Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать.
Борьба за качество данных с entity resolution
Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь. Чтобы не повторяться, напомним, что качественные данные не имеют дублей, пропусков, а также нарушений целостности, когда описание одних и тех же сущностей или их характеристик противоречат друг другу. Для реализации этого используется подход разрешения сущностей (entity resolution). По сути, разрешение сущностей — это задача поиска каждого экземпляра сущности, например клиента, во всех корпоративных системах, приложениях и базах знаний как локально, так и в облаке.
Например, эта концепция реализуется в платформе Банка России «Знай своего клиента» (ЗСК) — сервис, с помощью которого кредитные организации могут узнать уровень риска по подозрительным операциям юридических лиц и индивидуальных предпринимателей. На основании сведений о 7 миллионах банковских клиентов, ЗСК маркирует добросовестность их финансовых операций в соответствии с ФЗ «О противодействии легализации (отмыванию) доходов, полученных преступным путем, и финансированию терроризма».
Разрешение сущностей нужно для объединения данных, относящихся к одному и тому же реальному объекту, например субъекту, объекту или другой бизнес-единицы. Конечным результатом этого процесса является единая запись для каждой сущности, содержащая всю информацию о ней, консолидированную в одном месте, без дублирующихся или противоречивых данных.
В отличие от традиционного сопоставления данных (data matching), когда записи из разных источников попарно сравниваются друг с другом, полагаясь на сопоставление атрибутов, entity resolution работает итеративно. Этот подход постоянно пополняет записи дополнительными данными для обеспечения наиболее точного представления, устанавливая связи между ними, даже при исходном низком качестве или выполненными изменениями.
Наиболее известной разновидностью подхода entity resolution сегодня стало разрешение личности (identity resolution), когда это целевым объектом объединения связанных записей является отдельный субъект – пользователь или клиент. Маркетологи, рекламодатели и другие бизнес-пользователи уже давно хотят иметь единое представление о клиенте. Именно это стремятся предоставить соответствующие платформы данных – CDP (Customer Data Platfrom), объединяя действия и атрибуты пользователя в нескольких точках взаимодействия и системах. Цель разрешения личности — связать все данные, как оффлайн, так и онлайн, вместе, чтобы ассоциировать каждое поведенческое действие с конкретным клиентом или профилем пользователя.
Основные техники и инструменты подходов entity resolution и identity resolution похожи. Их можно разделить на 2 категории:
- детерминированное разрешение или сопоставление на основе правил, когда определяются точные атрибуты для унификации и дедупликации существующих записей. Детерминированное разрешение реализуется относительно просто и быстро. Оно отлично работает в простых сценариях, где данные имеют аналогичную структуру, например, почтовые индексы, адреса, номера документов и пр.
