 389
389 
Содержание
Что не так с планированием задач shuffle-операций, какие проблемы пакетной обработки данных устраняет введение гибридной перетасовки в Apache Flink 1.16 и как работает этот режим Hybrid Shuffle.
Что такое режим гибридного перемешивания в Apache Flink
В версии Apache Flink 1.16, о которой мы писали здесь, был впервые представлен режим гибридной перетасовки (Hybrid Shuffle). Он сочетает в себе традиционную пакетную перетасовку с конвейерной из потоковой обработки, чтобы увеличить мощность пакетных вычислений. Ранее во Flink планирование задач было ограничено реализациями shuffle-операций, что вызывало следующие проблемы в пакетном режиме:
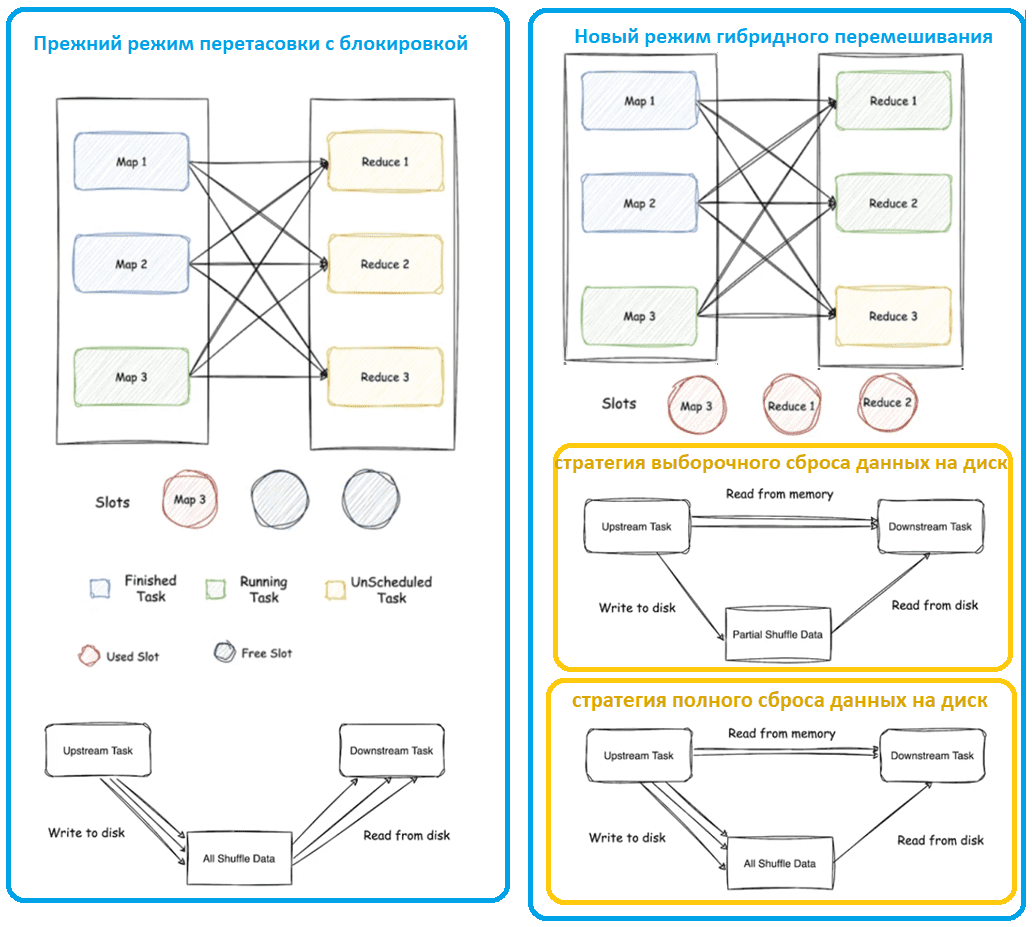
- при конвейерном перемешивании (Pipelined Shuffle) все данные в процессе передачи хранятся в памяти. Если нижестоящие задачи не используют данные своевременно, вышестоящие задачи блокируются, т.е. возникает так называемое обратное давление. Поэтому восходящие и нисходящие задачи необходимо развертывать одновременно, чтобы избежать блокировки восходящих задач. Это возможно, когда имеется достаточно ресурсов для одновременного выполнения вышестоящих и нижестоящих задач. Иначе возникают ситуации, когда задачи с JOIN-операторами и перетасовкой в конвейерной области, не могут быть выполнены, пока не получает ресурсы. В результате этого ограничения возрастает время завершения задания и снижается эффективность использования ресурсов, т.к. часть из них простаивает, ожидая остальных. Особенно часто такая ситуация случается в сценариях аналитической обработки данных (OLAP) с высокой вероятностью одновременной отправки нескольких заданий в кластер.
- При блочном перемешивании (Blocking Shuffle) все промежуточные данные записываются на локальный диск и используются только полным пакетом. Выполнение нижестоящих задач должно ожидать завершения всех вышестоящих задач, несмотря на наличие доступных ресурсов. Последовательное выполнение восходящих и нисходящих задач значительно увеличивает время завершения задания, как и операции дискового ввода-вывода для сброса и загрузки промежуточных данных.
Ключевой причиной этих проблем были ограничения на планирование задач в Apache Flink. Для их устранения в версии 1.16 был введен режим гибридного перемешивания. Единственным ограничением в этом режиме является то, что вышестоящие задачи должны быть запланированы для выполнения перед нижестоящими задачами. Hybrid Shuffle позволяет Flink-приложению более эффективно, по максимуму использовать имеющиеся ресурсы, выполняя отложенную задачу в случае их доступности. Также снижается нагрузку дискового ввода-вывода, поскольку данные в первую очередь потребляются непосредственно из памяти, а на диск сбрасываются только те данные, которые не используются своевременно.
