
3 ноября 2021 года компания Confluent, которая занимается продвижением и коммерциализацией Apache Kafka, выпустила новый релиз ksqlDB, который включает 20 исправленных ошибок и 18 добавленных фич. Самое интересное в выпуске 0.22.0: улучшенные push- и pull-запросы, а также source-потоки и таблицы.
20 исправленных багов и 18 новых фич в ksqlDB 0.22.0
Напомним, ksqlDB – это клиент-серверная база данных потоковой передачи событий, которую можно запустить с одним сервером или сгруппировать несколько серверов вместе, чтобы использовать ее SQL API для запросов к данным, хранящихся в топиках Apache Kafka.
В ksqlDB 0.22.0 исправлены следующие ошибки:
- добавлен логический идентификатор кластера в метрики наблюдаемости;
- добавлены новые типы в функции udaf;
- добавлены типы времени в клиент Java;
- разрешено несколько вызовов EXTRACTJSONFIELD по разным путям;
- решена проблема с постоянным значением счетчика параллелизма, даже при превышении предела пропускной способности;
- изменен тег метрик;
- исправлена ошибка CREATE OR REPLACE TABLE в существующем запросе при инициализации Kafka Streams;
- включено ALPN для внутренних запросов при использовании http2 и tls;
- добавлено оповещение о закрытии Query Writer;
- обеспечено завершение фонового таймера для масштабируемых push-запросов;
- исправлено ограничение пропускной способности spq на http2;
- исправлены ошибки и увеличенная задержка для pull-запросов при закрытии соединения;
- разрешена вставка в таблицу с помощью Java API;
- удалена проверка конфигурации для вставки процессора SPQ;
- невозможен пропуск добавления при отсутствии в топике cmd;
- разрешен конфликт внутренних переопределений поточных pull-запросов с конфигурациями запросов;
- улучшена проверка сообщения об ошибке переполнения;
- исправлены функции синтаксического анализа даты: парсинг имени без учета регистра;
- исправлены метрики распределения задержки pull-запросов;
- налажена работа KsqlAvroSerializerTest с Java 16
Также в ksqlDB 0.22.0 добавлены следующие новые фичи:
- конфигурации для ведения журнала конечной точки;
- идентификаторы группы потребителей consumerGroupId в QueryDescription;
- показатель суммарных байтов CumulativeSum;
- источники потоки/таблицы (SOURCE);
- методы и классы для выполнения HTTP-запросов низкого уровня в ksqldb-api-client;
- pull-запросы к потокам;
- показатель постоянного насыщения запросов;
- общая конфигурацию времени выполнения в QueryPlan;
- оптимизированы запросы диапазона ключей в pull-запросах;
- масштабируемое регулирование полосы пропускания push-запросов;
- обновлены метрики использования хранилища для запуска при инициализации приложения;
- метрики использования хранилища;
- разрешены масштабируемые push-запросы для обработки перебалансировки;
- сбой масштабируемого push-запроса, если в подписанном постоянном запросе обнаружена ошибка;
- разрешения SchemaRegistry для субъектов приемника C * AS;
- общие среды выполнения;
- завершение временных запросов по идентификатору;
- внесены незначительные обновления синтаксиса в документации.
Итак, основными изменениями в ksqlDB 0.22.0 стали исходные потоки и таблицы (SOURCE), а также улучшение pull-запросов для предикатов диапазона ключей и повышение производительности push-запросов. Что это такое и как оно помогает разработчикам потоковых приложений Kafka Streams, рассмотрим далее, а пока напомним, что такое pull- и push-запросы, а также потоки и таблицы.
Pull-запросы интегрируют традиционный поиск в базе данных поверх материализованных таблиц с событиями непрерывного потока данных, позволяя извлекать данные в определенный момент времени и/или запрашивать состояние. Pull-запросы позволяют получить текущее состояние материализованного представления, которые постепенно обновляются по мере поступления новых событий. Поэтому pull-запросы выполняются с низкой задержкой и отлично подходят для потоков типа request/response.
Push-запросы позволяют подписаться на результат по мере его изменения в реальном времени. При поступлении новых событий push-запросы производят уточнения, чтобы быстро реагировать на новую информацию. Push-запросы идеально подходят для асинхронных потоков приложений, позволяя подписаться на SQL-запрос об изменениях.
Потоки (streams) – это неизменяемые последовательности событий, доступные только для добавления, что актуально для представления ряда исторических фактов. Таблицы (tables) – это изменяемые коллекции событий, которые позволяют представлять последнюю версию каждого значения для каждого ключа.
