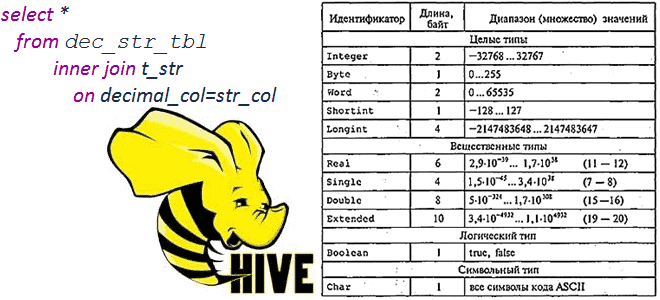
Сегодня рассмотрим тему, полезную для обучения администраторов SQL-on-Hadoop и разработчиков распределенных приложений: операции сравнения и арифметические вычисления между строковыми и десятичными типами в Apache Hive 1.2.0 и 3.1.0, а также MySQL и Microsoft SQL Server 2017. Про типы данных и SQL-запросы в Apache Hive Чтобы упростить сравнение, будем считать типы...

Мы уже писали, что Apache Hadoop 3.3.1 поддерживает технологию кодирования со стиранием (Erasure Coding, EC), которая экономит место на жестком диске по сравнению с репликацией. Однако, беспечное применение этой новой фичи может обернуться настоящей катастрофой. Кейс соцсети «Одноклассники» от ведущего разработчика Дениса Ефарова, представленный на конференции Smart Data для инженеров данных в...

2022 год только начался, а John Snow Labs уже радует разработчиков ML-приложений новым релизом библиотеки Spark NLP. Ключевые фичи 3.4.0 для версии Apache Spark 3.2.x на Scala 2.12: новые GPT-2 трансформеры, аннотаторы для ALBERT, XLNet, RoBERTa, XLM-RoBERTa и Longformer, расширенный хаб готовых Machine Learning моделей и конвейеров, а также исправление...

В рамках обучения разработчиков Data Flow и инженеров данных разберем основные принципы внутреннего языка выражений Apache NiFi: что такое атрибуты FlowFile, как манипулировать ими. Синтаксис функций, типы данных, иерархия переменных и другие тонкости Apache NiFi для дата-инженера. Язык выражений в Apache NiFi как способ манипулировать атрибутами Напомним, все данные в...

В прошлый раз мы говорили про метаданные в Apache Impala. Сегодня поговорим про функции командной строки в Impala. Читайте далее про особенности работы функций командной строки Impala, благодаря которым становится возможным процесс оптимизации обработки Big Data массивов. Как работают функции командной строки в Impala: особенности оптимизации обработки Big Data Командная...

3 ноября 2021 года компания Confluent, которая занимается продвижением и коммерциализацией Apache Kafka, выпустила новый релиз ksqlDB, который включает 20 исправленных ошибок и 18 добавленных фич. Самое интересное в выпуске 0.22.0: улучшенные push- и pull-запросы, а также source-потоки и таблицы. 20 исправленных багов и 18 новых фич в ksqlDB 0.22.0...

Сегодня рассмотрим, что такое Great Expectations, чем этот инструмент полезен для специалистов по Data Science и дата-инженеров, а также как связать его с Apache Airflow, какую пользу это принесет в задачах обеспечении качества данных. Также разберем кейс совместного использования Apache Airflow и Great Expectations в компании Vimeo и заглянем под...

В этой статье для разработчиков Spark-приложений и дата-инженеров рассмотрим особенности взаимодействия с облачным объектным хранилищем больших данных AWS S3. Как повысить эффективность и ускорить выполнения Spark-заданий на чтение данных из S3: рекомендации Pinterest. Пара советов по работе Apache Spark с AWS S3 Прежде чем перейти к опыту дата-инженеров фотохостинга Pinterest,...
В этой статье для администраторов Greenplum рассмотрим, как настроить систему сетевой защиты Kerberos для этой MPP-СУБД, чтобы контролировать доступ к хранящимся в ней данным с помощью сервера аутентификации. А также рассмотрим основные понятия и термины Kerberos применительно к Greenplum. Что такое Kerberos и зачем это в Greenplum Напомним, Kerberos –...

Сегодня разберем практический вопрос из обучения администраторов кластера Apache Kafka и разработчиков распределенных приложений. Про исключения в Kafka-приложениях: какие они бывают, почему случаются, с какими параметрами конфигурации связаны и что могут сказать о тонкостях потоковой обработки больших данных. Исключения и транзакции в Apache Kafka В ИТ под исключением понимается исключительная...