Таким образом, по сравнению с традиционным пакетным блочным перемешиванием, гибридная перетасовка имеет следующие преимущества:
- отменяет ограничение планирования, позволяя планировать выполнение задач независимо друг от друга. Когда ресурсов достаточно, вышестоящие и нижестоящие задачи могут выполняться одновременно. Когда ресурсов недостаточно, восходящие и нисходящие задачи могут выполняться в пакетном режиме.
- снижает накладные расходы на операции ввода-вывода, устраняя необходимость записи промежуточных данных на диск.
Дефицит ресурсов относится к некоторым бездействующим слотам задач в определенные моменты времени во время выполнения задания. Это означает, что ресурсы кластера Flink используются не полностью, что может произойти при перетасовке блокировки в сценариях с неравномерным распределением данных по узлам кластера.
Для повышения эффективности работы с памятью без сброса промежуточных данных на диск режим гибридного перемешивания использует две стратегии:
- стратегия выборочного сброса (Selective Spilling Strategy), когда на диск сбрасывается только часть данных, если не хватает места в памяти;
- стратегия полного сброса (All Spilling Strategy), когда все промежуточные данные записываются на диск, но последующие задачи могут потреблять данные непосредственно из памяти, чтобы сократить количество инструкций по чтению с диска, а также повысить отказоустойчивость.
Разобравшись с тем, что представляет собой режим гибридной перетасовки, далее рассмотрим лучшие практики его настройки для более эффективного использования.
Лучшие практики использования Hybrid Shuffle
Параллелизм операторов существенно влияет на производительность заданий Flink. Для пакетных заданий, использующих блочное перемешивание, параллелизм обычно устанавливается на большее значение, чтобы улучшить возможности распределенного выполнения. Но в режиме Hybrid Shuffle, благодаря его возможности заранее планировать последующие задачи, снижение параллелизма операторов может позволить одновременно выполнять больше этапов. Это уменьшает объем данных, записываемых на диск, и обеспечивает более высокую производительность при том же общем использовании ресурсов.
Гибридное перемешивание обеспечивает оптимальную производительность при относительно небольшом параллелизме, тогда как блочная перетасовка обеспечивает оптимальную производительность при значении параллелизма, соответствующем общему количеству слотов. Это обусловлено тем, что гибридное перемешивание может уменьшить параллелизм для оптимального параллельного выполнения. А в блочном перемешивании, если параллелизм установлен слишком низким, могут быть свободные ресурсы, которые нельзя использовать.
Справедливости ради стоит отметить, что хотя Hybrid Shuffle имеет наилучшее общее время выполнения при более низких значениях параллелизма, запросы с несколькими операторами сложной вычислительной логики выполняются быстрее только при высоких значениях параллелизма.
Размер сетевой памяти оказывает значительное влияние на производительность этапа перемешивания в Apache Flink. Если памяти недостаточно, возрастет конкуренция за сетевые буферы. Поэтому важно избегать исключений из-за нехватки сетевой памяти. Для гибридного перемешивания требуется больше сетевой памяти, чем для блочной перетасовки, т.к. текущая реализация Hybrid Shuffle не отделяет требования к сетевой памяти от параллелизма задач. Требования к сетевой памяти для Blocking Shuffle не связаны с параллелизмом, поэтому увеличение параллелизма заданий не влияет на размер сетевой памяти. А в режиме Hybrid Shuffle по мере увеличения параллелизма общей сетевой памяти может оказаться недостаточно для удовлетворения минимальных требований для выполнения задания. В результате возникнет ошибка нехватки сетевой памяти. Поэтому при увеличении параллелизма заданий следует увеличить сетевую память.
Также необходимо увеличить долю данных, считываемых из памяти. Для Blocking Shuffle данные освобождаются после сброса и могут быть использованы только с диска. Поэтому память на сетевом уровне нужна только для того, чтобы снизить интенсивную конкуренцию за буферы. Но даже при наличии большего количества ресурсов производительность не повышается. В режиме гибридного перемешивания увеличение объема памяти на сетевом уровне может повысить вероятность чтения данных из памяти, поскольку стратегия вытеснения данных учитывает скорость использования пула памяти. Чем больше памяти доступно, тем дольше данные могут оставаться в памяти, что повышает вероятность их непосредственного использования без обращения к диску. Это снижает накладные расходы на операции ввода-вывода.
Однако, следует избегать одновременного использования гибридного перемешивания и динамического параллелизма. Flink поддерживает динамическую настройку параллелизма пакетных заданий во время выполнения. Планирование заданий выполняется поэтапно и нижестоящие этапы выводятся из вышестоящих законченных этапов на основе статистической информации, прежде всего, объема произведенных данных.
Режим динамического параллелизма имеет естественное ограничение на планирование: последующие этапы могут быть запланированы только после завершения восходящих этапов. Гибридное перемешивание может поддерживать этот режим, но при этом не полностью используется преимущество гибкого планирования. Таким образом, режим динамического параллелизма для Blocking Shuffle имеет лучшую производительность, что связано с сокращением дополнительных накладных расходов при планировании и развертывании задач с небольшими объемами данных.
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://www.ververica.com/blog/performance-analysis-and-tuning-guides-for-hybrid-shuffle-mode
- https://cwiki.apache.org/confluence/display/FLINK/FLIP-235%3A+Hybrid+Shuffle+Mode