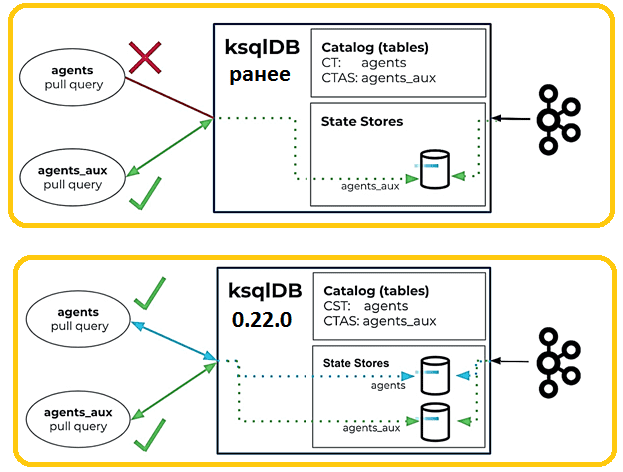
Мгновенное выполнение pull-запросов с помощью SOURCE-таблиц
До ksqlDB 0.22 pull-запросы были ограничены таблицами, созданными с помощью оператора CREATE TABLE AS SELECT (CTAS). Оператор CTAS выполняет в фоновом режиме длительное задание Kafka Streams, которое поддерживает внутреннее хранилище состояний RocksDB для изменений состояния таблицы. ksqlDB использует эти внутренние хранилища состояний для обслуживания pull-запросов. Напротив, оператор CREATE TABLE (CT) — это операция с метаданными, которая определяет схему таблицы. Однако ранее данные хранились только в основном топике, а не переносились в хранилище состояний.
Поэтому для просмотра содержимого топика и обращения к нему с помощью pull-запросов, требовалось выполнить следующие шаги:
- Зарегистрировать топик в виде таблицы
CREATE TABLE agents (id STRING PRIMARY KEY, name STRING)
WITH (KAFKA_TOPIC=’agentsTopic’, FORMAT=’JSON’);
- Создать новую таблицу с помощью оператора CTAS
CREATE TABLE agents_aux AS SELECT id, name FROM agents EMIT CHANGES;
- Выполнить pull-запросы в новой таблице
ksql> SELECT id, name FROM agents_aux WHERE id = ‘007’;
Это становится сложно, если необходимо обращаться к нескольким таблицам через pull-запросы. Поэтому разработчики из Confluent в ksqDB 0.22 сократили количество описанных выше шагов, введя концепцию исходных таблиц (source). Исходная таблица позволяет мгновенно запускать pull-запросы к таблицам без необходимости во вспомогательном операторе CTAS, сокращая количество шагов, необходимых для немедленного начала просмотра данных в топике.
Исходные таблицы создаются с помощью ключевого слова SOURCE в операторе CREATE TABLE.
CREATE SOURCE TABLE agents (id STRING PRIMARY KEY, name STRING)
WITH (KAFKA_TOPIC=’agentsTopic’, FORMAT=’JSON’);
ksql> SELECT id, name FROM agents WHERE id = ‘007’;
Исходные таблицы разделяют поведение оператора CTAS, в котором создается и поддерживается внутреннее хранилище состояний RocksDB, чтобы обеспечить возможности pull-запросов.
Ключевое слово SOURCE также делает таблицу доступной только для чтения, что полезно при обработке данных из топиков, которые нужно защитить от изменений. Также можно создавать потоки только для чтения, применяя ключевое слово SOURCE при определении потока: CREATE SOURCE STREAM <schema> WITH (…). Поскольку исходные потоки и таблицы доступны только для чтения, операторы INSERT, DROP и DELETE TOPIC в них не поддерживаются. Это также верно для таблиц, созданных с помощью операторов CTAS, доступных только для чтения.
Оптимизация для выражений сканирования диапазона и улучшенные push-запросы
До выпуска ksqlDB 0.22 pull-запросы с условием WHERE с использованием выражения диапазона были реализованы как полное сканирование таблицы: все записи из таблицы извлекались из хранилища состояний и затем фильтровались в ksqlDB. В версии 0.22 запросы диапазона по первичному ключу оптимизированы для извлечения точного диапазона записей из базового хранилища состояний. Это быстрее из-за отсутствия дополнительной фильтрации и более эффективно с точки зрения ввода-вывода.
Что касается push-запросов, которые позволяют подписаться на SQL-запрос об изменениях, ранее в ksqlDB они каждый раз требовали запуска приложения Kafka Streams. В версии 0.22.0 подмножество push-запросов теперь использует новую архитектуру, которая позволяет им работать в общем приложении Kafka Streams и выполняться намного эффективнее, чем раньше. Впрочем, сегодня ksqlDB 0.22.0 уже не самый последний релиз. Месяц спустя, в декабре 2021 года разработчики Confluent выпустили ksqlDB 0.23.1, о чем мы расскажем в следующий раз. А о новом релизе всей платформы потоковой передаче событий, Apache Kafka 3.1.0, вышедшем в январе 2022, читайте здесь.
Освойте все тонкости администрирования и эксплуатации Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

