Чтобы сделать наши курсы по Apache Kafka еще полезнее, сегодня разберем, как тестировать распределенные приложения на базе этой платформы потоковой обработки событий. Краткий ликбез для разработчика Kafka Streams и дата-инженера: классы, методы и приемы модульных тестов с примерами.
Ликбез по модульному тестированию: что такое mock-объекты
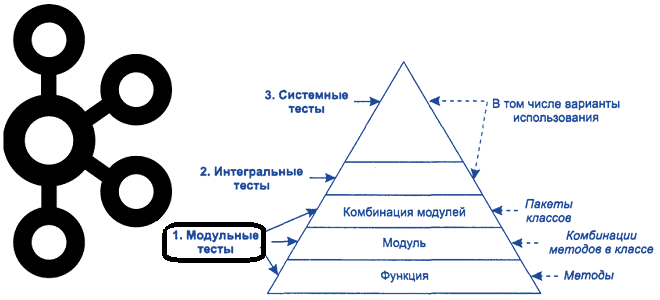
Про виды тестирования мы уже писали здесь. Напомним, именно модульное тестирование (Unit Testing) лежит в основе других видов проверки качества работы ПО, когда тестируются отдельные модули или компоненты, чтобы проверить, что каждый из них работает должным образом. Обычно модульное тестирование выполняется разработчиками, к примеру, в случае V-образной модели разработки это является основной концепцией самого процесса. Модульные тесты изолируют часть кода и проверяют его работоспособность. Модульное тестирование предшествует интеграционному и чаще всего проводится по принципу т.н. «белого ящика», поскольку известны не только входы и выходы проверяемого компонента, но и его внутреннее устройство. Отсутствие модульного тестирования при разработке кода значительно увеличивает уровень дефектов при дальнейшем продвижении по уровням тестовой пирамиды, т.е. интеграционном, системном, и приемочном тестировании. Поэтому, хотя на первый взгляд, unit-тесты и увеличивают срок разработки кода, они в итоге экономят время и деньги за счет раннего выявления дефектов.
В тестировании активно используются так называемые mock-объекты для симуляции поведения реальных объектов. Они заменяют реальные объект в условиях теста и позволяют проверять вызовы своих членов как часть системы в рамках модульного тестирования. Обычно mock-объекты содержат заранее запрограммированные ожидания вызовов, которые они ожидают получить, и применяются в основном для проверки поведения, т.е. интерактивного взаимодействия приложения с пользователем или внешней системой.
Mock-объект не просто возвращает предустановленные данные, но еще и записывает все вызовы, которые проходят через него, чтобы в unit-тесте проверить, что конкретные методы отдельных классов работают должным образом. Например, в модульном тестировании проверяется состояние объекта после прохождения unit-теста (state-based testing) и взаимодействие между объектами, поведение тестируемого метода, последовательность вызовов методов и их параметры и т.д. (interaction/behavioral testing). А про подходы к организации юнит-тестирования Spark-приложений читайте в нашей новой статье.
Тестирование потребителя Apache Kafka
Для модульного тестирования простого потребителя Apache Kafka можно использовать MockConsumer, предоставляемый библиотекой org.apache.kafka:kafka-clients:X.X.X. Для этого при разработке приложения или рефакторинге необходимо сделать классы, использующие или обертывающие экземпляр KafkaConsumer, тестируемыми. Это означает, что Consumer<K, V> будет передан через вызов фабричного метода, непосредственно в конструкторе или внедрен как bean-компонент.
Чтобы создать экземпляр MockConsumer, нужно просто сопоставить тип ключа и значение записей, сообщив, с чего начать чтение:
val mockConsumer = MockConsumer<String, String>(OffsetResetStrategy.LATEST)
Как KafkaConsumer, так и MockConsumer реализуют интерфейс Consumer<K,V>, поэтому при передаче его в тестируемый класс, он будет взаимодействовать с ним как настоящий потребитель. Но здесь есть дополнительные методы, которые можно использовать для подготовки условий тестов:
- addRecord() к mock-объекту, чтобы по существу подготовить записи для чтения перед началом теста;
- schedulePollTask(), где можно передать любой Runnable для выполнения в последующей отправке;
- setPollException() для проверки поведения потребителя при исключении.
Поскольку это предназначено только для модульного тестирования, здесь можно проверить, способен ли реальный потребитель:
- десериализовать записи, которые он должен читать;
- обрабатывать записи, таким образом, как это ожидается, включая фильтрацию;
- обрабатывать ошибки при десериализации или обработке, а также при подключении к Kafka, включая подписку на топик, считывание сообщений и фиксацию смещаний.
При этом если потребитель манипулирует смещениями нестандартным способом, можно использовать один и тот же экземпляр между всеми модульными тестами, но с помощью методов updateBeginningOffsets() и updateEndOffsets().
Тестирование продюсера
Библиотека kafka-clients также включает класс MockProducer, который реализует тот же интерфейс Producer<K, V>, что и KafkaProducer. Таким образом, подобно тестированию потребителя, классы приложения должны быть разработаны так, чтобы пройти проверку как mock-объект.