- вероятностное разрешение или нечеткое сопоставление, основанное на машинном обучении, искусственном интеллекте и прогнозирующих моделях для идентификации и унификации объектов посредством дедупликации записей. Это сегодня востребовано больше всего, т.к. данные обычно хранятся в разных форматах и местах, а точные правила их сопоставления невозможно определить заранее.
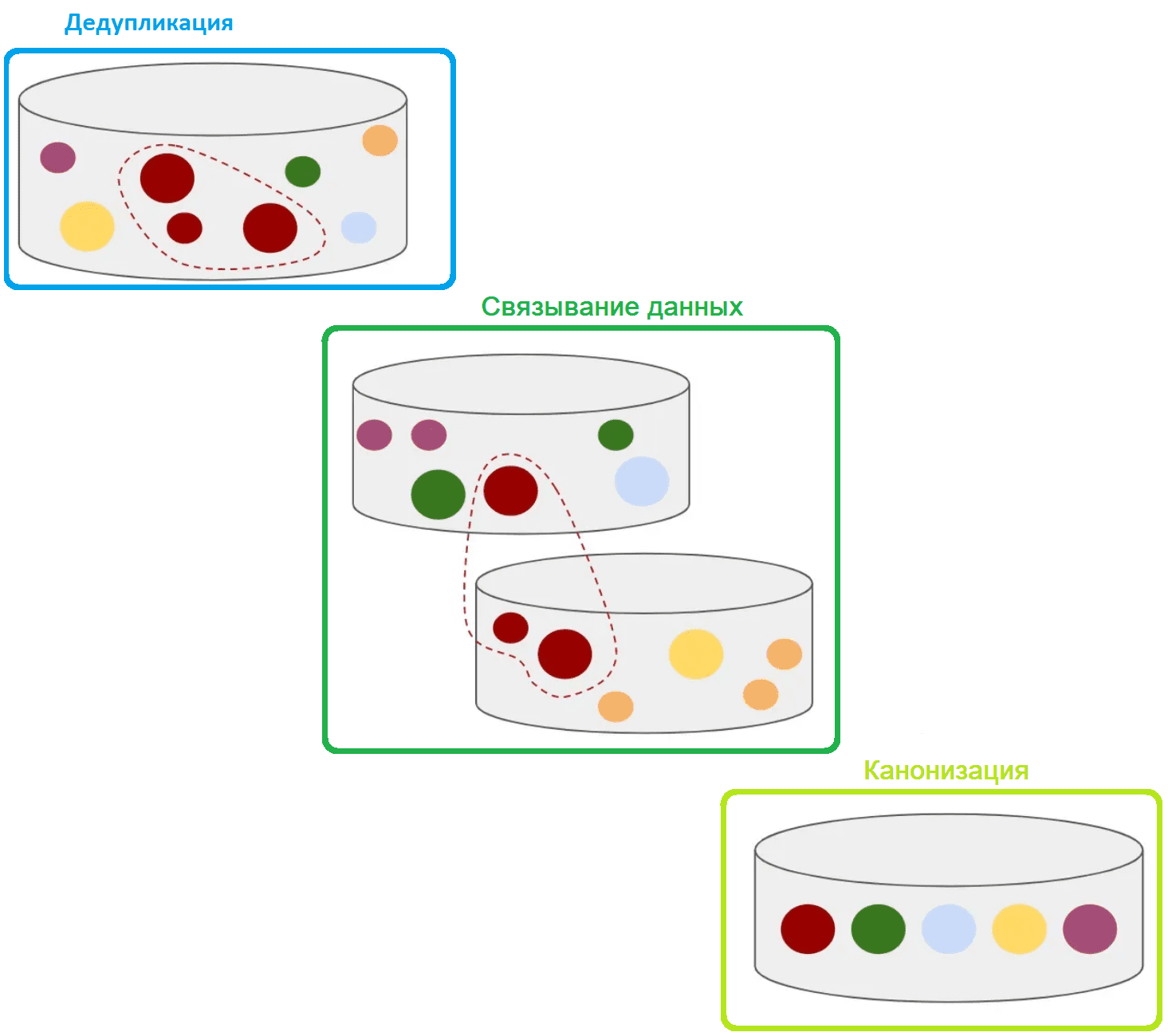
С точки зрения дата-инженера, разрешение сущностей состоит из четырех этапов:
- прием данных, включая обеспечение доступа к данным и ETL-операции их помещения в корпоративное хранилище или озеро;
- дедупликация — объединение любых записей, которые являются точными копиями друг друга, для уменьшения сложности и избыточности каждого объекта;
- связывание записей с использованием логики на основе правил или нечеткого сопоставления для определения того, какие записи относятся к одному и тому же объекту, но содержат разные данные, например, точки касания с клиентом в разных системах;
- канонизация – объединение и консолидация данных из ранее связанных записей для хранения всех связанных точек данных внутри этой сущности.
Этот общий подход разрешения сущностей немного модифицируется в identity resolution, что мы рассмотрим далее.
Инструменты identity resolution
При идентификации личности создаются графы идентичности (Identity Graphs) — таблицы известных идентификаторов клиентов, которые представляют собой карту того, как можно объединить взаимодействия с клиентами. Эти графы идентичности далее используются для связывания и дедупликации различных действий клиентов. А затем с профилями клиентов связываются другие сущности, например, товары, которые они покупают. Так можно повышать точность рекомендательных систем и организовать омниканальное маркетинговое взаимодействие.
Детерминированное identity resolution объединяет действия клиента с использованием собственных данных, которые он предоставил, например, при входе на сайт. Это основано не на предположениях, а на явных действиях клиента. Например, предположим, что покупатель совершает покупки в магазине, используя свой личный номер программы лояльности, а затем просматривает сайт на настольном компьютере, войдя в систему. Детерминированное сопоставление объединит эти действия в один и тот же профиль клиента. Если клиент не вошел в систему во время просмотра, его анонимные данные просмотра не будут связаны с его профилем. Детерминированное определение личности ценно, когда требуется высокая точность, например, для доставки персонализированных электронных писем и сообщений, а также ругих маркетинговых коммуникациях.
Вероятностное identity resolution использует алгоритмы прогнозирования для объединения действий клиентов. В отличие от детерминированного, оно не основано исключительно на высокоточных сигналах данных о клиентах, таких как логины, и может использовать другие данные, такие как аналогичные идентификаторы или действия с того же IP-адреса, местоположения и сети Wi-Fi. Такое нечеткое сопоставление работает, например, если неаутентифицированный пользователь заходит на сайт из той же сети Wi-Fi, в которой известный клиент раннее входил в приложение. Вероятностная модель предполагает, что эти два действия выполняются одним и тем же известным клиентом, и связывает их с одним и тем же профилем клиента. Вероятностное сопоставление не такое точное, чем детерминированное, но обычно дает большее число совпадений.
