 1173
1173 
Содержание
В этой статье для разработчиков Spark-приложений и дата-инженеров рассмотрим особенности взаимодействия с облачным объектным хранилищем больших данных AWS S3. Как повысить эффективность и ускорить выполнения Spark-заданий на чтение данных из S3: рекомендации Pinterest.
Пара советов по работе Apache Spark с AWS S3
Прежде чем перейти к опыту дата-инженеров фотохостинга Pinterest, отметим некоторые ключевые особенности AWS S3, о чем мы подробно рассказывали здесь и здесь. Прежде всего, это не файловая система, а объектное хранилище, которое работает только с полными объектами. В частности, операция переименования фактически копирует данные, имеет высокую задержку и взимает плату за каждое выполнение. С конца 2020 года этот облачный сервис обеспечивает стабильную согласованность: завершенная операция сразу видна другим клиентам. Если управление версиями объекта включено, S3 хранит все данные, которые когда-либо хранились под определенным ключом. При замене объекта, создается его новая версия, а предыдущая версия становится «не текущей», но сохраняет все данные. Удаление объекта создает «маркер удаления», в то время как предыдущие данные также будут сохранены в предыдущей версии. Благодаря API доступа к содержимому устаревшей версии, можно вернуться к более раннему состоянию.
Для всех сегментов следует ведение журнала на стороне сервера, чтобы регистрировать каждый запрос, включая ключ объекта, размер данных и время. Также стоит включить инвентаризацию корзины, которая автоматически ежедневно создает список всех имеющихся там объектов. Эти инструменты позволяют детально изучить использование облачного хранилища и затраты на его эксплуатацию, отладить производительность и восстановить данные при их удалении. Можно настроить несколько запросов Spark, которые читают нужные данные, чтобы получить их, когда они понадобятся. При этом рекомендуется избегать выполнения множества мелких операций, включая PUT- и GET-запросы, а также изменение жизненного цикла объекта (версионность). Поэтому, чем крупнее объекты, тем лучше. В частности, для больших файлов в формате Parquet идеальный размер составляет около 1 ТБ. Он удобно обрабатывается Spark и достаточно велик, чтобы затраты на эксплуатацию S3 не имели значения. Для конвейеров приема в реальном времени достаточно 50–100 МБ. Все, что меньше 1 МБ, рекомендуется укрупнить.
Наконец, важно знать и отслеживать задержку S3, т.е. время от начала запроса до первого байта данных, которая может достигать сотен миллисекунд. Например, при чтении 20 МБ данных, задержка может составлять 50% от общего времени запроса. А если это в таблице с тысячей файлов, каждый из которых имеет размер 20 МБ, ее следует сжать, используя внутреннюю фрагментацию. Файлы Parquet состоят из групп строк, которые читаются независимо. По умолчанию процесс записи запускает новую группу после сбора 128 МБ данных в памяти, поэтому размер на диске после сжатия может составлять 10–20 МБ. Поэтому файл размером 1 ТБ с небольшими группами строк не очень хороший вариант: лучше установить для параметра Spark parquet.block.size значение не менее 512 МБ. Впрочем, в файле Parquet не только группы строк читаются независимо, но и каждый столбец данных. Причем Apache Spark читает каждый столбец последовательно. Поэтому, чтобы сэкономить расходы на AWS S3, имеет смысл увеличить размер группы строк и не читать лишние столбцы [1].
А если данные будут загружаться из большого сжатого файла, рекомендуется разделить их на более мелкие файлы примерно равного размера, от 1 МБ до 1 ГБ после сжатия. Для оптимального параллелизма идеальный размер файла после сжатия составляет 1–125 МБ. Количество таких split-файлов стоит задать кратным количеству фрагментов в кластере [2]. Некоторые из этих рекомендаций на практике реализовали дата-инженеры фотохостинга Pinterest, чтобы повысить пропускную способность и эффективность Spark-заданий на чтение данных из S3. Именно это мы рассмотрим далее.
Оптимизация чтения данных из S3: опыт Pinterest
Pinterest ежедневно обрабатывает петабайты данных, хранящихся в Amazon S3. Однажды, проверив показатели наших Spark-заданий MapReduce, дата-инженеры компании заметили скорость этапа Map около 5–7 МБ/с, что на несколько порядков ниже по сравнению с наблюдаемой пропускной способностью типовых команд, таких как COPY (aws s3 cp), где обычными являются скорости около 200+ МБ/с на экземпляре c5.4xlarge в EC2. С учетом модели ценообразования облачного сервиса, если увеличить скорость чтения данных, можно существенно сэкономить. Таким образом, возникла задача оптимизация чтения из S3.