Чтобы создать экземпляр MockProducer, следует сопоставить тип ключа и значение записей и «сказать» ему, следует ли автоматически успешно завершить запросы отправки (autocomplete=true) или вы хотите выполнить их явно, вызвав completeNext() или errorNext(). Например,
val mockProduer = MockProducer(true, StringSerializer(), StringSerializer())
Чтобы протестировать нормальный поток работы продюсера, нужно выстроить его работу, используя автозаполнение, а затем проверить, что было отправлено, используя метод history() в MockProducer. Это вернет список всех записей (ProducerRecord), отправленных с момента последнего вызова метода clear() на mock-объекте.
Чтобы проверит обработку исключений, можно установить для автозаполнения значение false и errorNext(), что вызовет любое исключение RuntimeException, которое случится при незавершенном вызове отправки.
Поскольку речь идет о модульном тестировании, можно проверить, способен ли продюсер:
- сериализовать записи, которые ему нужны;
- обрабатывать ошибки сериализации;
- обрабатывать ошибки, связанные с подключением к Kafka, т.е. при вызове метода send();
- правильно фильтровать записи, т.е. что количество фактически отправленных сообщений соответствует ожидаемому числу;
- отправлять записи в ожидаемом формате, корректно обогащая или изменяя их формат.
Тестирование приложений Kafka Streams
Для Kafka Streams тестовые и рабочие классы разделены на отдельные библиотеки, поэтому нужно добавить зависимость org.apache.kafka:kafka-streams:X.X.X для использования потоков, а затем org.apache.kafka:kafka-streams-test- utils:X.X.X, чтобы использовать удобные тестовые классы.
Теперь вместо создания mock-объекта и передачи его тестируемому классу создается экземпляр TopologyTestDriver, куда передается топологию и свойства потокового приложения. Поэтому, чтобы сделать Kafka Streams-приложение пригодным для модульного тестирования, нужно создать свою топологию и передать ее тестовому драйверу:
val driver = TopologyTestDriver(myTopology, myProperties)
Когда есть экземпляр драйвера, следует явно создать все топики для вашей топологии, например:
val myInputTopic = driver.createInputTopic( inputTopicName, Serdes.String().serializer(), // key type Serdes.String().serializer() // value type )val myOutputTopic = driver.createOutputTopic( outputTopicName, Serdes.String().deserializer(), // key type Serdes.String().deserializer() // value type ).... // create as many output topics as your topology hasval myDlqTopic = driver.createOutputTopic( dlqTopicName, Serdes.String().deserializer(), // key type Serdes.String().deserializer() // value type )
После настройки всех тестовых входных и выходных топиков (TestInputTopics и TestOutputTopics) можно приступать к тестированию:
myInputTopic.pipeInput(key, validValue) ... assertTrue(myDlqTopic.isEmpty) assertFalse(myOutputTopic.isEmpty)val actualRecord = myOutputTopic.readRecord() assertEquals(expectedRecord, actualRecord, "Oh no, records don't match)
Можно также работать с несколькими входными значениями одновременно:
- pipeValueList(List<V>) — если тестовый класс работает только со значениями;
- pipeKeyValueList(List<KeyValue<K,V>> — если тестовый класс работает с ключами и значениями;
- pipeRecordList(List<TestRecord<K,V>> — если тестовый класс использует только заголовки или временные метки;
Аналогично для вывода можно применять следующие методы:
- readValuesToList() — если нужно проверить только значения вывода;
- readKeyValuesToList() или readKeyValuesToMap() — если нужно проверить только ключ и значение вывода;
- readRecordsToList() — если внужно проверить заголовки и временные метки вывода.
Эти модульные тесты проверяют, что приложение Kafka Streams может:
- сериализовать и десериализовать необходимые записи;
- обрабатывать исключения должным образом;
- обрабатывать записи как положено, т.е. формат вывода совпадает с ожидаемым, а сам поток данных воспринимается как черный ящик с известными входами и выходами, но скрытым содержимым;
- выполнять любую фильтрацию, как и ожидалось, т.е. фактическое количество выходных записей соответствует ожидаемому, независимо от того, сколько их было введено.
Потоковый процессор
При использовании потокового обработчика (процессора) пригодится MockProcessorContext для инициализации реализации этого интерфейса. С его помощью вы можете проверить, пересылаются ли записи в нужную тему и фиксируются ли смещения.
val mockContext = MockProcessorContext<String, String>()
val processor = MyProcessor() // implementing Processor
processor.init(mockContext)...processor.process(record)
val forwardedRecords = mockContext.forwareded()
assertEquals(1, forwardedRecords.size)
assertEquals(expectedRecord, forwardedRecords.map{it.record()}.first())
assertEqual(expectedTopic, forwardedRecords[0].childName().get())// if you have scheduled commit (or other action) manipulate time bymockContext.scheduledPunctuators()[0].punctuator.punctuate(time)// check if scheduled task is doneassertTrue(mockContext.committed())
Читайте в нашей следующей статье про интеграционное тестирование Kafka-приложений.
Узнайте больше про тестирование и разработку распределенных приложений с Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

