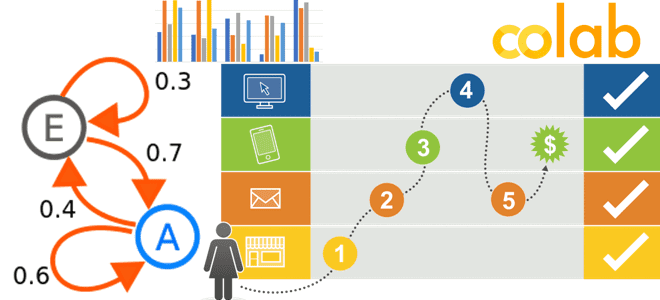
Недавно мы писали, что такое цепь Маркова, как это используется в практических приложениях Data Science и с помощью каких инструментов реализуется этот граф состояний. В продолжение этой полезной для обучения дата-аналитиков темы посмотрим на модели маркетинговой атрибуции как на марковские цепи и разберем пользу этого представления. Практический пример в Google...
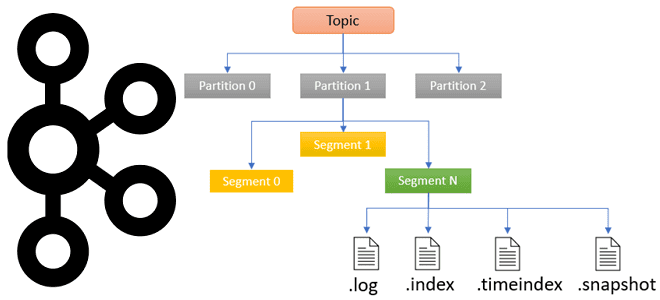
Чтобы сделать наши практические курсы по Apache Kafka еще более полезными, сегодня рассмотрим, в каких файлах хранятся сообщения, смещения и состояния продюсера, а также функции работы с ними для потоковой передачи событий. Средства обработки и хранения данных в Apache Kafka Прежде, чем погружаться в тонкости хранения данных в Apache Kafka,...

Сегодня мы продолжим говорить про Apache Spark Structured Streaming и его применение для обновления данных в таблицах Delta Lake. А также на практических примерах разберем, как выполняются основные операции работы с данными средствами Spark Structured Streaming API. Таблицы в Delta Lake Delta Lake – это уровня хранилища данных с открытым...

В этой статье для обучения дата-инженеров и администраторов кластера Apache AirFlow рассмотрим, как обновить этот ETL-планировщик, используя концепцию сине-зеленого развертывания. Также рассмотрим, с какими ошибками можно столкнуться, выполняя миграцию базы данных метаданных и как их решить. Сине-зеленое развертывание для обновления AirFlow Как и любое программное обеспечение, Apache AirFlow нужно периодически...
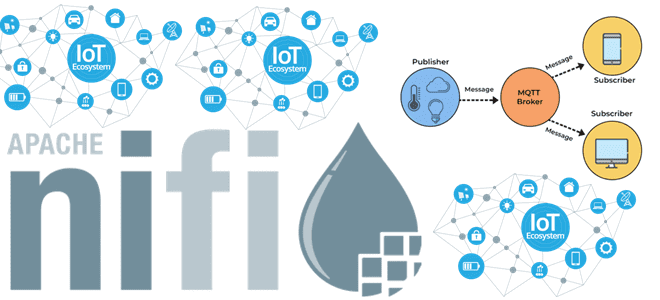
В прошлой статье про обновление Apache NiFi мы писали, что в новой версии 1.18.0 улучшено взаимодействие с протоколом MQTT, который активно используется в системах интернета вещей. Сегодня разберем более подробно, как наладить сбор и публикацию данных в MQTT-топики с помощью процессоров Apache NiFi, а также разберем, что такое брокер HiveMQ....
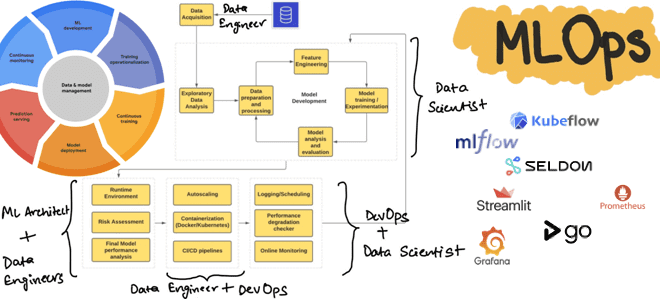
Сегодня рассмотрим, как реализовать полноценный MLOps-цикл, используя свободные инструменты с открытым исходным кодом: MLflow, Kubeflow, Seldon, Streamlit, AirFlow, Git, Prometheus и Grafana. Процессы жизненного цикла ML-систем Концепция MLOps использует проверенные методы DevOps для автоматизации создания, развертывания и мониторинга конвейеров машинного обучения в производственной среде, устраняя рост технического долга в ML-проектах....

Продолжая недавний разговор про Apache Spark Structured Streaming, сегодня рассмотрим, как этот движок потоковой обработки данных помогает дата-инженеру реализовать идемпотентную запись в таблицы Delta Lake, а также выполнить операции слияния и обновления/вставки в помощью метода foreachBatch(). Идемпотентность потоковых приложений Apache Spark Идемпотентность – важное свойство распределенных систем, которое гарантирует, что...

Недавно мы рассматривали тонкости проектирования схем данных в Greenplum. Продолжая разбирать важные для обучения дата-инженеров и архитекторов DWH темы, сегодня поговорим о том, как разделение и распределение данных влияют на скорость выполнения SQL-запросов в этой MPP-СУБД. Распределение данных Напомним, MPP-СУБД Greenplum широко используется в качестве OLAP-системы и корпоративного хранилища данных....

Сегодня рассмотрим, как дата-инженеры маркетплейса Whatnot масштабировали потоковую обработку данных с помощью Apache Kafka, изменив свои ETL-процессы и реализовав на этой распределенной платформе шину событий для анализа пользовательского поведения c ksqlDB и Rockset. Постановка задачи: события пользовательского поведения в Whatnot Whatnot – это маркетплейс, пользователи которого могут покупать и продавать...
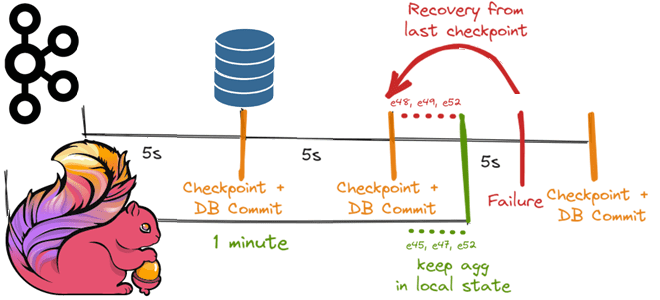
Как Apache Flink реализует строго однократную доставку событий в потовой обработке данных с помощью контрольных точек для записи данных в реляционную базу, используя функцию TwoPhasedCommitSink(), основанную на механизме согласованных snapshot’ов 35-летней давности и Kafka Transaction API. Трудности строго однократной доставки в потоковой обработке данных Распределенная обработка потоков с отслеживанием состояния...