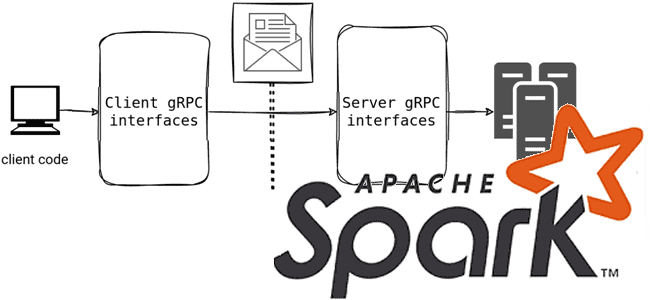
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования. Что такое Spark Connect и зачем это...
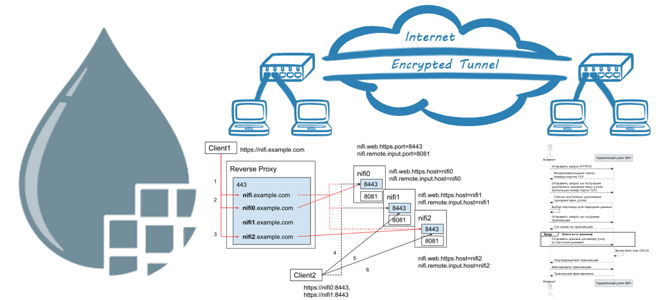
Будучи распределенным ETL/ELT-инструментом потоковой передачи данных, Apache NiFi имеет соответствующие средства, которые обеспечивают взаимодействия между разными узлами кластера. Одним из них является протокол Site-to-Site (S2S), с которым мы познакомимся далее. Что такое протокол S2S При отправке данных из одного экземпляра NiFi в другой можно использовать множество различных протоколов, наиболее предпочтительным...

Формат данных в озере или гибридном хранилище типа Data LakeHouse сильно влияет на скорость выполнения аналитических запросов. Сегодня рассмотрим, как Apache CarbonData делает аналитику больших данных в реальном времени еще быстрее. Что такое Apache CarbonData Традиционные форматы данных, часто используемые в проектах Big Data, такие как CSV и AVRO, имеют...

Сегодня рассмотрим, как запустить Apache AirFlow на мощностях Google в интерактивной среде Colab и войти в веб-GUI этого фреймворка, создав туннель локального хоста на публичный URL с помощью утилиты ngrok. Запуск Apache AirFlow в Google Colab Хотя Google Colab является мощным облачным окружением для запуска и написания Python-кода, выполнение написанных...
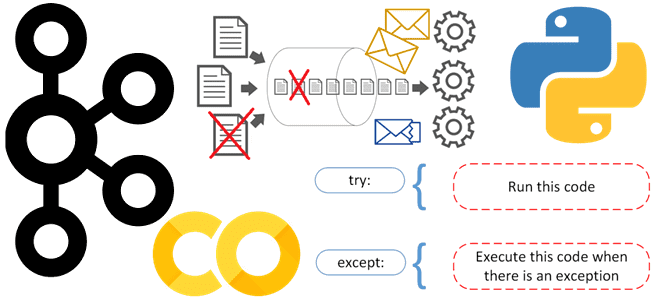
Самый простой способ организовать обработку и логирование ошибок в приложении-потребителе, чтобы продолжать считывание из Apache Kafka, даже если продюсер изменил структуру полезной нагрузки сообщения. Публикация данных в Kafka Напомним, Apache Kafka, в отличие от RabbitMQ, не позволяет организовать очередь недоставленных сообщений (DLQ, Dead Letter Queue) средствами самой платформы, о чем мы...
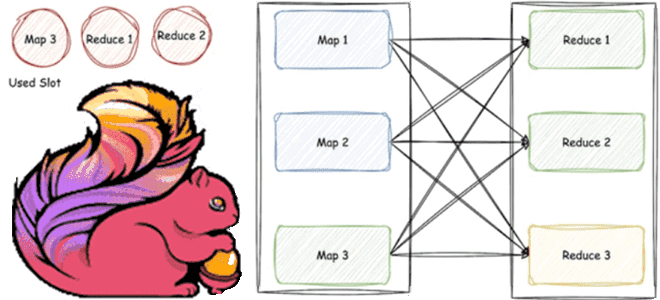
Что не так с планированием задач shuffle-операций, какие проблемы пакетной обработки данных устраняет введение гибридной перетасовки в Apache Flink 1.16 и как работает этот режим Hybrid Shuffle. Что такое режим гибридного перемешивания в Apache Flink В версии Apache Flink 1.16, о которой мы писали здесь, был впервые представлен режим гибридной...