На практике оба подхода часто используются вместе, т.к. для персонализированных коммуникаций нужна точность детерминированного определения личности, а identity resolution хорошо работает для контекстной рекламы, даже если некоторые маркетинговые предложения окажутся нерелевантны для отдельного клиента.
Для реализации identity resolution в хранилищах данных используются инструменты преобразования, например, dbt (Data Build Tool), CDP-решения, Zingg от ZinggAI, Splink, JedAI и пр. В частности, Zingg представляет собой Spark-приложение на Java, которое может устанавливаться как Docker-образ или разворачиваться в кластере. Если необходимо использовать Zingg как импортируемый модуль, можно воспользоваться его Python API для разрешения сущностей, идентификаторов, связывания записей, управления данными и дедупликации с использованием машинного обучения. Альтернативой является Python-пакет Splink — это для вероятностного связывания записей (разрешения сущностей), который позволяет дедуплицировать и связывать записи из наборов данных без уникальных идентификаторов.
Splink — это проект связывания данных с открытым исходным кодом, в котором используется подход машинного обучения без присмотра. Он разработан и поддерживается Министерством юстиции Великобритании и используется во всем мире, и его ежемесячно загружают с PyPI более 230 000 раз. Splink предоставляет мощный и гибкий API, который позволяет пользователям детально контролировать обучение модели связи. Однако за эту гибкость приходится платить сложностью, поскольку требуется определенная степень знания связывания данных и используемых методов.
Основной алгоритм связывания Splink основан на модели связывания записей Феллеги-Сантера (Fellegi-Sunter) с различными настройками для повышения точности. Splink анализирует табличные данные, определяя связанные друг с другом записи и группирует их для получения примерного идентификатора личности.
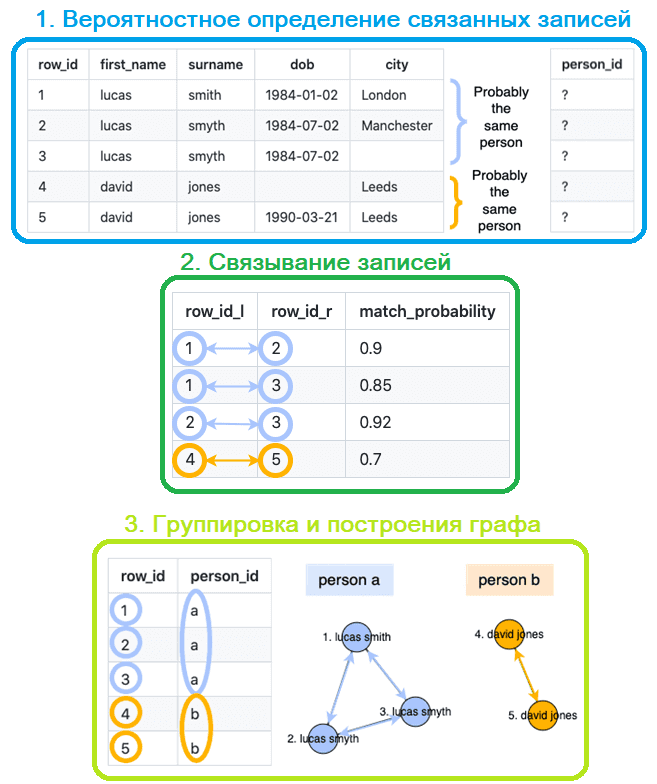
Перед использованием Splink входные данные должны быть стандартизированы с единообразными именами столбцов и форматированием, включая регистр букв и знаки пунктуации. Лучше всего Splink работает с входными данными, которые содержат несколько столбцов без сильной корреляции. Например, столбцы с именами, датами рождения и городами проживания физических лиц или название, оборот, отрасль и номер телефона юрлиц. Высокая корреляция возникает, когда значение столбца сильно зависит, т.е. предсказуемо относительно значения другого столбца. Например, город идеально коррелирует с почтовым индексом, а пол – с именем клиента. Благодаря высокой скорости и хорошей масштабируемости, Splink отлично работает с большими данными, о чем мы и поговорим в следующий раз.
Код курса
DBT
Ближайшая дата курса
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Узнайте больше про решение бизнес-задач с технологиями глубокого анализа больших данных и инструментов их преобразования на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Практическое применение Big Data аналитики для решения бизнес-задач
- Data Build Tool для инженеров данных
- Графовые алгоритмы. Бизнес-приложения
Источники
- https://www.cbr.ru/counteraction_m_ter/platform_zsk/
- https://www.quantexa.com/resources/entity-resolution-guide/
- https://habr.com/ru/companies/unidata/articles/698268/
- https://hightouch.com/blog/what-is-entity-resolution
- https://www.databricks.com/blog/improving-public-sector-decision-making-simple-automated-record-linking
- https://docs.zingg.ai/zingg0.4.0/faq
- https://moj-analytical-services.github.io/splink/index.html