
Разбираемся с механизмами отказоустойчивости Flink-приложений. Что такое контрольные точки (Checkpoint), чем они отличаются от точек сохранения (Savepoint) и что между ними общего. А также при чем здесь snapshot, что выбирать в разных случаях и как это использовать для отказоустойчивости stateful-приложений Apache Flink. Snapshot как механизм обеспечения отказоустойчивости приложений Apache Flink...
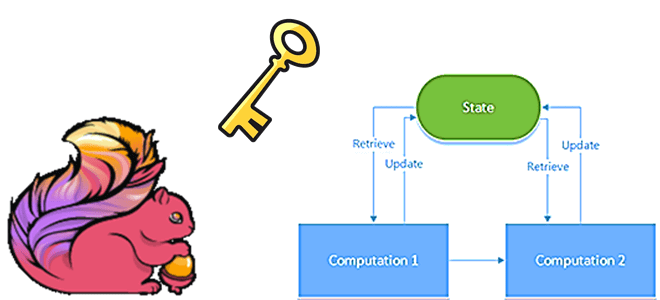
Что такое состояния в приложениях Apache Flink, каких видов они бывают, как ими управлять и зачем это нужно: основы разработки stateful-заданий и API DataStream. Чем состояние с ключом отличается от оператора состояния и почему первый чаще используется на практике. Состояния в Apache Flink Apache Flink поддерживает как stateful-, так и...
В начале декабря 2021 года мир ИТ взволновала новость о критической уязвимости CVE-2021-44228 в библиотеке Apache Log4j. Разбираемся, что это такое и чем опасно для систем хранения и аналитики больших данных на Apache Hadoop, Kafka, Spark, Elasticsearch и Neo4j. Критическая уязвимость в библиотеке Apache Log4j: чем опасна CVE-2021-44228 9 декабря...

Ранее мы писали о том, как фотохостинг Pinterest с помощью новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, объединяет пакетную и потоковую аналитику больших данных, чтобы еще лучше обслуживать более 475 миллионов своих пользователей. Сегодня поговорим про контроль сетевого трафика и синхронизацию источников данных через генерацию...

Сегодня рассмотрим, как индийская ИТ-компания Razorpay с помощью Apache Flink и Kafka свела к минимуму время простоя своего главного продукта - платежного шлюза для интернет-магазинов. Как всего 2 задания Flink могут быстро обнаруживать простои более 50 когорт событий на уровне платежного шлюза и 200+ когорт разных интернет-магазинов. Работать нельзя остановиться:...

Недавно мы писали, что в новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, сделаны попытки объединения потоковой и пакетной парадигм обработки данных. Сегодня рассмотрим, как подобное стремление к унификации реализуется на практике дата-инженерами фотохостинга Pinterest, которые используют Apache Flink как универсальный инструмент аналитики больших данных в...

29 сентября 2021 года вышла новая версия популярного Big Data фреймворка Apache Flink. Мы сделали краткий обзор главных улучшений свежего релиза 1.14 общедоступного дистрибутива, а также его коммерциализации в Ververica Platform 2.6. Узнайте, как потоковая обработка и аналитики больших данных с Apache Flink станет еще проще и эффективнее. Исправление ошибок...

Продолжая недавний разговор про потоковую передачу событий и соответствующие Big Data инструменты, сегодня рассмотрим не отдельные фреймворки обработки данных в режиме реального времени, а комплексные платформы, которые объединяют сразу несколько технологий для интерактивной аналитики больших данных. Вас ждет краткий обзор Cloudera Streaming Analytics, Materialize и Rockset: что это такое, как...

В продолжение недавней статьи для дата-инженеров про альтернативные платформы потоковой передачи событий вместо Apache Kafka, сегодня рассмотрим пример аналитики больших данных средствами Flink SQL, записи результатов в Elasticsearch и их визуализации в Kibana. Читайте далее, чем Redpanda отличается от Kafka, а Flink – от Apache Spark с точки зрения потоковой...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...