всегда производительность всей Big Data системы растет с увеличением количества разделов или подразделов: накладные расходы на сопровождение множества разделов и подразделов нивелируют любой выигрыш производительности. Для повышения производительности, масштабируемости и управляемости MPP-СУБД необходимо сбалансировать производительность сканирования разделов с их общим количеством.
- Не следует создавать слишком много разделов с колоночно-ориентированным хранилищем, т.к. для каждого столбца и раздела будет создан отдельный файл на диске. А Big Data системы, в первую очередь, предназначены для работы с ограниченным количеством действительно больших файлов, а не множества маленьких.
- Фактическая скорость выполнения всех параллельных SQL-запросов зависит от параллелизма рабочих нагрузок и среднего количества открытых и проверенных разделов. В частности, возможно снижение производительности при большом объеме простых запросов, которые выполняют одну операцию, т.к. каждая транзакция на мастер-узле порождает множество зеркальных транзакций на сегментах кластера [3].
Таким образом, оптимальное партиционирование – не единственное условие, ограничивающее скорость работы Greenplum. В связи с особенностями архитектуры без разделения ресурсов, эта MPP-СУБД работает со скоростью самого медленного сегмента кластера. Поэтому любой перекос в количестве данных между сегментами, как в рамках одной таблицы, так и в пределах всей базы, приведет к снижению производительности и нехватке памяти [3]. Как избежать этого, используя оптимальную стратегию распределения данных по узлам кластера, мы поговорим в следующий раз, а пока разберем связь количества файлов в разделе и столбцов хранилища.
Как связаны количество разделов и сегментов
По сути, единственным жестким ограничением количества файлов, поддерживаемых Greenplum, является количество открытых файлов операционной системы. При этом нужно учитывать общее количество файлов в кластере, в каждом сегменте и на хосте. В MPP-среде без совместного использования ресурсов каждый узел работает независимо от других и ограничен своим диском, процессором и памятью. Ограничения ЦП и ввода-вывода не характерны для Greenplum, а память часто является узким местом, т.к. модель выполнения SQL-запросов оптимизирует их производительность в памяти.
Оптимальное количество файлов на сегмент также зависит от количества сегментов на узле, размера кластера, доступа к SQL, параллелизма, рабочей нагрузки и перекоса данных и вычислений. Обычно на каждый хост приходится 6-8 сегментов, но в больших кластерах рекомендуется снизить это число. При партиционировании колоночно-ориентированных таблиц важно сбалансировать общее количество файлов в кластере, а также учитывать количество файлов на сегмент и общее количество файлов на узле.
Рассмотрим простой пример кластера из 16 узлов, на каждом из которых размещено 8 сегментов и 64 ГБ памяти. Среднее количество файлов в сегменте равно 10 000. Общее количество файлов на узел составляет 8*10 000 = 80 000. А совокупное количество файлов для кластера равняется 8*16*10 000 = 1 280 000. Количество файлов быстро растет по мере увеличения количества разделов и столбцов. Рекомендуется ограничить общее количество файлов на узел до 100 000 [2].
Администрирование Greenplum / Arenadata DB
Код курса
GRAD
Ближайшая дата курса
27 мая, 2025
Продолжительность
32 ак.часов
Стоимость обучения
96 000
Узнайте больше про администрирование и эксплуатацию Greenplum и Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

