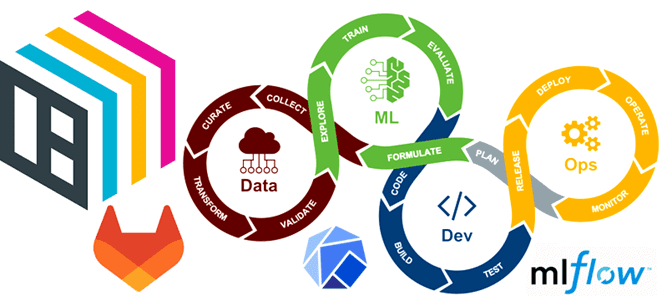
Чтобы сделать наши курсы для DevOps-инженеров и специалистов по Machine Learning еще более полезными, сегодня рассмотрим, как автоматизировать развертывание и обслуживание ML-моделей согласно концепции MLOps с помощью GitLab CI/CD, BentoML, Yatai, MLflow и Kubeflow. BentoML для CI в MLOPS При развертывании ML-модели необходимо учитывать следующие аспекты: как была построена модель...

16 ноября 2022 года вышел 2-ой альфа-релиз Apache Hive 4.0.0. Какие ошибки в нем исправлены и что за новые функции, важные для дата-инженера и администратора кластера Hadoop, появились. А перед этим вспомним основные принципы работы Apache Hive. Принципы работы Apache Hive Apache Hive является популярным инструментом стека SQL-on-Hadoop, позволяя обращаться...

В этой статье для обучения дата-инженеров и администраторов кластера Apache NiFi познакомимся с NiFiKop – оператором, который упрощает запуск потокового ETL-маршрутизатора на платформе контейнерной виртуализации Kubernetes. 4 трудности управления кластером Apache NiFi При том, что Apache NiFI имеет множество достоинств, предоставляя возможности сбора, маршрутизации и обогащения потоков данных из разных...

Сегодня поговорим про качество данных и разберем, что такое Soda Core, как эта платформа позволяет выявлять отсутствующие значения, дубликаты, изменения схемы и проверку актуальности. А также рассмотрим, каким образом это совместимо с Apache AirFlow и что еще есть в самом популярном ETL-планировщике для обеспечения качества и надежности данных. Качество данных...

Мы уже разбирали некоторые советы оптимизации Flink-приложений, связанные с неравномерным распределением данных по вычислительным узлам. Сегодня рассмотрим, как при этом пригодится паттерн MapReduce Combiner, который часто используется в экосистеме Apache Hadoop и вместо него лучше применить Bundle оператор, доступный с версии Flink 1.15. Проблема неравномерного распределения в Big Data вообще...

Недавно мы писали про новинки сентябрьского и октябрьского релизов Greenplum 6.22, а 18 ноября 2022 года вышла новая отладочная версия, которая решает некоторые проблемы с сервером СУБД, обработкой запросов и потоком данных. Разбираемся, что стало лучше в VMware Tanzu Greenplum 6.22.2 с точки зрения администратора кластера и дата-инженера. Новинки и...
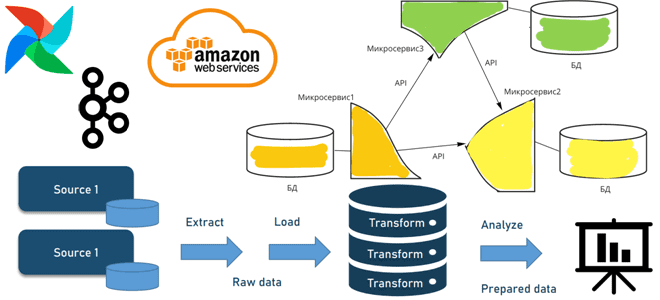
Когда и зачем переходить от пакетной парадигмы обработки к потоковой, как это сделать с помощью микросервисной архитектуры, какие проблемы могут при этом возникнуть и что за решения позволят их избежать. А в качестве примеров инструментальных средств рассмотрим сервисы AWS, Apache AirFlow и Kafka. От пакетов к потокам через микросервисы: архитектура...

Визуализация конвейеров обработки данных особенно важна в потоковой парадигме, поэтому мы часто рассматриваем полезные средства мониторинга для Apache Kafka. Сегодня разберем, что такое Streams Explorer от Bakdata и как это пригодится для дата-инженера. Проекты Bakdata для развертывания и мониторинга приложений Kafka Streams При работе с крупномасштабными потоковыми данными крайне важно...

Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...

Мы уже сравнивали MLflow и Kubeflow, которые позволяют управлять конвейерами машинного обучения. Продолжая эту важную для ML-инженера тему, сегодня рассмотрим 2 других MLOps-инструмента для оркестрации конвейеров Machine Learning: Vertex AI Pipelines и Apache AirFlow. Что такое Vertex AI Pipelines от Google Поскольку цель концепции MLOps в том, чтобы объединить разработку...