Анализируя проблему низкой пропускной способности в клиенте файловой системы S3A, дата-инженеры Pinterest заметили следующие возможности улучшения в реализации входного потока S3AInputStream:
- многопоточность – когда данные считываются синхронно в одном потоке, задания проводят большую часть времени в ожидании чтения данных по сети;
- избегание ненужных повторных открытий, когда входной поток S3 не доступен для поиска. Split-файлы необходимо закрывать и открывать повторно каждый раз, когда выполняется поиск или возникает ошибка чтения. Чем больше таких файлов, тем больше вероятность их повторного открытия, что увеличивает расходы на AWS S3 и снижает общую пропускную способность.
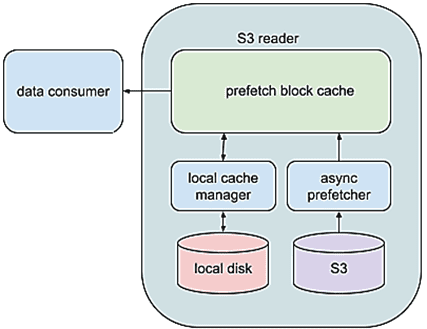
Подход Pinterest основа на следующих предположениях:
- split состоит из блоков фиксированного размера, по умолчанию равным 8 МБ, но его можно изменить;
- каждый блок асинхронно считывается в память до того, как можно получить к нему доступ. Размер кэша предварительной выборки, т.е. количество блоков, настраивается.
- Получить доступ можно только к блоку, который уже был предварительно загружен в память. Это отделяет клиента от ненадежности сети и позволяет иметь дополнительный уровень повторных попыток для повышения общей отказоустойчивости.
- В случае поиска за пределами текущего блока, предварительно выбранные блоки кэшируются в локальной файловой системе.
Помимо этих предположений, также в собственной реализации клиента файловой системы S3, сотрудники Pinterest дополнительно улучшили ее, сделав взаимодействие производителя и потребителя свободным от блокировок. Это увеличило пропускную способность чтения с 20 МБ/с до 269 МБ/с.
Любой потребитель данных, который обрабатывает данные последовательно, к примеру, Mapper, получает преимущество от этого подхода. Пока Mapper обрабатывает извлеченные в конкретный момент данные, то следующие в этой последовательности, уже предварительно выбираются асинхронно. Так данные уже предварительно извлечены к тому моменту, когда Mapper готов к следующему блоку. Так получается больше времени потратить на полезную работу и меньше времени на ожидание данных, что повышает эффективность загрузки ЦП.
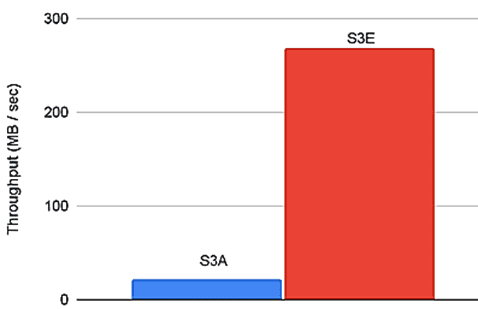
При том, что файлы Parquet требуют непоследовательного доступа, что диктуется их форматом на диске, то первоначальная реализация Pinterest показала снижение производительности, т.к. не использовала локальный кэш. Каждый раз, когда выполнялся поиск за пределами текущего блока, все предварительно выбранные данные отбрасывались. Поэтому было введено локальное кэширование предварительно выбранных данных, что увеличило скорость чтения файлов Parquet в 5 раз. Назвав свою реализацию клиента файловой системы S3E, инженеры Pinterest сравнили ее с S3A на примере небольшого бенчмаркингового теста. Тест состоял из последовательного чтения файла размером 3,5 ГБ и его локальной записи во временный файл, чтобы имитировать операции ввода-вывода во время шага Map задания MapReduce. Тест был запущен на экземпляре c5.9xlarge в EC2. Было измерено общее время, затраченное на чтение файла, и вычислили эффективную пропускную способность каждого метода. Результаты показали 12-кратное увеличение пропускной способности чтения данных из S3: с 21 МБ / с до 269 МБ/с [2].
Узнайте больше про администрирование и использование Apache Spark для разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

